
Sistema de almacenamiento de Dell EMC
PowerVault ME4 Series
Manual del propietario
December 2020
Rev. A07

Notas, precauciones y advertencias
NOTA: Una NOTA indica información importante que le ayuda a hacer un mejor uso de su producto.
PRECAUCIÓN: Una PRECAUCIÓN indica la posibilidad de daños en el hardware o la pérdida de datos, y le explica cómo
evitar el problema.
AVISO: Un mensaje de AVISO indica el riesgo de daños materiales, lesiones corporales o incluso la muerte.
© 2018 – 2020 Dell Inc. o sus subsidiarias. Todos los derechos reservados. Dell, EMC y otras marcas comerciales son marcas comerciales de Dell Inc. o sus
filiales. Es posible que otras marcas comerciales sean marcas comerciales de sus respectivos propietarios.

Capítulo 1: Hardware del sistema de almacenamiento.........................................................................5
Localice la etiqueta de servicio............................................................................................................................................ 5
Configuraciones del gabinete...............................................................................................................................................5
Actualización a configuración de controladora doble..................................................................................................6
Extracción del segundo controlador..............................................................................................................................6
Administración del gabinete..................................................................................................................................................6
Operación................................................................................................................................................................................7
Conectar o quitar el bisel frontal de un gabinete de 2U............................................................................................. 9
Variantes de gabinete..........................................................................................................................................................10
Producto principal del gabinete 2U.....................................................................................................................................11
Panel frontal del gabinete de 2U...................................................................................................................................11
Panel posterior del gabinete 2U....................................................................................................................................12
Producto principal del gabinete 5U84............................................................................................................................... 15
Panel frontal del gabinete 5U84...................................................................................................................................16
Panel posterior del gabinete 5U84...............................................................................................................................16
Chasis de gabinete 5U84....................................................................................................................................................20
Cajones de gabinete 5U84........................................................................................................................................... 20
LED del panel de operador (Ops).......................................................................................................................................21
Panel del operador del gabinete 2U............................................................................................................................. 21
Panel del operador del gabinete 5U............................................................................................................................ 22
Módulos de controladora..............................................................................................................................................23
CompactFlash......................................................................................................................................................................28
Paquete supercapacitor................................................................................................................................................29
Falla de controladora cuando solo funciona una controladora.......................................................................................29
Transporte de caché..................................................................................................................................................... 30
Capítulo 2: Solución de problemas...................................................................................................31
Resumen................................................................................................................................................................................31
Metodología de aislamiento de fallas................................................................................................................................. 31
Pasos básicos de metodología de aislamiento de fallas.............................................................................................31
Opciones disponibles para realizar pasos básicos...................................................................................................... 31
Ejecución de pasos básicos.......................................................................................................................................... 32
LED........................................................................................................................................................................................34
LED del gabinete 2U......................................................................................................................................................34
LED del gabinete 5U84................................................................................................................................................. 37
Solución de problemas de gabinetes 2U...........................................................................................................................39
Fallas de PCM................................................................................................................................................................ 40
Control térmico y supervisión térmica........................................................................................................................ 40
Alarma térmica................................................................................................................................................................41
Solución de problemas de gabinetes 5U........................................................................................................................... 41
Consideraciones térmicas.............................................................................................................................................42
Conexiones de puerto de CLI.......................................................................................................................................42
Sensores de temperatura................................................................................................................................................... 42
I/O del host.......................................................................................................................................................................... 42
Tabla de contenido
Tabla de contenido 3

Capítulo 3: Reemplazo y extracción del módulo................................................................................43
Precauciones ante descargas electroestáticas (ESD)....................................................................................................43
Reparación de fallas de hardware......................................................................................................................................44
Actualizaciones de firmware.............................................................................................................................................. 44
Configuración de la actualización de firmware asociado.......................................................................................... 44
Funcionamiento continuo durante el reemplazo..............................................................................................................44
Apagado de los hosts conectados.....................................................................................................................................45
Apagado de un módulo de controladora...........................................................................................................................45
Uso del PowerVault Manager...................................................................................................................................... 45
Mediante la CLI..............................................................................................................................................................45
Verificación de falla de componente.................................................................................................................................46
Las unidades que puede reemplazar el cliente (CRU)....................................................................................................46
Conectar o quitar el bisel frontal de un gabinete de 2U............................................................................................47
Reemplazo de un módulo de portaunidades en un gabinete de 2U........................................................................ 47
Reemplazo de una DDIC en un gabinete de 5U.........................................................................................................52
Reemplazo de un módulo de controladora o IOM en un gabinete de 2U o 5U..................................................... 62
Reemplazo de una fuente de alimentación (PSU) en un gabinete de 5U..............................................................69
Reemplazo de un módulo de enfriamiento con ventilador (FCM) en un gabinete de 5U.....................................71
Reemplazo de un módulo de enfriamiento de alimentación (PCM) en un gabinete de 2U..................................73
Conclusión del proceso de instalación de componentes.......................................................................................... 75
Verificación del funcionamiento de componentes...........................................................................................................75
Uso de LED.....................................................................................................................................................................75
Uso de interfaces de administración........................................................................................................................... 76
Actualizaciones en el PowerVault Manager después de reemplazar un HBA de SAS o FC...................................... 76
Capítulo 4: Eventos y mensajes de evento........................................................................................77
Descripciones de eventos...................................................................................................................................................77
Eventos.................................................................................................................................................................................78
Eventos eliminados............................................................................................................................................................ 152
Eventos enviados como indicaciones a clientes de SMI-S...........................................................................................152
Uso del comando de confianza........................................................................................................................................ 152
Apéndice A: Conexión del puerto de la CLI mediante un cable en serie.............................................. 154
Conexión del minidispositivo USB....................................................................................................................................155
Controladores de Microsoft Windows...................................................................................................................... 156
Controladores de Linux............................................................................................................................................... 156
Apéndice B: Especificaciones técnicas...........................................................................................158
Apéndice C: Estándares y normativas............................................................................................ 163
4
Tabla de contenido

Hardware del sistema de almacenamiento
En este capítulo se describen los componentes de front-end y back-end para los gabinetes de ME4 Series.
Ciertos módulos dentro del gabinete se pueden reemplazar, como se describe en Reemplazo y extracción del módulo en la página 43. A
continuación, se definen los módulos y otros componentes que se pueden reemplazar:
● CRU: unidad que puede reemplazar el cliente
● FRU: unidad reemplazable in situ (requiere experiencia en servicio)
Los términos CRU y FRU se utilizan en este documento.
Temas:
• Localice la etiqueta de servicio
• Configuraciones del gabinete
• Administración del gabinete
• Operación
• Variantes de gabinete
• Producto principal del gabinete 2U
• Producto principal del gabinete 5U84
• Chasis de gabinete 5U84
• LED del panel de operador (Ops)
• CompactFlash
• Falla de controladora cuando solo funciona una controladora
Localice la etiqueta de servicio
El sistema de almacenamiento de ME4 Series se identifica mediante un código de servicio rápido y una etiqueta de servicio única.
La etiqueta de servicio y el código de servicio rápido se encuentran en la parte frontal del sistema cuando tira de la etiqueta de
información. De manera alternativa, la información puede estar en una etiqueta adhesiva en la parte posterior del chasis del sistema de
almacenamiento. Esta información se utiliza para dirigir las llamadas de soporte al personal correspondiente.
NOTA:
Localizador de recursos rápido (QRL)
● El código QRL contiene información única del sistema. Se encuentra en la etiqueta de información y en el documento de
Configuración del sistema de almacenamiento Dell EMC PowerVault ME4 Series enviado con el gabinete ME4 Series.
● Escanee el QRL para tener acceso inmediato a la información del sistema, mediante su teléfono inteligente o tableta.
Configuraciones del gabinete
El sistema de almacenamiento es compatible con tres configuraciones de gabinete de la controladora.
● Gabinete de controladora 2U (espacio en rack, 2U12): consulte Sistema de gabinete 2U12: orientación frontal en la página 7 y
Sistema de gabinete 2U12: orientación posterior en la página 8: contiene hasta 12 unidades de disco de factor de forma de
3.5 pulgadas y perfil bajo (1 pulgada de altura) en orientación horizontal.
● Gabinete de controladora 2U (espacio en rack, 2U24): consulte Sistema de gabinete 2U24: orientación frontal en la página 8 y
Sistema de gabinete 2U24: orientación posterior en la página 8: contiene hasta 24 unidades de disco de factor de forma de
2.5 pulgadas y perfil bajo (5/8 de pulgada de altura) en orientación vertical.
● Gabinete de controladora 5U (espacio en rack, 5U84): consulte Sistema de gabinete 5U84: orientación frontal en la página 9 y
Sistema de gabinete 5U84: orientación posterior en la página 9: contiene hasta 84 unidades de disco de factor de forma de
3.5 pulgadas y perfil bajo (1 pulgada de altura) en orientación vertical dentro del cajón de disco. Dos cajones apilados verticalmente
sostienen 42 discos cada uno. Si se utilizan, los discos de 2.5 pulgadas requieren adaptadores de 3.5 pulgadas.
Los mismos factores de forma del chasis se utilizan para los gabinetes de expansión compatibles, pero con módulos de I/O en lugar de
módulos de controladora.
1
Hardware del sistema de almacenamiento 5

Los gabinetes 2U12 y 2U24 son compatibles con configuraciones de módulo de controladora doble o único, pero el gabinete 5U84 solo es
compatible con una configuración de módulo de controladora doble. Si una controladora asociada falla, el sistema de almacenamiento
realizará una conmutación por errores y se ejecutará en un solo módulo de controladora hasta restaurar la redundancia. Para gabinetes 2U,
se debe instalar un módulo de controladora o un módulo de relleno en la ranura B para garantizar un flujo de aire suficiente por el gabinete
durante el funcionamiento. Para gabinetes 5U84, se debe instalar un módulo de controladora en ambas ranuras, A y B.
Actualización a configuración de controladora doble
Puede agregar un segundo módulo de controladora en la ranura B para actualizar una configuración de módulo de controladora única de
2U.
El módulo de controladora B se puede agregar mientras el módulo de controladora A procesa requisitos de I/O de host. Sin embargo,
recomendamos programar los cambios en la configuración durante una ventana de mantenimiento sin actividad de I/O o con poca
actividad.
Los datos no se verán afectados cuando el módulo de controladora B se inserte en el gabinete, pero recomendamos hacer un respaldo
completo de los datos antes de continuar.
NOTA:
● Cuando se inserta un módulo de controladora B, la configuración de redundancia cambia automáticamente de Single
Controller a Active-Active ULP (presentación de LUN unificada). No es necesario realizar cambios manualmente.
● Si la PFU (actualización de firmware de socio) está habilitada, cuando agregue el módulo de controladora B, el sistema actualiza el
firmware o el segundo módulo de controladora automáticamente para coincidir con la versión de firmware en el primer módulo de
controladora.
1. Escriba el siguiente comando de la CLI para confirmar que la redundancia esté configurada como Single Controller Mode:
show advanced-settings
Este paso confirmará que el módulo de controladora A no informe que el módulo de controladora B no se encuentra.
2. Quite la controladora de relleno de la ranura B.
3. Sujete el módulo de controladora con ambas manos y, con el pestillo en la posición abierta, oriente el módulo y alinéelo para la inserción
en la ranura B.
4. Asegúrese de que el módulo de controladora esté nivelado y deslícelo hacia el interior del gabinete tanto como sea posible.
Un módulo de controladora que solo esté parcialmente asentado no permitirá el rendimiento óptimo del gabinete de controladora.
Verifique que el módulo de controladora esté asentado completamente antes de continuar.
5. Cierre el pestillo manualmente para fijar el módulo en su posición.
Debería oír un clic cuando el asa del pestillo se enganche y fije el módulo de controladora al conector en la parte posterior del midplane.
6. Conecte los cables.
7. Asigne los puertos de host del módulo de controladora B.
Extracción del segundo controlador
Para extraer el módulo B de la controladora y volver a una configuración de una única controladora:
1. Apague el módulo B de la controladora.
2. Extraiga el módulo de la controladora del gabinete.
3. Escriba el siguiente comando de la CLI para cambiar la configuración de redundancia a Single Controller Mode:
#set advanced-settings single-controller
4. Instale una controladora de relleno en la ranura B.
Administración del gabinete
El gabinete cumple con los requisitos mecánicos y eléctricos de la especificación de la bahía de puente de almacenamiento (SBB)
versión 2.1.
6
Hardware del sistema de almacenamiento

Los módulos de SBB administran el gabinete activamente. Cada módulo tiene un expansor de SAS con su propio procesador de gabinete
de almacenamiento (SEP) que proporciona un SES de destino para que un host realice una interfaz, a través del estándar de SES
(servicios de gabinete de SCSI) de ANSI. Si falla uno de estos módulos, el otro continúa funcionando.
Interfaces de administración
Una vez finalizada la instalación del hardware, acceda a la interfaz de administración basada en la web del módulo de controladora
(PowerVault Manager) para configurar, supervisar y administrar el sistema de almacenamiento. El módulo de controladora también
proporciona una interfaz de la línea de comandos (CLI) para tener compatibilidad con la entrada y los scripts de línea de comandos. Para
obtener más detalles, consulte la Guía de la CLI del sistema de almacenamiento Dell EMC PowerVault ME4 Series del sistema.
Operación
PRECAUCIÓN: El uso del gabinete con cualquier módulo de CRU faltante interrumpirá el flujo de aire, y el gabinete no
tendrá suficiente enfriamiento. Es esencial que todas las ranuras sujeten módulos antes de usar el sistema de gabinete.
Las ranuras de unidad vacías (compartimientos) en gabinetes 2U deben tener módulos de portaunidades de relleno.
● Lea la etiqueta de precaución de la bahía del módulo que desea reemplazar.
● Reemplace un módulo de enfriamiento de alimentación (PCM) defectuoso con un PCM que funcione correctamente en menos de
24 horas. No quite un PCM defectuoso a menos que tenga un modelo de repuesto del tipo adecuado listo para insertar.
● Antes de quitar/reemplazar un PCM o una fuente de alimentación (PSU), desconecte la fuente de alimentación del módulo que desea
reemplazar.
● Lea la etiqueta de advertencia de voltaje peligroso fija a los módulos de enfriamiento de alimentación.
PRECAUCIÓN: Gabinetes 5U84 únicamente
● Para evitar que el sistema se vuelque, las cerraduras internas del cajón evitan que los usuarios abran ambos cajones al mismo tiempo.
No intente abrir un cajón a la fuerza cuando el otro cajón del gabinete ya está abierto. En un rack con más de un gabinete 5U84, no
abra más de un cajón por rack a la vez.
● Lea la etiqueta de superficie caliente fija al cajón. Las temperaturas de funcionamiento dentro de cajones de gabinete pueden alcanzar
los 60 ºC. Tenga cuidado cuando abra cajones y quite DDIC.
● Debido a la acústica del producto, debe usar protección para los oídos durante una exposición prolongada al producto en
funcionamiento.
● No debe utilizar los cajones abiertos para sostener cualquier otro objeto o equipo.
NOTA: Consulte Variantes de gabinete en la página 10 para obtener detalles sobre varias opciones de gabinete.
Ilustración 1. Sistema de gabinete 2U12: orientación frontal
Hardware del sistema de almacenamiento
7

Ilustración 2. Sistema de gabinete 2U12: orientación posterior
El gabinete de controladora 2U12 en Sistema de gabinete 2U12: orientación posterior en la página 8 está equipado con 2 controladoras (se
muestra el modelo FC/iSCSI de 4 puertos).
Ilustración 3. Sistema de gabinete 2U24: orientación frontal
Ilustración 4. Sistema de gabinete 2U24: orientación posterior
El gabinete de controladora 2U24 está equipado con controladoras dobles (se muestra el modelo de SAS de 4 puertos).
8
Hardware del sistema de almacenamiento

Ilustración 5. Sistema de gabinete 5U84: orientación frontal
Ilustración 6. Sistema de gabinete 5U84: orientación posterior
El gabinete de controladora 5U84 está equipado con controladoras dobles (se muestra el modelo FC/iSCSI de 4 puertos).
Conectar o quitar el bisel frontal de un gabinete de 2U
En la siguiente ilustración, se muestra una vista parcial de un gabinete de 2U12:
Ilustración 7. Conexión o extracción del bisel frontal del gabinete de 2U
Para conectar el bisel frontal al gabinete de 2U, realice lo siguiente:
1. Localice el bisel y, mientras lo sostiene con las manos, póngalo de frente al panel frontal del gabinete de 2U12 o 2U24.
2. Enganche el extremo derecho del bisel en la cubierta de la orejeta derecha del sistema de almacenamiento.
3. Introduzca el extremo izquierdo del bisel en la ranura de fijación hasta que el pestillo de liberación encaje en su lugar.
4. Fije el bisel con la cerradura, como se muestra en Conexión o extracción del bisel frontal del gabinete 2U.
Hardware del sistema de almacenamiento
9

Para quitar el bisel del gabinete 2U, invierta el orden de los pasos anteriores.
NOTA: Consulte Variantes de gabinete para obtener detalles sobre varias opciones de gabinete .
Variantes de gabinete
El chasis 2U se puede configurar como un gabinete de controladora ME4012/ME4024 o un gabinete de expansión ME412/ME424, como
se muestra en Variantes del gabinete 2U12 y Variantes del gabinete 2U24. El chasis 5U se puede configurar como un gabinete de
controladora ME4084 o un gabinete de expansión ME484, como se muestra en Variantes del gabinete 5U84.
NOTA:
Los productos principales 2U y 5U (incluyendo las CRU y los componentes clave) se describen en las secciones a continuación.
Aunque muchas CRU varían entre los factores de forma, los módulos de controladora e IOM son comunes a los chasis 2U12, 2U24 y
5U84. Los módulos de controladora e IOM se introducen en el Producto principal del gabinete 2U y tienen referencias cruzadas del
Producto principal del gabinete 5U84.
2U12
Los gabinetes 2U12 están formados por 12 unidades de disco LFF (factor de forma grande) y 12 unidades de disco HFF (factor de forma
híbrido).
Tabla 1. Variantes de gabinete 2U12
Producto Configuración PCM
1
Módulos de controladora e IOM
2, 3
ME4012 Estación de acoplamiento directo SAS LFF y
12 Gb/s
2 2
Estación de acoplamiento directo SAS LFF y
12 Gb/s
2 1
ME412 Estación de acoplamiento directo SAS LFF y
12 Gb/s
2 2
1
Los PCM redundantes deben ser módulos compatibles del mismo tipo (ambos de CA).
2
Los módulos de controladora compatibles incluyen FC/iSCSI de 4 puertos, miniSAS HD de 4 puertos e iSCSI 10Gbase-T de 4 puertos.
Los IOM compatibles se usan en gabinetes de expansión para agregar almacenamiento.
3
En configuraciones de módulo de controladora única, el módulo de controladora se instala en la ranura A y se instala una controladora de
relleno en la ranura B.
2U24
Los gabinetes 2U24 están formados por 24 unidades de disco SFF (factor de forma pequeño).
Tabla 2. Variantes de gabinete 2U24
Producto Configuración PCM
1
Módulos de controladora e IOM
2, 3
ME4024 Estación de acoplamiento directo SAS SFF
y 12 Gb/s
2 2
Estación de acoplamiento directo SAS SFF
y 12 Gb/s
2 1
ME424 Estación de acoplamiento directo SAS SFF
y 12 Gb/s
2 2
1
Los PCM redundantes deben ser módulos compatibles del mismo tipo (ambos de CA).
2
Los módulos de controladora compatibles incluyen FC/iSCSI de 4 puertos, miniSAS HD de 4 puertos e iSCSI 10Gbase-T de 4 puertos.
Los IOM compatibles se usan en gabinetes de expansión para agregar almacenamiento.
10
Hardware del sistema de almacenamiento

3
En configuraciones de módulo de controladora única, el módulo de controladora se instala en la ranura A y se instala una controladora de
relleno en la ranura B.
5U84
Los gabinetes 5U84 están formados de 84 unidades de disco LFF o SFF colocadas en dos cajones de 42 ranuras apilados verticalmente.
Tabla 3. Variantes de gabinete 5U84
Producto Configuración PSU
1
FCM
2
Módulos de controladora e IOM
3
ME4084 Estación de acoplamiento directo SAS
SFF y 12 Gb/s
2 5 2
ME484 Estación de acoplamiento directo SAS
SFF y 12 Gb/s
2 5 2
1
Los PCM redundantes deben ser módulos compatibles del mismo tipo (ambos de CA).
2
El módulo de control del ventilador (FCM) es una CRU independiente (no integrada en un PCM).
3
Los módulos de controladora compatibles incluyen FC/iSCSI de 4 puertos, miniSAS HD de 4 puertos e iSCSI 10Gbase-T de 4 puertos.
Los IOM compatibles se usan en gabinetes de expansión para agregar almacenamiento.
Producto principal del gabinete 2U
El concepto de diseño se basa en un subsistema de gabinete junto con un conjunto de módulos plug-in.
Las siguientes figuras muestran las ubicaciones de los componentes, junto con la indexación de ranuras de CRU, en relación con los
paneles frontal y posterior del gabinete 2U.
Panel frontal del gabinete de 2U
Los números enteros en los discos indican la secuencia de numeración de la ranura de la unidad.
Ilustración 8. Sistema de gabinete 2U12: componentes del panel frontal
Ilustración 9. Sistema de gabinete 2U24: componentes del panel frontal
NOTA:
● Para obtener más información sobre los LED del panel frontal del gabinete, consulte Panel del operador del gabinete 2U en la
página 21.
● Para obtener información sobre los LED del disco para los módulos de disco LFF y SFF, consulte Uso de LED en la página 75 .
● Para obtener información sobre el bisel frontal del gabinete 2U opcional, consulte Conexión o extracción del bisel frontal del
gabinete de 2U en la página 9.
Hardware del sistema de almacenamiento 11

Panel posterior del gabinete 2U
Los indicadores alfabéticos en módulos de controladora o IOM y los designadores numéricos en PCM indican la secuencia de ranuras para
los módulos usados en gabinetes 2U. Los módulos de controladora, IOM y PCM están disponibles como CRU. Los RBOD de ME4 Series
utilizan módulos de controladora de 4 puertos. Estos RBOD son compatibles con los EBOD de ME412/ME424/ME484 para agregar
almacenamiento opcional.
Ilustración 10. Gabinete de controladora 2U: componentes del panel posterior (FC/iSCSI de 4 puertos)
1. Ranura para módulo de enfriamiento de alimentación 0 2. Ranura para módulo de enfriamiento de alimentación 1
3. Ranura de módulo de controladora A 4. Ranura de módulo de controladora B
Ilustración 11. Gabinete de controladora 2U: componentes del panel posterior (iSCSI 10Gbase-T de 4 puertos)
1.
Ranura para módulo de enfriamiento de alimentación 0 2. Ranura para módulo de enfriamiento de alimentación 1
3. Ranura de módulo de controladora A 4. Ranura de módulo de controladora B
Ilustración 12. Gabinete de controladora 2U: componentes del panel posterior (SAS de 4 puertos)
1.
Ranura para módulo de enfriamiento de alimentación 0 2. Ranura para módulo de enfriamiento de alimentación 1
3. Ranura de módulo de controladora A 4. Ranura de módulo de controladora B
NOTA: En las ilustraciones anteriores, se muestran configuraciones de módulo de controladora doble. De manera alternativa, puede
configurar el gabinete de controladora 2U con un módulo de controladora único. En configuraciones de módulo de controladora único,
el módulo se instala en la ranura A y se instala una placa de relleno en la ranura B.
Ilustración 13. Gabinete de expansión 2U: componentes del panel posterior
1.
Ranura para módulo de enfriamiento de alimentación 0 2. Ranura para módulo de enfriamiento de alimentación 1
3. Ranura de IOM A 4. Ranura de IOM B
12 Hardware del sistema de almacenamiento

Componentes del panel posterior 2U
En esta sección, se describe el módulo de controladora, el IOM del gabinete de expansión y los componentes del módulo de enfriamiento
de alimentación.
Módulo de controladora
La ranura superior para sujetar módulos de controladora se designa como A y la ranura inferior como B. Los detalles de la placa frontal de
los módulos de controladora muestran los módulos alineados para su uso en la ranura A. En esta orientación, el pestillo del módulo de
controladora aparece en la parte inferior del módulo en posición cerrada/bloqueada. En las ilustraciones a continuación, se identifican los
puertos en módulos de controladora. Consulte LED del módulo de controladora de 12 Gb/s en la página 24 para identificar los LED.
Los puertos de la controladora de red convergente (CNC) en el módulo de controladora FC/iSCSI de 4 puertos se puede configurar con
SFP FC de 16 Gb/s o SFP iSCSI de 10 GbE.
Ilustración 14. Detalles del módulo de controladora de FC/iSCSI de 4 puertos
1.
Puerto de SAS de expansión de back-end 2. Puerto Ethernet utilizado por las interfaces de administración
3. Puerto serial USB (CLI) 4. Puerto serial de 3,5 mm (CLI)
5. Puertos serie de 3,5 mm (solo de servicio) 6. Restablecer
7. Puertos de CNC (puertos 3, 2, 1, 0)
En la ilustración a continuación, se muestran los puertos de interfaz de host 10Gbase-T de iSCSI que se envían configurados con
conectores externos preinstalados.
Ilustración 15. Detalles del módulo de controladora 10Gbase-T de iSCSI de 4 puertos
1.
Puerto de SAS de expansión de back-end 2. Puerto Ethernet utilizado por las interfaces de administración
3. Puerto serial USB (CLI) 4. Puerto serial de 3,5 mm (CLI)
5. Puertos serie de 3,5 mm (solo de servicio) 6. Puertos 10Gbase-T (puertos 3, 2, 1, 0)
En la ilustración a continuación, se muestran los puertos de interfaz de host de SAS que se envían configurados con conectores externos
de miniSAS HD de 12 Gb/s (SFF-8644).
Hardware del sistema de almacenamiento
13

Ilustración 16. Detalles del módulo de controladora miniSAS HD de 4 puertos
1. Puerto de SAS de expansión de back-end 2. Puerto Ethernet utilizado por las interfaces de administración
3. Puerto serial USB (CLI) 4. Puerto serial de 3,5 mm (CLI)
5. Puertos serie de 3,5 mm (solo de servicio) 6. Botón de restablecimiento
7. Puertos de SAS (puertos 3, 2, 1, 0)
IOM del gabinete de expansión
En la ilustración a continuación, se muestra el IOM que se utiliza en gabinetes de expansión compatibles para agregar almacenamiento. Los
puertos A/B/C se envían configurados con conectores externos miniSAS HD de 12 Gb/s (SFF-8644).
Ilustración 17. Detalle del IOM: ME412/ME424/ME484
1.
Puerto serial de 3,5 mm (solo de servicio) 2. Puertos de expansión SAS
3. Puerto de expansión de SAS B (deshabilitado) 4. Puerto de Ethernet (deshabilitado)
NOTA: Para configuraciones RBOD/EBOD:
● Cuando el IOM que se muestra en Detalle del IOM: ME412/ME424/ME484 en la página 14 se utiliza con módulos de controladora
de ME4 Series para agregar almacenamiento, el firmware deshabilita el puerto B etiquetado para expansión de miniSAS HD
intermedia.
● El puerto de Ethernet en el IOM no se utiliza en configuraciones de gabinete de expansión/controladora y está deshabilitado.
Módulo de enfriamiento de alimentación
En la siguiente ilustración, se muestra el módulo de enfriamiento de alimentación (PCM) que se utiliza en gabinetes de controladora y
gabinetes de expansión opcionales. El PCM incluye ventiladores de enfriamiento integrados. En el ejemplo, se muestra un PCM orientado
para su uso en la ranura de PCM izquierda del panel posterior del gabinete.
14
Hardware del sistema de almacenamiento

Ilustración 18. Módulo de enfriamiento de alimentación (PCM)
1. LED de buen estado del PCM (verde) 2. LED de falla de CA (ámbar/ámbar parpadeante)
3. LED de falla del ventilador (ámbar/ámbar parpadeante) 4. LED de falla de CC (ámbar/ámbar parpadeante)
5. Interruptor de encendido/apagado 6. Conector de alimentación
7. Pestillo de liberación
Comportamiento de LED:
● Si alguno de los LED del PCM se ilumina en color ámbar, se produjo una falla o una condición de falla del módulo.
● Para obtener una descripción detallada del comportamiento de LED de PCM, consulte LED del gabinete 2U en la página 34.
Producto principal del gabinete 5U84
Gabinete 5U84: componentes del panel frontal en la página 16 y Sistema de gabinete 5U84: plano del cajón accedido desde el panel
frontal en la página 16 se muestran las ubicaciones de los componentes, junto con la indexación de ranuras de CRU, en relación con el
panel frontal del gabinete 5U84 con cajones y el panel posterior.
El 5U84 admite hasta 84 módulos DDIC ocupados dentro de dos cajones (42 DDIC por cajón; 14 DDIC por fila).
NOTA:
● El 5U84 no se envía con DDIC instalados. Los DDIC se envían en un contenedor separado y se deben instalar en los cajones del
gabinete durante la instalación y la configuración del producto.
● Para garantizar una circulación y un enfriamiento suficientes en todo el gabinete, todas las ranuras PSU, las ranuras del módulo de
enfriamiento y las ranuras IOM deben contener una CRU en funcionamiento. No reemplace una CRU defectuosa hasta que el
reemplazo esté disponible y en mano.
Hardware del sistema de almacenamiento 15

Panel frontal del gabinete 5U84
Ilustración 19. Gabinete 5U84: componentes del panel frontal
1. Cajón del gabinete 5U84 (ranura 0 = cajón superior)
2. Cajón del gabinete 5U84 (ranura 1 = cajón inferior)
En la ilustración, se muestra un plano de un cajón de gabinete accesible desde el panel frontal del gabinete. Los gráficos conceptuales se
simplifican para tener una mayor claridad.
NOTA: Consulte LED del DDIC del gabinete 5U84 en la página 38 para ver el comportamiento del LED de DDIC 5U84 (discos LFF).
Ilustración 20. Sistema de gabinete 5U84: plano del cajón accedido desde el panel frontal
1. Panel frontal del cajón (se muestra como un borde en el plano)
2. Dirección en la ranura del cajón de gabinete (ranura 0 o 1)
Panel posterior del gabinete 5U84
Los indicadores alfabéticos en módulos de controladora e IOM y los designadores numéricos en las PSU (fuente de alimentación) y los
FCM (módulos de control del ventilador) indican la secuencia de ranuras para módulos utilizados en gabinetes 5U84. Los módulos de
controladora, IOM, PSU y FCM están disponibles como CRU.
16
Hardware del sistema de almacenamiento

Ilustración 21. Gabinete de controladora 5U84: componentes del panel posterior (FC/iSCSI de 4 puertos)
1. Ranura de módulo de controladora A 2. Ranura de módulo de controladora B
3. Ranura de FCM 0 4. Ranura de FCM 1
5. Ranura de FCM 2 6. Ranura de FCM 3
7. Ranura de FCM 4 8. Ranura de PSU 0
9. Ranura de PSU 1
Ilustración 22. Gabinete de controladora 5U84: componentes del panel posterior (SAS de 4 puertos)
1.
Ranura de módulo de controladora A 2. Ranura de módulo de controladora B
3. Ranura de FCM 0 4. Ranura de FCM 1
5. Ranura de FCM 2 6. Ranura de FCM 3
7. Ranura de FCM 4 8. Ranura de PSU 0
9. Ranura de PSU 1
Hardware del sistema de almacenamiento 17

Ilustración 23. Gabinete de controladora 5U84: componentes del panel posterior (iSCSI 10Gbase-T de 4 puertos)
1. Ranura de módulo de controladora A 2. Ranura de módulo de controladora B
3. Ranura de FCM 0 4. Ranura de FCM 1
5. Ranura de FCM 2 6. Ranura de FCM 3
7. Ranura de FCM 4 8. Ranura de PSU 0
9. Ranura de PSU 1
Ilustración 24. Gabinete de expansión 5U84: componentes del panel posterior
1.
Ranura de IOM A 2. Ranura de IOM B
3. Ranura de FCM 0 4. Ranura de FCM 1
5. Ranura de FCM 2 6. Ranura de FCM 3
7. Ranura de FCM 4 8. Ranura de PSU 0
9. Ranura de PSU 1
NOTA: Los gabinetes de controladora 5U84 son compatibles con la configuración de módulo de controladora doble únicamente. Si un
módulo de controladora asociada falla, la controladora realizará una conmutación por errores y se ejecutará en un solo módulo de
controladora hasta restaurar la redundancia. Ambas ranuras de módulo de controladora deben estar ocupadas para garantizar un flujo
de aire suficiente a la controladora durante el funcionamiento.
Componentes del panel posterior 5U84
En esta sección, se describen el módulo de enfriamiento con ventilador, el módulo de fuente de alimentación, el módulo de expansión y los
módulos de controladora del panel posterior.
18
Hardware del sistema de almacenamiento

Módulos de controladora
El gabinete de controladora 5U84 utiliza los mismos módulos de controladora que los gabinetes 2U12 y 2U24.
Módulo de expansión
El gabinete de expansión 5U84 utiliza los mismos IOM que los gabinetes 2U12 y 2U24.
Módulo de fuente de alimentación
En la ilustración, se muestra la fuente de alimentación que se utiliza en gabinetes de controladora 5U y gabinetes de expansión 5U84
opcionales.
Ilustración 25. Fuente de alimentación (PSU)
1.
Pestillo de liberación del módulo 2. asa
3. LED de error de la PSU (ámbar/ámbar parpadeante) 4. LED de falla de CA (ámbar/ámbar parpadeante)
5. LED de alimentación en buen estado (verde) 6. PowerConnect
7. Interruptor de alimentación
Comportamiento de LED:
● Si alguno de los LED de la PSU se ilumina en color ámbar, se produjo una falla o una condición de falla del módulo.
● Para obtener una descripción detallada de los LED de la PSU, consulte Estados del LED del FCM en la página 37.
Los gabinetes 5U84 usan módulos de CRU independientes para la fuente de alimentación y la circulación/el enfriamiento, respectivamente.
En Fuente de alimentación (PSU) en la página 19 se muestra el módulo de fuente de alimentación, que proporciona al gabinete conexión de
alimentación y un interruptor de alimentación. En Módulo de enfriamiento con ventilador (FCM) en la página 19 se muestra el módulo de
enfriamiento con ventilador utilizado en gabinetes 5U84. El FCM es más pequeño que el PCM, y cinco de ellos se utilizan con el gabinete
5U para proporcionar suficiente flujo de aire a través del gabinete.
Módulo de enfriamiento con ventilador
En la ilustración a continuación, se muestra el módulo de enfriamiento con ventilador (FCM) que se utiliza en gabinetes de controladora 5U
y gabinetes de expansión 5U opcionales.
Ilustración 26. Módulo de enfriamiento con ventilador (FCM)
1.
Pestillo de liberación del módulo 2. asa
Hardware del sistema de almacenamiento 19

3. LED de módulo en buen estado (verde) 4. LED de error del ventilador (ámbar/ámbar parpadeante)
Comportamiento de LED:
● Si alguno de los LED del FCM se ilumina en color ámbar, se produjo una falla o una condición de falla del módulo.
● Para obtener una descripción detallada de los LED del FCM, consulte LED del FCM del gabinete 5U84 en la página 37.
Chasis de gabinete 5U84
El gabinete 5U84 tiene las siguientes características:
● Chasis 5U84 configurado con hasta 84 discos de LFF en DDIC. Consulte Sistema de gabinete 5U84: plano del cajón accedido desde el
panel frontal en la página 16.
● Chasis 5U84 configurados con discos de SFF en adaptador de portaunidades híbrido de 2,5 a 3,5 pulgadas.
● Chasis 5U84 vacío con midplane, sistema de ejecución de módulo y cajones.
El chasis tiene un montaje en rack de 19 pulgadas que permite instalarlo en racks de 19 pulgadas estándares y utiliza cinco unidades de EIA
de espacio en rack (8,75 pulgadas).
En la parte frontal del gabinete, se pueden abrir y cerrar dos cajones. Cada cajón proporciona acceso a 42 ranuras para módulos de unidad
de disco en portaunidades (DDIC). Las DDIC se montan superiormente en los cajones, como se muestra en Sistema de gabinete 5U84:
plano del cajón accedido desde el panel frontal en la página 16. La parte frontal del gabinete también tiene LED de estado de gabinete y
LED de estado/actividad de cajón.
La parte posterior del gabinete proporciona acceso a las CRU del panel posterior:
● Dos módulos de controladora o IOM
● Dos unidades de suministro de energía
● Cinco FCM
Cajones de gabinete 5U84
Cada cajón de gabinete contiene 42 ranuras, cada una de las cuales puede aceptar un DDIC único con una unidad de disco LFF de
3.5 pulgadas o una unidad de disco SFF de 2.5 pulgadas con un adaptador
Abrir un cajón no interrumpe el funcionamiento del sistema de almacenamiento, y los DDIC se pueden intercambiar en activo cuando el
gabinete está en funcionamiento. Sin embargo, los cajones no se deben dejar abiertos durante más de dos minutos o el flujo de aire y el
enfriamiento se verán afectados.
NOTA:
Durante el funcionamiento normal, los cajones deben estar cerrados para asegurar un flujo de aire y un enfriamiento
adecuados dentro del gabinete.
Un cajón completamente abierto está diseñado para sostener su propio peso más el peso de los DDIC instalados.
PRECAUCIÓN:
Los sideplanes de los cajones del gabinete no son intercambiables en caliente y no los puede reparar el
cliente.
Características de seguridad
● Para evitar que el rack se caiga, deslice un solo gabinete hacia afuera del rack a la vez.
● El cajón encaja en su lugar cuando está completamente abierto y extendido. Para reducir el riesgo de pellizcarse los dedos, deberá
soltar dos pestillos antes de poder volver a empujar el cajón en la ranura del gabinete.
Se pueden girar ambas cerraduras contra alteraciones en el sentido de las agujas del reloj mediante un destornillador con punta Torx T20
(incluida en su envío) para bloquear cada cajón. Las cerraduras contra alteraciones están colocadas simétricamente en los laterales
izquierdo y derecho del bisel del cajón. Dos paneles de LED ubicados junto a los bolsillos de tiro en los laterales izquierdo y derecho del
cajón pueden monitorear los LED de actividad y estado del cajón.
20
Hardware del sistema de almacenamiento

Ilustración 27. Detalles del bisel del cajón
1. Lado izquierdo 2. Lado derecho
3. Cerradura contra alteraciones 4. Sideplane en buen estado/buena alimentación
5. Falla de cajón 6. Falla lógica
7. Falla de cable 8. Actividad del cajón
9. Asa de tiro del cajón
NOTA: Para obtener descripciones del comportamiento de los LED de cajón, consulte Estados del LED del cajón en la página 38.
LED del panel de operador (Ops)
Cada gabinete de ME4 Series tiene un panel de operador (Ops) ubicado en el flanco de la orejeta izquierda del chasis. En esta sección, se
describe el panel del operador para gabinetes 2U y 5U.
Panel del operador del gabinete 2U
La parte frontal del gabinete tiene un panel del operador que se encuentra en el flanco de la orejeta izquierda del chasis de 2U. El panel del
operador es una parte integral del chasis del gabinete, pero no se puede reemplazar en el sitio.
Ilustración 28. LED: panel del operador; panel frontal del gabinete 2U
Tabla 4. Funciones del panel del operador
No Indicator Estado
1 Alimentación del sistema
● Luz verde fija: al menos un PCM está proporcionando alimentación
● Apagado: el sistema no funciona, independientemente de la CA presente
2 Estado/condición
● Luz azul fija: el sistema está encendido y la controladora está lista
● Azul parpadeante (2 Hz): el gabinete de administración está ocupado
● Luz ámbar fija: falla del módulo presente
● Ámbar parpadeante: falla lógica (2 segundos encendido, 1 segundo apagado)
Hardware del sistema de almacenamiento 21

Tabla 4. Funciones del panel del operador (continuación)
No Indicator Estado
3 Pantalla de identificación de la unidad
(UID)
Verde (pantalla de siete segmentos; secuencia de gabinete)
4 Identidad
● Azul parpadeante (0.25 Hz): el localizador de ID del sistema está activado
● Apagado: estado normal
LED de alimentación del sistema (verde)
El LED se ilumina en color verde cuando la alimentación del sistema está disponible. El LED está apagado cuando el sistema no funciona.
Estado/LED de condición (azul/ámbar)
El LED se ilumina con luz azul fija cuando el sistema está encendido y en funcionamiento normal. El LED se ilumina con luz azul
parpadeante cuando el gabinete de administración está ocupado, por ejemplo, cuando realiza un arranque o una actualización de firmware.
Los LED le ayudan a identificar qué componente está causando la falla. El LED se ilumina con luz ámbar fija cuando experimenta una falla
de hardware de sistema que podría asociarse con un LED de error en un módulo de controladora, IOM o PCM. El LED se ilumina con luz
ámbar parpadeante cuando ocurre una falla lógica.
Pantalla de identificación de unidad (verde)
La UID es una pantalla doble de siete segmentos que muestra la posición numérica del gabinete en la secuencia de cableado. Esto también
se conoce como ID de gabinete. La ID del gabinete de la controladora es 0.
LED de identidad (azul)
Cuando se activa, el LED de identidad parpadea a una velocidad de 1 segundo encendido, 1 segundo apagado para localizar fácilmente el
chasis dentro de un centro de datos. La función de localización se puede habilitar o deshabilitar mediante SES. Presionar el botón alterna
entre estados del LED. El firmware no es compatible con la configuración de la ID del gabinete mediante el botón de ID del sistema.
Panel del operador del gabinete 5U
La parte frontal del gabinete tiene un panel del operador ubicado en la brida de la orejeta izquierda del chasis de 5U.
El panel del operador es una parte integral del chasis del gabinete, pero no se puede reemplazar en el sitio.
Ilustración 29. LED: panel del operador; panel frontal del gabinete 5U
Tabla 5. Funciones del panel del operador
No Indicator Estado
1 Pantalla de identificación de la unidad
(UID)
Verde (pantalla de siete segmentos; secuencia de gabinete)
2 Sistema encendido/en espera
● Luz verde fija: indicación positiva
22 Hardware del sistema de almacenamiento

Tabla 5. Funciones del panel del operador (continuación)
No Indicator Estado
● Luz ámbar fija: sistema en espera (no en funcionamiento)
3 Error del módulo Luz ámbar fija o parpadeante: falla presente
4 Estado lógico Luz ámbar fija o parpadeante: falla presente
5 Falla del cajón superior Luz ámbar fija o parpadeante: falla presente en la unidad, un cable o un sideplane
6 Falla del cajón inferior Luz ámbar fija o parpadeante: falla presente en la unidad, un cable o un sideplane
Pantalla de identificación de unidad
La UID es una pantalla doble de siete segmentos que muestra la posición numérica del gabinete en la secuencia de cableado. Esto también
se conoce como ID de gabinete. La ID del gabinete de la controladora es 0.
LED de sistema encendido/en espera (verde/ámbar)
El LED se ilumina en color ámbar cuando solo está disponible la potencia en espera (no en funcionamiento). El LED se ilumina en color
verde cuando la alimentación del sistema está disponible (en funcionamiento).
LED de error del módulo (ámbar)
El LED se ilumina con luz ámbar cuando hay una falla de hardware del sistema. Este LED lo ayuda a identificar el componente que provoca
la falla, que se puede asociar con un LED de error en un módulo de controladora, IOM, PSU, FCM, DDIC o cajón.
LED de estado lógico (ámbar)
Este LED indica un cambio de estado o falla por algo que no sea el sistema de administración del gabinete. Puede ser iniciado desde el
módulo de la controladora o un HBA externo. La indicación se asocia normalmente a una DDIC y los LED a cada posición de disco dentro
del cajón, que ayudan a identificar los DDIC afectados.
LED de error de cajón (ámbar)
Este LED indica si una falla en un disco, un cable o un sideplane indican superior (cajón 0) o inferior (cajón 1).
PRECAUCIÓN:
Los sideplanes de los cajones del gabinete no son intercambiables en caliente y no los puede reparar el
cliente.
Módulos de controladora
En la sección, se describen los módulos de controladora que se utilizan en gabinetes de almacenamiento de 12 Gb/s. Cumplen con los
requisitos eléctricos y mecánicos de la especificación de SBB v2.1 más reciente.
En la ilustración a continuación, se muestra un módulo de controladora FC/iSCSI de 4 puertos alineado para su uso en el panel posterior
del gabinete 2U. El módulo de controladora también está alineado correctamente para su uso en cualquier ranura ubicada en el panel
posterior del gabinete 5U84.
Hardware del sistema de almacenamiento
23

Ilustración 30. Módulo de controladora: orientación posterior
Cada módulo de controladora mantiene VPD (datos de producto vitales) en dispositivos EEPROM. En un sistema de controladora doble,
los módulos de controladora están interconectados mediante buses I2C definidos por SBB en el midplane. De esta manera, el módulo de
SBB puede descubrir el tipo y las funcionalidades del módulo de SBB asociado y viceversa, dentro del gabinete.
LED del módulo de controladora de 12 Gb/s
Los diagramas con tablas inmediatamente a continuación proporcionan descripciones para los diferentes módulos de controladora que se
pueden instalar en el panel posterior de los gabinetes de controladora. La visualización de módulos de controladora por separado del
gabinete permite una mayor claridad para identificar los elementos de los componentes que se exponen en los diagramas y se describen en
las tablas complementarias de los conjuntos de tablas/ilustraciones.
NOTA: Tenga en cuenta lo siguiente cuando vea los diagramas del módulo de controladora en las siguientes páginas:
● En cada diagrama, el módulo de la controladora está orientado para la inserción en la ranura superior (A) de gabinetes 2U. Cuando se
orienta para su uso en la ranura inferior (B) de gabinetes 2U, las etiquetas del módulo de la controladora aparecen boca abajo.
● En cada diagrama, el módulo de la controladora está orientado para la inserción en cualquiera de las ranuras de los gabinetes 5U84.
● De manera alternativa, puede configurar el gabinete de la controladora 2U con un único módulo de controladora. Instale el módulo de la
controladora en la ranura A e instale una placa de relleno en la ranura B.
Ilustración 31. Módulos de controladora FC/iSCSI (FC y SFP de 10GbE) del sistema de almacenamiento ME4 Series
Tabla 6. LED de los módulos de la controladora (FC y SFP iSCSI) de la ME4 Series
LED Descripción Definición
1 FC host de 4/8/16 Gb
1
● Estado de vínculo
● Actividad de vínculo
● Apagado: no se detectó ningún vínculo.
● Verde: el puerto está conectado y el vínculo está activado.
● Verde parpadeante: el vínculo tiene actividad de I/O.
2 iSCSI host de 10 GbE
2, 3
● Estado de vínculo
● Actividad de vínculo
● Apagado: no se detectó ningún vínculo.
● Verde: el puerto está conectado y el vínculo está activado.
● Verde parpadeante: el vínculo tiene actividad de I/O o de replicación.
3 En buen estado
● Verde: la controladora funciona normalmente.
● Verde parpadeante: el sistema se está iniciando.
● Apagado: el módulo de controladora no está en buen estado o está
apagado.
4 Falla
● Apagado: la controladora funciona normalmente.
24 Hardware del sistema de almacenamiento

Tabla 6. LED de los módulos de la controladora (FC y SFP iSCSI) de la ME4 Series (continuación)
LED Descripción Definición
● Ámbar fuerte: se detectó una falla o es necesaria una acción de
servicio.
● Ámbar parpadeante: encendido controlado por hardware, vaciado de
caché o error de restauración.
5 Listo para quitar
● Apagado: la controladora no está lista para la extracción.
● Azul: el módulo de controladora está listo para la extracción.
6 Identificar Blanco: se está identificando el módulo de controladora.
7 Estado de caché
4
● Verde: la caché está contaminada (contiene datos no escritos) y el
funcionamiento es normal. La información no escrita puede estar
compuesta de datos de depuración o de registro que permanecen en la
caché, por lo cual el LED verde de estado de caché no indica, por sí
solo, que haya datos de usuario en riesgo o que sea necesario realizar
alguna acción.
● Apagado: en una controladora en funcionamiento, la caché está limpia
(no contiene datos no escritos). Esta es una condición ocasional que
sucede cuando se inicia el sistema.
● Verde parpadeante: hay una actualización automática de la caché o un
vaciado de CompactFlash en curso, que indica actividad de la caché.
8 Estado activo del vínculo de puerto de red
5
● Apagado: el vínculo de Ethernet no está establecido o el vínculo está
desactivado.
● Verde: el vínculo de Ethernet está activo (corresponde a todas las
velocidades de vínculo negociadas).
9 Velocidad de vínculo del puerto de red
5
● Apagado: el vínculo está activo a velocidades negociadas de
10/100 base-T.
● Ámbar: el vínculo está activo y negociado a 1000 base-T.
10 Estado del puerto de expansión
● Apagado: el puerto está vacío o el vínculo está desactivado.
● Verde: el puerto está conectado y el vínculo está activado.
1
Cuando están en modo FC, los SFP deben ser opciones de fibra óptica calificadas de 8 Gb o 16 Gb. Un SFP de 16 Gb/s puede funcionar a
16 Gb/s, 8 Gb/s, 4 Gb/s o negociar automáticamente su velocidad de vínculo. Un SFP de 8 Gb/s puede funcionar a 8 Gb/s, 4 Gb/s o
negociar automáticamente su velocidad de vínculo.
2
Cuando están en modo de iSCSI de 10 GbE, los SFP deben ser una opción óptica calificada de iSCSI 10 GbE.
3
Durante el encendido y el arranque, los LED de iSCSI están encendidos/parpadean temporalmente y, luego, cambian al modo de
funcionamiento.
4
El LED de estado de caché es compatible con el comportamiento de encendido y el comportamiento de funcionamiento (estado de
caché). Consulte también Comportamiento de encendido: LED de estado de caché en la página 28.
5
Cuando el puerto está desactivado, ambos LED están apagados.
Ilustración 32. LED del módulo de la controladora 10Gbase-T de la ME4 Series
Tabla 7. LED del módulo de la controladora 10Gbase-T de la ME4 Series
LED Descripción Definición
1 iSCSI host 10Gbase-T
● Apagado: no se detectó ningún vínculo.
Hardware del sistema de almacenamiento 25

Tabla 7. LED del módulo de la controladora 10Gbase-T de la ME4 Series (continuación)
LED Descripción Definición
● Estado de vínculo
● Actividad de vínculo
● Verde: el puerto está conectado y el vínculo está activado.
● Verde parpadeante: el vínculo tiene actividad de I/O.
2 iSCSI host 10Gbase-T
Velocidad de vínculo
● Apagado: el vínculo no está establecido o el vínculo está desactivado.
● Verde: el vínculo está activo a una velocidad negociada de 10 Gb.
● Amarillo fijo: el vínculo está activo a una velocidad negociada de 1 Gb.
3 En buen estado
● Verde: la controladora funciona normalmente.
● Verde parpadeante: el sistema se está iniciando.
● Apagado: el módulo de controladora no está en buen estado o está apagado.
4 Falla
● Apagado: la controladora funciona normalmente.
● Ámbar fuerte: se detectó una falla o es necesaria una acción de servicio.
● Ámbar parpadeante: encendido controlado por hardware, vaciado de caché o error de
restauración.
5 Listo para quitar
● Apagado: la controladora no está lista para la extracción.
● Azul: el módulo de controladora está listo para la extracción.
6 Identificar Blanco: se está identificando el módulo de controladora.
7 Estado de caché
3
● Verde: la caché está contaminada (contiene datos no escritos) y el funcionamiento es normal.
La información no escrita puede estar compuesta de datos de depuración o de registro que
permanecen en la caché, por lo cual el LED verde de estado de caché no indica, por sí solo,
que haya datos de usuario en riesgo o que sea necesario realizar alguna acción.
● Apagado: en una controladora en funcionamiento, la caché está limpia (no contiene datos no
escritos). Esta es una condición ocasional que sucede cuando se inicia el sistema.
● Verde parpadeante: hay una actualización automática de la caché o un vaciado de
CompactFlash en curso, que indica actividad de la caché.
8 Estado de actividad del
puerto de red
4
● Apagado: el vínculo de Ethernet no está establecido o el vínculo está desactivado.
● Verde: el vínculo de Ethernet está activo (corresponde a todas las velocidades de vínculo
negociadas).
9 Velocidad de vínculo del
puerto de red
4
● Apagado: el vínculo está activo a velocidades negociadas de 10/100base-T.
● Amarillo fijo: el vínculo está activo y negociado a 1000base-T.
10 Estado del puerto de
expansión
● Apagado: el puerto está vacío o el vínculo está desactivado.
● Verde: el puerto está conectado y el vínculo está activado.
1
Los conectores 10Gbase-T deben utilizar opciones de cableado calificadas.
2
Durante el encendido y el arranque, los LED de iSCSI estarán encendidos/parpadearán temporalmente y, luego, cambiarán al modo de
funcionamiento.
3
El LED de estado de caché es compatible con el comportamiento de encendido y el comportamiento de funcionamiento (estado de
caché).
4
Cuando el puerto está desactivado, ambos LED están apagados. Consulte también Comportamiento de encendido: LED de estado de
caché en la página 28.
Ilustración 33. LED del módulo de la controladora SAS de la ME4 Series
26
Hardware del sistema de almacenamiento

Tabla 8. LED del módulo de la controladora SAS de la ME4 Series
LED Descripción Definición
1 SAS host de 12 Gb
1-2
● Estado de vínculo
● Actividad de vínculo
● Verde: el puerto está conectado y el vínculo está activado.
● Amarillo fijo: hay un vínculo parcial (uno o más canales desactivados).
● Verde parpadeante o amarillo fijo: se detecta actividad del vínculo de host.
2 En buen estado
● Verde: la controladora funciona normalmente.
● Verde parpadeante: el sistema se está iniciando.
● Apagado: el módulo de controladora no está en buen estado o está apagado.
3 Falla
● Apagado: la controladora funciona normalmente.
● Ámbar fuerte: se detectó una falla o es necesaria una acción de servicio.
● Ámbar parpadeante: encendido controlado por hardware, vaciado de caché o error de
restauración.
4 Listo para quitar
● Apagado: la controladora no está lista para la extracción.
● Azul: el módulo de controladora está listo para la extracción.
5 Identificar Blanco: se está identificando el módulo de controladora.
6 Estado de caché
3
● Verde: la caché está contaminada (contiene datos no escritos) y el funcionamiento es normal.
La información no escrita puede estar compuesta de datos de depuración o de registro que
permanecen en la caché, por lo cual el LED verde de estado de caché no indica, por sí solo,
que haya datos de usuario en riesgo o que sea necesario realizar alguna acción.
● Apagado: en una controladora en funcionamiento, la caché está limpia (no contiene datos no
escritos). Esta es una condición ocasional que sucede cuando se inicia el sistema.
● Verde parpadeante: hay una actualización automática de la caché o un vaciado de
CompactFlash en curso, que indica actividad de la caché.
7 Estado de actividad del
puerto de red
4
● Apagado: el vínculo de Ethernet no está establecido o el vínculo está desactivado.
● Verde: el vínculo de Ethernet está activo (corresponde a todas las velocidades de vínculo
negociadas).
8 Velocidad de vínculo del
puerto de red
4
● Apagado: el vínculo está activo a velocidades negociadas de 10/100base-T.
● Ámbar: el vínculo está activo y negociado a 1000base-T.
9 Estado del puerto de
expansión
Verde: el puerto está conectado y el vínculo está activado.
1
Los cables deben ser opciones de cable miniSAS HD calificadas.
2
Utilice una opción de cable de SFF-8644 a SFF-8644 cuando conecte la controladora a un HBA SAS de 12 Gb.
3
El LED de estado de caché es compatible con el comportamiento de encendido y el comportamiento de funcionamiento (estado de
caché). Consulte también Comportamiento de encendido: LED de estado de caché en la página 28.
4
Cuando el puerto está desactivado, ambos LED están apagados. Consulte también Comportamiento de encendido/apagado en la página
27.
5
Una vez que se ilumina un LED de estado del vínculo, permanece encendido, incluso si la controladora se apaga mediante el PowerVault
Manager o la CLI.
Cuando una controladora se apaga o se desactiva, el LED de estado del vínculo permanece encendido, indicando erróneamente que la
controladora se puede comunicar con el host. Aunque hay un vínculo entre el host y el chip de la controladora, la controladora no se
comunica con el chip. Para restablecer el LED, se debe realizar un ciclo de apagado y encendido en la controladora.
Detalles de LED de estado de caché
En esta sección, se describe el comportamiento de los LED durante el encendido y apagado del comportamiento del estado de caché.
Comportamiento de encendido/apagado
Durante el encendido, en el LED de estado de caché se muestran patrones parpadeantes que reflejan estados de pantalla de componentes
internos de la secuencia discreta de encendido.
Hardware del sistema de almacenamiento
27

Tabla 9. Comportamiento de encendido: LED de estado de caché
Elemento Estados de pantalla informados por el LED de estado de caché durante la secuencia de encendido
Estado de pantalla 0 1 2 3 4 5 6 7
Componente VP SC BE de SAS ASIC Host Boot (Inicio) Normal Restablecer
Patrón de parpadeo 1 encendido
/7 apagado
2 encendido
/6 apagado
3 encendido
/5 apagado
4 encendido
/4 apagado
5 encendido
/3 apagado
6 encendido
/2 apagado
Sólido/
Encendido
Fijo
Una vez que el gabinete completa la secuencia de encendido, el LED de estado de caché muestra sólido/encendido (normal) antes de
asumir el estado de funcionamiento a fines de caché.
Comportamiento de estado de caché
Si el LED parpadea de manera uniforme, hay un vaciado de caché en curso. Cuando un módulo de controladora pierde potencia y la caché
de escritura está sucia (contiene datos no escritos en el disco), el paquete de supercapacitor proporciona alimentación de reserva para
vaciar (copiar) datos de la caché de escritura a la memoria CompactFlash. Cuando se completa el vaciado de la caché, esta pasa al modo
de actualización automática.
Si el LED parpadea despacio momentáneamente, la caché está en modo de actualización automática. En este modo, si la alimentación
primaria se restaura antes de que la alimentación de respaldo se agote (3 a 30 minutos, en función de varios factores) el sistema se inicia,
busca datos conservados en la caché y los escribe en el disco. Esto significa que el sistema puede estar en funcionamiento en 30 segundos
y antes de agotar el tiempo de espera típico de I/O del host de 60 segundos, momento en el cual la falla del sistema causaría una falla de
aplicación de host. Si la alimentación primaria se restaura antes de que la alimentación de respaldo se agote, el sistema se inicia y restaura
los datos a la caché desde CompactFlash, lo que puede demorar alrededor de 90 segundos. El mecanismo de actualización automática y
vaciado de caché es una función de protección de datos importante. Esencialmente, se conservan cuatro copias de datos de usuario: una
en la caché de controladora y otra en CompactFlash de cada controladora. El LED de estado de caché se ilumina en color verde fijo
durante el proceso de arranque. Este comportamiento indica que la caché está registrando todas las pruebas automáticas de encendido
(POST), que se vaciarán a CompactFlash la próxima vez que apague la controladora.
NOTA:
Si el LED de estado de caché se ilumina en color verde fijo y desea apagar la controladora, hágalo desde la interfaz de usuario, para
que los datos no escritos se puedan vaciar a CompactFlash.
CompactFlash
Durante una pérdida de alimentación o falla de la controladora, los datos almacenados en caché se guardan en memoria no volátil
(CompactFlash). Los datos se restauran a la caché y se escriben en el disco una vez corregido el problema. Para evitar escribir datos
incompletos en el disco, la imagen almacenada en CompactFlash se verifica antes de enviarla al disco definitivamente. La tarjeta de
memoria CompactFlash se encuentra en el extremo orientado hacia el midplane del módulo de controladora. No quite la tarjeta: solo se
utiliza para la recuperación de caché.
28
Hardware del sistema de almacenamiento

Ilustración 34. Tarjeta de memoria CompactFlash
1. Tarjeta de memoria CompactFlash
2. Módulo de controladora visto desde la parte posterior
En configuraciones de módulo de controladora única, si el módulo de controladora falló o no se inicia y el LED de estado de caché está
encendido o parpadea, debe trasladar la CompactFlash a una controladora de repuesto para recuperar los datos no vaciados en el disco.
PRECAUCIÓN: Para configuración de módulo de controladora único solamente, a fin de conservar los datos almacenados
existentes en la CompactFlash, debe trasladar la CompactFlash del módulo de controladora fallido al de repuesto. Este
procedimiento se indica en el procedimiento para reemplazar un módulo de controladora del
Manual del propietario del
sistema de almacenamiento de Dell EMC PowerVault ME4 Series
. Si no utiliza este procedimiento, provocará la pérdida
de datos almacenados en el módulo de caché. La CompactFlash debe permanecer en el mismo gabinete. Si la
CompactFlash se utiliza/instala en un gabinete diferente, habrá pérdida de datos/daños en los datos.
NOTA: En las configuraciones de módulo de controladora doble con un módulo de controladora asociado en buen estado, no hay
necesidad de trasladar la CompactFlash del módulo de controladora fallida al módulo de controladora de repuesto. La caché se duplica
entre los módulos de controladora, siempre y cuando la caché del volumen esté establecida en estándar para todos los volúmenes del
pool propiedad del módulo de controladora fallido.
Paquete supercapacitor
Para proteger la caché del módulo de la controladora en caso de que se produzca una falla de alimentación, cada modelo de gabinete de
controladora está equipado con tecnología de supercapacitor, junto con la memoria CompactFlash, incorporada en cada módulo de la
controladora para proporcionar un tiempo de ejecución de respaldo extendido de la memoria caché. El supercapacitor proporciona energía
para respaldar datos no escritos de la caché de escritura en la CompactFlash en caso de que se produzca una falla de alimentación. Los
datos no escritos en la memoria CompactFlash se asignan automáticamente a los medios de disco cuando se restaura la alimentación. En
caso de que se produzca una falla de alimentación, mientras la caché sea mantenida por el paquete del supercondensador, el LED de
estado de la caché parpadeará a una tasa de 1/10 segundos encendido y 9/10 segundo apagado.
Falla de controladora cuando solo funciona una
controladora
La siguiente información corresponde a gabinetes de controladora única de 2U cuando falla la controladora. También se aplica a gabinetes
de dos controladoras de 2U y 5U cuando una de las controladoras está inactiva y la otra controladora falla.
La memoria caché se vacía a CompactFlash en caso de una falla de controladora o pérdida de alimentación. Durante el proceso de
escritura a CompactFlash, el supercapacitor solo enciende los componentes necesarios para escribir la caché a CompactFlash. Este
proceso normalmente demora 60 segundos por 1 Gbyte de caché. Después de que la caché se copia en CompactFlash, la alimentación
restante del supercapacitor se utiliza para actualizar la memoria caché. Mientras el supercapacitor mantiene la caché, el LED de estado de
caché parpadea a una tasa de 1/10 de segundo encendido y 9/10 de segundo apagado.
NOTA:
Quite la tarjeta de memoria CompactFlash solo si lo recomienda el soporte técnico de Dell EMC.
Hardware del sistema de almacenamiento 29

La caché transportable solo se aplica a configuraciones de controladora única. En las configuraciones de controladora doble con una
controladora asociada en buen estado, no hay necesidad de transportar la caché de controladora fallida a una controladora de
repuesto, ya que la caché se duplica entre controladoras siempre y cuando la caché de volumen esté establecida a estándar en todos
los volúmenes del pool propiedad de la controladora fallida.
LED de estado de caché: acción correctiva
Si la controladora ha fallado o no se inicia, compruebe si el LED de estado de caché está encendido o parpadeando.
Tabla 10. LED: estado de caché de panel posterior
Estado Acción
El LED de estado de caché está apagado y la
controladora no se inicia.
Si el problema persiste, reemplace el módulo de controladora.
El LED de estado de caché está apagado y se inicia la
controladora.
El sistema ha vaciado datos en los discos. Si el problema persiste, reemplace
el módulo de controladora.
El LED de estado de caché parpadea a una tasa de
1:10-1 Hz y la controladora no se inicia.
Es posible que deba reemplazar el módulo de controladora.
El LED de estado de caché parpadea a una tasa de
1:10-1 Hz y se inicia la controladora.
El sistema está vaciando datos en CompactFlash. Si el problema persiste,
reemplace el módulo de controladora.
El LED de estado de caché parpadea a una tasa de
1:1-2 Hz y la controladora no se inicia.
Es posible que deba reemplazar el módulo de controladora.
El LED de estado de caché parpadea a una tasa de
1:1-1 Hz y se inicia la controladora.
El sistema está en modo de actualización automática. Si el problema persiste,
reemplace el módulo de controladora.
Transporte de caché
Para conservar los datos existentes almacenados en CompactFlash, debe transportar la CompactFlash desde la controladora fallida a una
controladora de reemplazo. Si no transporta la CompactFlash, se perderán los datos almacenados en el módulo de caché.
PRECAUCIÓN:
Quite el módulo de controladora solo después de que se haya completado el proceso de copia, indicado
por el LED de estado de caché apagado o parpadeante en una tasa de 1:10.
30 Hardware del sistema de almacenamiento

Solución de problemas
Estos procedimientos están diseñados para utilizarse solo durante la configuración inicial, a fin de verificar que la configuración de
hardware se realice correctamente. No están diseñados para ser usados como procedimientos de solución de problemas para sistemas
configurados mediante datos de producción e I/O.
Temas:
• Resumen
• Metodología de aislamiento de fallas
• LED
• Solución de problemas de gabinetes 2U
• Solución de problemas de gabinetes 5U
• Sensores de temperatura
• I/O del host
Resumen
El sistema del gabinete incluye un procesador del gabinete de almacenamiento (SEP) y la lógica de monitoreo y control asociados para que
pueda diagnosticar problemas con los sistemas de alimentación, de enfriamiento y de unidad del gabinete. Las interfaces de administración
permiten el aprovisionamiento, el monitoreo y la administración del sistema de almacenamiento.
NOTA: Consulte Metodología de aislamiento de fallas en la página 31 al realizar los diagnósticos del sistema.
Metodología de aislamiento de fallas
Los sistemas de almacenamiento de Dell EMC PowerVault ME4 Series proporcionan muchas maneras de aislar fallas. En esta sección, se
presenta la metodología básica para localizar fallas dentro de un sistema de almacenamiento y para identificar las CRU correspondientes
afectadas.
Utilice el PowerVault Manager para configurar y aprovisionar el sistema una vez finalizada la instalación de hardware. Como parte de este
proceso, configure y habilite la notificación de eventos para que el sistema le notifique cuando se produzca un problema de gravedad igual
o superior a la configurada (consulte el tema sobre configuración de notificaciones de eventos en la Guía del administrador del sistema de
almacenamiento Dell EMC PowerVault ME4 Series). Si la notificación de eventos está configurada y habilitada, puede seguir las acciones
recomendadas en el mensaje de notificación para solucionar el problema, como se indica en las opciones presentadas en la sección a
continuación.
Pasos básicos de metodología de aislamiento de fallas
A continuación, encontrará un resumen de los pasos básicos que se utilizan para realizar el aislamiento de fallas y la solución de problemas:
● Recopile información sobre la falla, incluido el uso de los LED del sistema, como se describe en Recopilar información sobre la falla.
● Determine dónde ocurre la falla en el sistema, como se describe en Determine dónde ocurre la falla.
● Revise los registros de eventos, como se describe en Revisar los registros de eventos.
● Si es necesario, aísle la falla a una configuración o un componente de ruta de datos, como se describe en Aislar la falla.
Opciones disponibles para realizar pasos básicos
Cuando aísle fallas y lleve a cabo los pasos de solución de problemas, seleccione las opciones que mejor se adapten a su ambiente. Ninguna
opción es mutuamente excluyente con el uso de otra opción (se describen cuatro opciones a continuación). Puede utilizar el PowerVault
Manager para verificar los iconos/valores del estado del sistema y sus componentes, a fin de asegurarse de que todo está en buen estado,
2
Solución de problemas 31

o para desglosar un componente problemático. Si descubre un problema, el PowerVault Manager o la CLI proporcionan un texto de acción
recomendada en línea. Las opciones para realizar pasos básicos se enumeran según la frecuencia de uso:
● Utilice el PowerVault Manager
● Utilice la CLI
● Supervise la notificación de eventos
● Vea los LED del gabinete
Utilice el PowerVault Manager
El PowerVault Manager utiliza iconos de estado para mostrar Buen estado, Degradado, Falla o Desconocido para el sistema y sus
componentes. El PowerVault Manager le permite supervisar el estado del sistema y sus componentes. Si algún componente tiene un
problema, el estado del sistema será Degradado, Falla o Desconocido. Utilice la GUI de la aplicación web para desglosar y encontrar
cualquier componente que presente un problema, y siga las acciones en el campo Recomendación del componente para resolver el
problema.
Utilice la CLI
Como alternativa al uso del PowerVault Manager, puede ejecutar el comando de la CLI show system para ver la condición del sistema y
sus componentes. Si algún componente presenta un problema, el estado del sistema será Degradado, Falla o Desconocido, y esos
componentes se listarán como Componentes en mal estado. Siga las acciones recomendadas en el campo Recomendación de estado
para solucionar el problema.
Supervise la notificación de eventos
Cuando la notificación de eventos está configurada y habilitada, puede ver registros de eventos para supervisar el estado del sistema y sus
componentes. Si un mensaje le solicita verificar si un evento ha sido registrado o ver información sobre un evento en el registro, puede
hacerlo mediante el PowerVault Manager o la CLI. Mediante el PowerVault Manager, puede ver el registro de eventos y hacer clic en el
mensaje de evento para ver los detalles. Mediante la CLI, ejecute el comando show events detail (con parámetros adicionales para
filtrar la salida) para ver el detalle de un evento.
Vea los LED del gabinete
Puede ver los LED en el hardware (mientras usa las descripciones de LED para el modelo de gabinete como referencia) para identificar el
estado de los componentes. Si un problema impide el acceso al PowerVault Manager o a la CLI, esta es la única opción disponible. Sin
embargo, a menudo se llevan a cabo el monitoreo y la administración en una consola de administración mediante interfaces de
administración de almacenamiento, en lugar de confiar en línea de visión de LED de componentes de hardware en rack.
Ejecución de pasos básicos
Puede utilizar cualquiera de las opciones disponibles descritas anteriormente para realizar los pasos básicos que componen la metodología
de aislamiento de fallas.
Recopile información de fallas
Cuando se produce una falla, es importante recopilar toda la información posible. Esto ayudará a determinar la acción correcta necesaria
para corregir la falla.
Empiece por revisar la falla informada:
● La falla, ¿está relacionada con una ruta de datos interna o una ruta de datos externa?
● La falla, ¿está relacionada con un componente de hardware, como módulo de unidad de disco, módulo de controladora o fuente de
alimentación?
Al aislar la falla a uno de los componentes dentro del sistema de almacenamiento, podrá determinar la acción correctiva necesaria más
rápidamente.
32
Solución de problemas

Determine dónde está ocurriendo la falla
Cuando se produce una falla, el LED de falla del módulo (que se encuentra en el panel del operador de la orejeta izquierda de un gabinete)
se ilumina. Verifique los LED en la parte posterior del gabinete para limitar la falla a una CRU, una conexión o ambas. Los LED también
ayudarán a identificar la ubicación de una CRU que informa una falla.
Utilice el PowerVault Manager para verificar cualquier falla encontrada al observar los LED. El PowerVault Manager también es una
herramienta útil para determinar dónde ocurre la falla si los LED no se pueden ver debido a la ubicación del sistema. Esta aplicación web
proporciona una representación visual del sistema y de dónde ocurre la falla. El PowerVault Manager también proporciona información más
detallada sobre las CRU, datos y fallas.
Revise los registros de eventos
Los registros de eventos registran todos los eventos del sistema. Cada evento tiene un código numérico que identifica el tipo de evento
producido y tiene uno de los siguientes niveles de gravedad:
● Crítica: se produjo una falla que puede provocar que una controladora se apague. Corrija el problema inmediatamente.
● Error: se produjo una falla que puede afectar la integridad de datos o la estabilidad del sistema. Corrija el problema lo antes posible.
● Advertencia: se produjo un problema que puede afectar la estabilidad del sistema, pero no la integridad de datos. Evalúe el problema y
corríjalo si es necesario.
● Informativa: se produjo un cambio de estado o configuración, o se produjo un problema que el sistema corrigió. No se requiere una
acción inmediata.
Los registros de eventos registran todos los eventos del sistema. Es muy importante revisarlos, no solo identificar la falla, pero buscar los
eventos que podrían haberla ocasionado. Por ejemplo, un host podría perder la conexión a un grupo de discos si un usuario cambia la
configuración de canal sin tener en cuenta los recursos de almacenamiento asignados a él. Además, el tipo de falla puede ayudar a aislar el
problema al hardware o el software.
Aísle la falla
Ocasionalmente, puede ser necesario aislar una falla. Esto es particularmente cierto con rutas de datos, debido a la cantidad de
componentes que componen la ruta de datos. Por ejemplo, si se produce un error de datos del lado del host, podría ser causado por
cualquiera de los componentes en la ruta de datos: el módulo de la controladora, el cable o el host de datos.
Si el gabinete no se inicializa
Los gabinetes pueden tardar hasta dos minutos en inicializarse. Si un gabinete no se inicializa, realice lo siguiente:
● Realice una reexaminación
● Realizar un ciclo de encendido del sistema
● Asegúrese de que el cable de alimentación esté conectado correctamente y verifique la fuente de alimentación a la que está conectado
● Verifique el registro de eventos en busca de errores
Corrección de ID de gabinete
Cuando instale un sistema con gabinetes de unidad conectados, las ID de gabinete podrían no corresponder al orden de cableado físico.
Esto ocurre porque la controladora puede haber estado conectada a gabinetes en otra configuración e intenta conservar las ID de gabinete
anteriores, si es posible. Para corregir esta condición, asegúrese de que ambas controladoras estén activas y realice una reexaminación
mediante el PowerVault Manager o la CLI. Esto volverá a ordenar los gabinetes, pero corregir las ID de gabinetes puede demorar hasta dos
minutos.
Para realizar una reexaminación mediante la CLI, introduzca el siguiente comando:
rescan
Para realizar una reexaminación mediante el PowerVault Manager:
1. Verifique que ambas controladoras funcionen normalmente.
2. Realice uno de los siguientes pasos:
● Seleccione la pestaña Sistema y haga clic en Reexaminar canales de disco.
● En el tema Sistema, seleccione Acción > Reexaminar canales de disco.
3. Haga clic en Rescan (Nueva exploración).
Solución de problemas
33

NOTA: La acción de reordenamiento de ID de gabinete solo se aplica al modo de controladora doble. Si solo hay una controladora
disponible, debido a cualquier configuración de controladora única o una falla de controladora, una reexaminación manual no
reordenará las ID de gabinete de unidad.
LED
Se utilizan colores de LED sistemáticamente en todo el gabinete y sus componentes para que indicar el estado:
● Luz verde fija: indicación positiva o buena
● Luz verde/ámbar parpadeante: condición no crítica
● Luz ámbar fuerte: falla crítica
● Luz azul fija: identificación de IOM o módulo de controladora
LED del gabinete 2U
LED del PCM del gabinete 2U
En condiciones normales, los LED de buen estado del módulo de enfriamiento de alimentación (PCM) se iluminarán en color verde fijo.
Tabla 11. Estados de LED de PCM
PCM en
buen estado
(verde)
Falla del
ventilador
(amarillo
fijo)
Falla de CA
(amarillo
fijo)
Falla de CC
(amarillo
fijo)
Estado
Apagado Apagado Apagado Apagado No hay alimentación de CA en ningún PCM
Apagado Apagado Encendido Encendido No hay alimentación de CA en esta PCM
Encendido Apagado Apagado Apagado CA presente; el PCM funciona correctamente
Encendido Apagado Apagado Encendido La velocidad del ventilador del PCM está fuera de los límites aceptables
Apagado Encendido Apagado Apagado Falla del ventilador del PCM
Apagado Encendido Encendido Encendido Falla del PCM (por encima de la temperatura, por encima del voltaje, por
encima de la corriente)
Apagado Parpadeando Parpadeando Parpadeando La descarga de firmware de PCM está en curso
LED del panel del operador del gabinete 2U
En el panel del operador, se muestra el estado agregado de todos los módulos. Consulte Panel del operador del gabinete 2U en la página
21. Los LED del panel del operador se definen en la siguiente tabla.
Tabla 12. Estados de LED del panel del operador
Alimentación del
sistema (verde/
ámbar)
Falla del módulo
(ámbar)
Identidad
(azul)
Pantalla
LED
Alarmas/LED
asociados
Estado
Encendido Apagado Apagado -- -- Alimentación en espera de 5 V presente,
falla o apagado general de alimentación
Encendido Encendido Encendido Encendido -- Estado de prueba del panel del operador
encendido (5s)
Encendido Apagado Apagado -- -- Encendido, todas las funciones en buen
estado
Encendido Encendido -- -- LED de error del
PCM, LED de error
del ventilador
Cualquier falla del PCM, falla del ventilador,
temperatura superior o inferior al límite
34 Solución de problemas

Tabla 12. Estados de LED del panel del operador (continuación)
Alimentación del
sistema (verde/
ámbar)
Falla del módulo
(ámbar)
Identidad
(azul)
Pantalla
LED
Alarmas/LED
asociados
Estado
Encendido Encendido -- -- LED del módulo SBB Cualquier falla de módulo SBB
Encendido Encendido -- -- Sin LED de módulo Falla lógica del gabinete
Encendido Blink (Hacer
parpadear)
-- -- LED de estado del
módulo en módulo
SBB
Tipo de módulo SBB desconocido (no válido
o combinado) instalado, falla del bus I
2
C
(comunicaciones entre SBB). Falla de
configuración del VPD de EBOD
Encendido Blink (Hacer
parpadear)
-- -- LED de error del
PCM, LED de error
del ventilador
Tipo de PCM desconocido (no válido o
mixto) instalado o falla del bus I
2
C
(comunicaciones de PCM)
-- -- -- Blink
(Hacer
parpadear)
-- Identificación del gabinete o ID no válida
seleccionada
Acciones:
● Si el LED de falla en el módulo del panel del operador está encendido, verifique los LED del módulo en el panel posterior del gabinete
para reducir la falla a una CRU, una conexión o ambas.
● Verifique el registro de eventos para obtener información específica sobre la falla y seguir las acciones recomendadas.
● Si está instalando una CRU de IOM:
○ Quite y vuelva a instalar el IOM según las instrucciones en Extracción de un módulo de controladora de un gabinete de módulo de
controladora doble en la página 63.
○ Verifique el registro de eventos en busca de errores.
● Si el LED de error de la CRU está encendido, se detectó una condición de falla.
○ Reinicie esta controladora a partir de la controladora asociada mediante el PowerVault Manager o la CLI.
○ Si reiniciar no resuelve la falla, quite la IOM y vuelva a insertarla.
LED del módulo del portaunidades del gabinete 2U
Un LED verde y un LED ámbar montados en la parte frontal de cada módulo del portaunidades, como se muestra en la siguiente
ilustración, supervisan el estado de la unidad de disco.
Los LED del módulo de unidad se identifican en la ilustración y el comportamiento del LED se describe en la tabla luego de la ilustración.
● Durante el funcionamiento normal, los LED verdes están encendidos y parpadean a medida que funciona la unidad.
● En funcionamiento normal, el LED ámbar estará:
○ Desactivado si no hay ninguna unidad.
○ Apagado a medida que funciona la unidad.
○ Encendido si hay una falla en la unidad.
Ilustración 35. LED: LED de portaunidades (módulos LFF y SFF) utilizados en gabinetes de 2U
1.
LED de actividad del disco 2. LED de falla de disco
3. LED de falla de disco 4. LED de actividad del disco
Solución de problemas 35

Tabla 13. Estados del LED del portaunidades
LED de actividad (verde) LED de error (ámbar) Estado/condición*
Apagado Apagado Apagado (gabinete/módulo de disco)
Apagado Apagado Ausente
Parpadeo apagado con actividad Parpadeante: 1 s encendido/1 s apagado Identificar
● 1 desactivado: parpadeo con actividad
● 2 desactivados: apagado
Encendido Vínculo de unidad (canal PHY) desactivado
Encendido Encendido Falla (sobrante/fallido/bloqueado)
Parpadeo apagado con actividad Apagado Disponible
Parpadeo apagado con actividad Apagado Sistema de almacenamiento: iniciando
Parpadeo apagado con actividad Apagado Sistema de almacenamiento: tolerante a
fallas
Parpadeo apagado con actividad Apagado Sistema de almacenamiento: degradado (no
crítico)
Parpadeo apagado con actividad Parpadeante: 3 s encendido/1 s apagado Sistema de almacenamiento: degradado
(crítico)
Encendido Apagado Sistema de almacenamiento: en cuarentena
Parpadeo apagado con actividad Parpadeante: 3 s encendido/1 s apagado Sistema de almacenamiento: offline (fuera
de cuarentena)
Parpadeo apagado con actividad Apagado Sistema de almacenamiento: reconstrucción
Parpadeo apagado con actividad Apagado I/O de procesamiento (desde el host o
actividad interna)
* Si se producen varias condiciones simultáneamente, el LED de estado se comporta como se indica en la condición enumerada antes en
la tabla, leyendo las filas de arriba hacia abajo.
LED del módulo de la controladora 2U y del IOM
Los LED del IOM y el módulo de la controladora corresponden a módulos de controladora y módulos de expansión, respectivamente.
● Para obtener información sobre los LED del módulo de la controladora, consulte LED del módulo de controladora de 12 Gb/s en la
página 24.
● Para obtener información sobre los LED del IOM, consulte LED del IOM del gabinete de expansión 2U en la página 36.
LED del IOM del gabinete de expansión 2U
Los LED ubicados en la placa frontal supervisan el estado del IOM del gabinete de expansión. Consulte Detalle del IOM: ME412/ME424/
ME484 en la página 14. Los comportamientos del LED para IOM de gabinetes de expansión se describen en la tabla a continuación. Para
saber más sobre las acciones correspondientes a Detalles de LED de estado de caché en la página 27 o Estados de los LED del IOM del
gabinete de expansión en la página 36, consulte Metodología de aislamiento de fallas en la página 31.
Tabla 14. Estados de los LED del IOM del gabinete de expansión
CRU en
buen estado
(verde)
Falla de
CRU
(ámbar)
Actividad del puerto de
host externo (verde)
Estado
Encendido Apagado -- IOM en buen estado
Apagado Encendido -- Falla del IOM: consulte Reemplazo de un módulo de controladora o IOM en
un gabinete de 2U o 5U en la página 62
-- -- Apagado No hay conexión de puerto de host externo
-- -- Encendido Conexión de puerto de miniSAS HD: sin actividad
36 Solución de problemas

Tabla 14. Estados de los LED del IOM del gabinete de expansión (continuación)
CRU en
buen estado
(verde)
Falla de
CRU
(ámbar)
Actividad del puerto de
host externo (verde)
Estado
-- -- Parpadeando Conexión de puerto de miniSAS HD: con actividad
Parpadeando -- -- Error de VPD del EBOD
LED del gabinete 5U84
Cuando el gabinete 5U84 está encendido, todos los LED se encienden durante un período breve para garantizar el funcionamiento.
NOTA: Este comportamiento no indica una falla, a menos que los LED permanezcan encendidos después de varios segundos.
LED de la PSU del gabinete 5U84
Consulte Módulo de fuente de alimentación en la página 19 para obtener una descripción visual de la placa frontal del módulo de la fuente
de alimentación (PSU).
Tabla 15. Estados de LED de PSU
Falla de
CRU
(ámbar)
CA faltante
(ámbar)
Alimentació
n (verde)
Estado
Encendido Apagado Apagado No hay alimentación de CA en ninguna PSU
Encendido Encendido Apagado PSU presente, pero no suministra alimentación, o estado de alerta de PSU (usualmente,
debido a temperatura crítica)
Apagado Apagado Encendido CA principal presente, interruptor encendido. Esta PSU está proporcionando alimentación.
Apagado Apagado Parpadeando Alimentación de CA presente, PSU en espera (otra PSU está proporcionando
alimentación).
Parpadeando Parpadeando Apagado Descarga de firmware de PSU en curso
Apagado Encendido Apagado Alimentación de CA faltante, PSU en espera (otra PSU está proporcionando
alimentación).
Encendido Encendido Encendido El firmware ha perdido la comunicación con el módulo de PSU.
Encendido -- Apagado La PSU falló. Siga el procedimiento en Reemplazo de una fuente de alimentación (PSU)
en un gabinete de 5U en la página 69.
LED del FCM del gabinete 5U84
Consulte Módulo de enfriamiento con ventilador en la página 19 para obtener una descripción visual de la placa frontal del módulo de
enfriamiento con ventilador (FCM).
Tabla 16. Estados del LED del FCM
LED Estado/descripción
Módulo en
buen estado
Una luz verde fija indica que el FCM funciona correctamente. Si está apagada, indica que el módulo del ventilador falló.
Siga el procedimiento que se indica en Reemplazo de un módulo de enfriamiento con ventilador (FCM) en un gabinete de
5U en la página 71 para reemplazar el módulo de controladora del ventilador.
Falla del
ventilador
Una luz ámbar fija indica que el módulo del ventilador ha fallado. Siga el procedimiento que se indica en Reemplazo de un
módulo de enfriamiento con ventilador (FCM) en un gabinete de 5U en la página 71 para reemplazar el módulo de
controladora del ventilador.
Solución de problemas 37

LED del panel de operador del gabinete 5U84
En el panel del operador, se muestra el estado agregado de todos los módulos.
Tabla 17. Estados de LED del panel del operador
LED Estado/descripción
Pantalla de
Id. de unidad
Por lo general, muestra el número de ID del gabinete, pero puede utilizarse para otros fines, por ejemplo, parpadear para
localizar el gabinete.
Encendido/e
n espera
Luz ámbar fija si el sistema está en espera. Luz verde fija si el sistema tiene potencia máxima.
Error del
módulo
Una luz ámbar indica que hay una falla en un módulo de controladora, IOM, PSU o FCM. Compruebe el LED de cajón para
obtener indicaciones de una falla de disco.
Estado lógico Una luz ámbar fija indica que hay una falla que no es de firmware (normalmente un disco, un HBA o una controladora
RAID interna o externa). Verifique los LED de cajón para ver indicaciones de falla de disco. Consulte LED del cajón del
gabinete 5U84 en la página 38.
Falla del
cajón 0
Una luz ámbar fija indica que hay una falla de sideplane, cable o disco en el cajón 0. Abra el cajón y verifique los DDIC en
busca de fallas.
Falla del
cajón 1
Una luz ámbar fija indica que hay una falla de sideplane, cable o disco en el cajón 1. Abra el cajón y verifique los DDIC en
busca de fallas.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en caliente y no los puede reparar el
cliente.
LED del cajón del gabinete 5U84
Consulte Cajones de gabinete 5U84 en la página 20 para obtener una descripción visual de las inserciones de LED de cajón en cada bisel
de cajón.
Tabla 18. Estados del LED del cajón
LED Estado/descripción
Sideplane en
buen estado/
buena
alimentación
Luz verde fija si el sideplane está funcionando y no hay problemas de alimentación.
Falla de cajón Luz ámbar fija si un componente de cajón ha fallado. Si el componente fallido es un disco, el LED del DDIC fallido se
iluminará en color ámbar fijo. Siga el procedimiento que se indica en Reemplazo de una DDIC en un gabinete de 5U en la
página 52. Si los discos están en buen estado, comuníquese con su proveedor de servicios para identificar la causa de la
falla y solucionar el problema.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en caliente y no los
puede reparar el cliente.
Falla lógica Ámbar (fijo) indica una falla de disco. Ámbar (parpadeante) indica que uno o varios sistemas de almacenamiento se
encuentran en estado afectado.
Falla de cable Una luz ámbar fija indica que el cableado entre el cajón y la parte posterior del gabinete ha fallado. Comuníquese con su
proveedor de servicios para solucionar el problema.
Gráfico de
barra de
actividad
Se muestra la cantidad de I/O de datos desde cero segmentos iluminados (sin I/O) hasta seis segmentos iluminados (I/O
máxima).
LED del DDIC del gabinete 5U84
La DDIC es compatible con discos LFF de 3.5 pulgadas y discos SFF de 2.5 pulgadas. En la ilustración a continuación, se muestra el panel
superior de la DDIC, como se ve cuando el disco está alineado para la inserción en una ranura de cajón.
38
Solución de problemas

Ilustración 36. LED: DDIC; ranura de disco de gabinete 5U en cajón
1. Pestillo deslizante (se desliza hacia la izquierda)
2. Botón de liberación (se muestra en posición de bloqueo)
3. LED de error de unidad
Tabla 19. Estados del LED de la DDIC
LED de error (ámbar) Estado/descripción*
Apagado Apagado (gabinete/módulo de disco)
Apagado Ausente
Parpadeante: 1 s
encendido/1 s apagado
Identificar
Cualquier vínculo
desactivado: encendido
Vínculo de unidad (canal PHY) desactivado
Encendido Falla (sobrante/fallido/bloqueado)
Apagado Disponible
Apagado Sistema de almacenamiento: iniciando
Apagado Sistema de almacenamiento: tolerante a fallas
Apagado Sistema de almacenamiento: degradado (no crítico)
Parpadeante: 3 s
encendido/1 s apagado
Sistema de almacenamiento: degradado (crítico)
Apagado Sistema de almacenamiento: en cuarentena
Parpadeante: 3 s
encendido/1 s apagado
Sistema de almacenamiento: offline (fuera de cuarentena)
Apagado Sistema de almacenamiento: reconstrucción
Apagado I/O de procesamiento (desde el host o actividad interna)
* Si se producen varias condiciones simultáneamente, el LED de estado se comportará como se indica en la condición enumerada antes
en la tabla, leyendo las filas de arriba hacia abajo.
Cada DDIC tiene un solo LED de error de unidad. Si el LED de error de unidad se ilumina en color ámbar fijo, se indica una falla de unidad de
disco. Si hay una falla de disco, siga el procedimiento que se indica en Reemplazo de una DDIC en un gabinete de 5U en la página 52.
LED del módulo de la controladora de 5U84 y del IOM
El módulo de la controladora y los CRU de IOM son comunes a los gabinetes 2U y 5U84.
● Para obtener información sobre los LED del módulo de la controladora, consulte LED del módulo de controladora de 12 Gb/s en la
página 24.
● Para obtener información sobre los LED del IOM, consulte LED del IOM del gabinete de expansión 2U en la página 36.
Solución de problemas de gabinetes 2U
En las secciones a continuación, se describen problemas comunes que pueden producirse con su sistema de gabinete y algunas soluciones
posibles. Para todos los problemas enumerados en la siguiente tabla, el LED de error del módulo en el panel del operador se iluminará en
color ámbar fijo para indicar una falla. Las alarmas también se informan mediante SES.
Solución de problemas
39

Tabla 20. Condiciones de alarma de 2U
Estado Gravedad Alarma
Alerta de PCM: pérdida de alimentación de CC desde una
única PCM
Falla: pérdida de redundancia S1
Falla del ventilador de PCM Falla: pérdida de redundancia S1
Falla de PCM detectada de módulo de SBB Falla S1
Se quitó el PCM Error de configuración Ninguno
Error de configuración del gabinete (VPD) Falla: crítica S1
Alerta de temperatura de nivel bajo Aviso S1
Alerta de temperatura de nivel alto Aviso S1
Alarma de temperatura superior al límite Falla: crítica S4
Falla en el bus I
2
C Falla: pérdida de redundancia S1
Error de comunicación de panel del operador (I
2
C) Falla: crítica S1
Error de RAID Falla: crítica S1
Falla del módulo de interfaz de SBB Falla: crítica S1
Se quitó el módulo de interfaz de SBB Aviso Ninguno
Falla del control de alimentación de unidad Advertencia: no hay pérdida
de alimentación de discos
S1
Falla del control de alimentación de unidad Falla: pérdida de
alimentación de discos
(crítica)
S1
Se ha extraído la unidad Aviso Ninguno
No hay suficiente alimentación disponible Aviso Ninguno
Para obtener detalles sobre el reemplazo de módulos, consulte Reemplazo de un módulo de controladora o IOM en un gabinete de 2U o
5U en la página 62 .
NOTA:
Mediante el PowerVault Manager, supervise los registros de eventos del sistema de almacenamiento para obtener
información sobre eventos relacionados con el gabinete y para determinar cualquier acción recomendada necesaria.
Fallas de PCM
Tabla 21. Acciones recomendadas de PCM
Síntoma Causa Acción recomendada
El LED de error de módulo del panel del operador
se ilumina en color ámbar fijo
1
Cualquier falla de alimentación Verifique que las conexiones de redes principales
de CA al PCM se muestren en tiempo real
El LED de falla del ventilador se ilumina en el
PCM
2
Error del ventilador Reemplace el PCM
1. Consulte LED del módulo de controladora de 12 Gb/s en la página 24 para obtener una referencia visual del LED del panel del operador.
2. Consulte Estados de LED de PCM en la página 34 para obtener una referencia visual de los LED del PCM.
Control térmico y supervisión térmica
El sistema del gabinete de almacenamiento utiliza supervisión térmica extensa y requiere de un número de acciones para asegurar que las
temperaturas de componentes se mantengan bajas, y minimizar el ruido acústico. El flujo de aire va desde adelante hacia atrás del
gabinete.
40
Solución de problemas

Tabla 22. Acciones recomendadas de monitoreo térmico
Síntoma Causa Acción recomendada
Si la temperatura ambiente es
menor a 25 °C (77 °F) y se
puede apreciar que los
ventiladores aumentan la
velocidad, algunas restricciones
en el flujo de aire pueden causar
un aumento de temperatura
interna adicional.
NOTA: Esta no es una
condición de falla.
La primera fase en el proceso de
control térmico es que los
ventiladores aumenten de velocidad
automáticamente cuando se alcanza
un umbral térmico. Esto puede ser
causado por temperaturas ambiente
más altas en el ambiente local y puede
ser perfectamente normal.
NOTA: Este umbral cambia según
el número de discos y las fuentes
de alimentación instaladas.
1. Verifique la instalación para observar cualquier restricción
de flujo de aire en la parte frontal o posterior del gabinete.
Se recomienda una separación mínima de 25 mm
(1 pulgada) en la parte frontal y 50 mm (2 pulgadas) en la
parte posterior.
2. Verifique si hay restricciones debido a acumulación de
polvo. Limpie como corresponda.
3. Compruebe si hay una recirculación excesiva de aire
caliente desde la parte posterior hacia la parte frontal. No
se recomienda usar el gabinete en un rack completamente
cerrado.
4. Verifique que todos los módulos de relleno estén en su
lugar.
5. Reduzca la temperatura ambiente.
Alarma térmica
Tabla 23. Acciones recomendadas de alarma térmica
Síntoma Causa Acción recomendada
1. El LED de error del módulo del
panel del operador se ilumina en
color ámbar fijo.
2. El LED de error del ventilador se
ilumina en uno o más PCM.
La temperatura interna
excede el límite
preestablecido para el
gabinete.
1. Verifique que la temperatura ambiente local esté en el rango
aceptable. Consulte también Requisitos del entorno en la
página 160.
2. Verifique la instalación para observar cualquier restricción de
flujo de aire en la parte frontal o posterior del gabinete. Se
recomienda una separación mínima de 25 mm (1 pulgada) en la
parte frontal y 50 mm (2 pulgadas) en la parte posterior.
3. Verifique si hay restricciones debido a acumulación de polvo.
Limpie como corresponda.
4. Compruebe si hay una recirculación excesiva de aire caliente
desde la parte posterior hacia la parte frontal. No se
recomienda usar el gabinete en un rack completamente
cerrado.
5. Si es posible, apague el gabinete e investigue el problema antes
de continuar.
Solución de problemas de gabinetes 5U
En la tabla, se describen problemas comunes que pueden producirse con el sistema de gabinete, junto con las posibles soluciones. Para
todos los problemas que se indican en la tabla a continuación, el LED de error del módulo en el panel del operador se iluminará en color
amarillo fijo para indicar una falla. Todas las alarmas se informarán también a través de SES.
Tabla 24. Condiciones de alarma 5U
Estado Gravedad
Alerta de PSU: pérdida de alimentación de CC de una PSU
única
Falla: pérdida de redundancia
Falla del ventilador del módulo de enfriamiento Falla: pérdida de redundancia
Falla de PSU detectada de módulo de I/O de SBB Falla
Se quitó la PSU Error de configuración
Error de configuración del gabinete (VPD) Falla: crítica
Advertencia de temperatura baja Aviso
Solución de problemas 41

Tabla 24. Condiciones de alarma 5U (continuación)
Estado Gravedad
Aviso de temperatura elevada Aviso
Alarma de exceso de temperatura Falla: crítica
Baja: alarma de temperatura Falla: crítica
Falla en el bus I
2
C Falla: pérdida de redundancia
Error de comunicación de panel del operador (I
2
C) Falla: crítica
Error de RAID Falla: crítica
Falla del módulo de I/O de SBB Falla: crítica
Se quitó el módulo de I/O de SBB Aviso
Falla del control de alimentación de unidad Advertencia: no hay pérdida de alimentación de unidad
Falla del control de alimentación de unidad Falla: pérdida de alimentación de la unidad (crítica)
No hay suficiente alimentación disponible Aviso
Consideraciones térmicas
Los sensores térmicos en el gabinete 5U84 y sus componentes supervisan el estado térmico del sistema de almacenamiento.
NOTA:
● Superar los límites de valores críticos activará la alarma de temperatura superior al límite.
● Para obtener más información sobre la notificación de alarma del gabinete 5U84, consulte Condiciones de alarma 5U en la página
41.
Conexiones de puerto de CLI
Las controladoras de sistema de almacenamiento de ME4 Series tienen un puerto de CLI con un enchufe estéreo de 3.5 mm y un factor
de forma miniUSB de tipo B. Para obtener más información sobre la conexión de un cable en serie, consulte Conexión del puerto de la CLI
mediante un cable en serie en la página 154.
Sensores de temperatura
Los sensores de temperatura a lo largo del gabinete y sus componentes supervisan la condición térmica del sistema de almacenamiento.
Exceder los límites de valores críticos hace que aparezca una notificación.
I/O del host
Al solucionar problemas de la unidad de disco y fallas de conectividad, detenga la actividad de I/O en los grupos de discos afectados de
todos los hosts como una precaución de protección de datos. Como medida de protección de datos adicional, es útil realizar respaldos
periódicos programados de los datos. Consulte Apagado de los hosts conectados en la página 45.
42
Solución de problemas

Reemplazo y extracción del módulo
En este capítulo, se proporcionan procedimientos para reemplazar CRU (unidades que puede reemplazar el cliente), incluyendo
precauciones, instrucciones de extracción, instrucciones de instalación y verificación de instalación exitosa. Cada procedimiento se refiere
a una tarea específica.
Temas:
• Precauciones ante descargas electroestáticas (ESD)
• Reparación de fallas de hardware
• Actualizaciones de firmware
• Funcionamiento continuo durante el reemplazo
• Apagado de los hosts conectados
• Apagado de un módulo de controladora
• Verificación de falla de componente
• Las unidades que puede reemplazar el cliente (CRU)
• Verificación del funcionamiento de componentes
• Actualizaciones en el PowerVault Manager después de reemplazar un HBA de SAS o FC
Precauciones ante descargas electroestáticas (ESD)
Antes de comenzar cualquiera de los procedimientos, tenga en cuenta las siguientes precauciones y medidas preventivas.
Prevención de descargas electrostáticas
Para evitar que las descargas electrostáticas (ESD) dañen el sistema, tenga en cuenta las precauciones que debe tener en cuenta a la hora
de instalar el sistema o manejar los componentes. Una descarga de electricidad estática de un dedo u otro conductor puede dañar las
tarjetas madres del sistema u otros dispositivos sensibles a la estática. Este tipo de daño puede reducir la vida útil del dispositivo.
PRECAUCIÓN:
La descarga electrostática puede dañar las piezas. Tome las siguientes precauciones:
● Transporte y almacene los productos en contenedores protegidos contra electricidad estática para evitar el contacto
con las manos.
● Mantenga las partes sensibles a la electricidad estática en sus contenedores hasta que lleguen a estaciones de
trabajo protegidas.
● Coloque las piezas en un área protegida contra la electricidad estática antes de quitarlas de sus contenedores.
● Evite tocar las clavijas, los cables o los circuitos.
● Cuando toque un ensamblaje o componente sensible a la electricidad estática, conéctese a tierra adecuadamente.
● Quite los restos de materiales (plástico, vinilo, espuma) de la estación de trabajo protegida contra la electricidad
estática.
Métodos de conexión a tierra para evitar descargas electrostáticas
Se utilizan varios métodos de conexión a tierra. Siga las siguientes precauciones cuando maneje o instale piezas sensibles a la electricidad
estática.
PRECAUCIÓN:
Las descargas electrostáticas pueden dañar las piezas. Utilice protección antiestática adecuada:
● Mantenga la CRU de repuesto en la bolsa contra ESD hasta que sea necesario. Cuando quite una CRU del gabinete,
colóquela inmediatamente en la bolsa contra ESD y el embalaje antiestático.
3
Reemplazo y extracción del módulo 43

● Use una muñequera contra ESD conectada por un cable a tierra a una superficie sin pintar o estación de trabajo
conectada a tierra del chasis de la computadora. Las muñequeras son correas flexibles con una resistencia mínima de
1 megaohmio (± 10 por ciento) en los cables de conexión a tierra. Utilice la correa bien pegada a la piel para lograr una
conexión a tierra adecuada.
● Si no hay una muñequera contra ESD disponible, toque una superficie del chasis sin pintar antes de manejar el
componente.
● Utilice correas en los talones, los dedos o las botas en estaciones de trabajo de pie. Colóquese las correas en ambos
pies cuando se pare en pisos conductivos o alfombras disipadoras.
● Utilice herramientas de servicio en el campo conductoras
● Utilice un kit de servicio de campo portátil con una alfombra de trabajo disipadora plegable.
Si no tiene ninguno de los equipos sugeridos para conexión a tierra adecuada, pídale a un técnico autorizado que instale la pieza. Para
obtener más información acerca de la electricidad estática o para obtener asistencia con la instalación del producto, comuníquese con el
soporte al cliente. Para obtener información adicional, consulte www.dell.com/support.
Reparación de fallas de hardware
Asegúrese de tener un módulo de repuesto del mismo tipo antes de quitar cualquier módulo fallido.
PRECAUCIÓN:
● Si el sistema del gabinete está encendido y quita cualquier módulo, reemplácelo de inmediato. Si el sistema de
gabinete se utiliza con algún módulo faltante durante demasiado tiempo, los gabinetes se pueden sobrecalentar y
ocasionar una falla de alimentación y una posible pérdida de datos. Dicho uso puede invalidar la garantía del producto.
● Tenga en cuenta precauciones contra ESD aplicables/convencionales cuando maneje módulos y componentes, como
se describe en Reemplazo de módulos de controladora en un gabinete de módulo de controladora doble en la página
63. Evite el contacto con componentes del midplane, conectores del módulo, guías, clavijas y circuitos expuestos.
Actualizaciones de firmware
Después de instalar el hardware y encender los componentes del sistema de almacenamiento por primera vez, compruebe que los módulos
de la controladora, los módulos de expansión y las unidades de disco estén utilizando la versión actual del firmware. Periódicamente,
asegúrese de que las versiones de firmware que se usan en los módulos del gabinete sean compatibles.
Configuración de la actualización de firmware asociado
En un sistema de controladora doble en el que está habilitada la actualización del firmware (PFU) asociado, cuando se actualiza el firmware
en una controladora, el sistema actualiza automáticamente la controladora asociada. Deshabilite PFU solo si lo solicita un técnico de
servicio. Utilice el PowerVault Manager o la CLI para cambiar la configuración de PFU.
NOTA:
● Consulte el tema sobre la actualización de firmware en la Guía del administrador del sistema de almacenamiento de Dell EMC
PowerVault ME4 Series antes de realizar una actualización de firmware.
● El PowerVault Manager y la CLI proporcionan una opción para habilitar o deshabilitar el PFU para la controladora asociada, como
se describe en la Guía del administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series. Para habilitar o
deshabilitar la configuración a través de la CLI, utilice el comando set advanced-settings y configure el parámetro partner-
firmware-upgrade. Consulte la Guía de la CLI del sistema de almacenamiento de Dell EMC PowerVault ME4 Series para obtener
más información acerca de la sintaxis de parámetros del comando.
Funcionamiento continuo durante el reemplazo
La aplicación de administración del gabinete de hardware o software determina la capacidad para reemplazar un disco fallido sin pérdida de
acceso a ningún sistema de archivos en el gabinete. El acceso al gabinete y su uso durante este período no se interrumpen. Si un gabinete
dispone de PCM o PSU redundantes, se proporciona suficiente alimentación al sistema mientras se reemplaza el módulo defectuoso.
44
Reemplazo y extracción del módulo

NOTA: Los gabinetes de sistema de almacenamiento ME4 Series admiten el reemplazo en caliente de módulos de controladoras
redundantes, fuentes de alimentación y módulos de expansión. También se admite el reemplazo en caliente de los gabinetes de
expansión.
Apagado de los hosts conectados
Para reemplazar módulos en un gabinete de controladora 2U que tenga un módulo de controladora, debe apagar todos los hosts
conectados antes de apagar el módulo de controladora.
Para reemplazar el sideplane en un gabinete 5U84, debe apagar todos los hosts conectados antes de apagar los módulos de controladora.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en caliente y no los puede reparar el
cliente.
Apagado de un módulo de controladora
Apagar el módulo de controladora en un gabinete garantiza que se use una conmutación por errores adecuada, que incluye detener todas
las operaciones de I/O y la escritura de datos en la caché de escritura en disco. Realice un apagado antes de quitar un módulo de
controladora de un gabinete o antes de apagar un gabinete para mantenimiento, reparación o traslado.
Uso del PowerVault Manager
1. Inicie sesión en el PowerVault Manager.
2. En el panel Sistema, en el banner, haga clic en Restart System (Reiniciar el sistema).
Se abren los paneles Reinicio de la controladora y Apagado.
3. Seleccione la operación Apagado, que selecciona automáticamente el tipo de controladora tipo de almacenamiento.
4. Seleccione el módulo de controladora que desea apagar: A, B o ambas.
5. Haga clic en OK (Aceptar). Aparece un panel de confirmación.
6. Haga clic en Sí para continuar: de lo contrario, haga clic en No. Si hizo clic en Sí, un mensaje describe la actividad de apagado.
NOTA:
● Si un puerto iSCSI está conectado a un host de Microsoft Windows, el siguiente evento se registra en el registro de eventos de
Windows: El iniciador no pudo conectarse al destino.
● Consulte la Guía del administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series para obtener información
adicional.
Mediante la CLI.
1. Inicie sesión en la CLI.
2. En el sistema de controladora doble, compruebe que la controladora asociada esté en línea mediante la ejecución del comando: mostrar
controladoras.
3. Apague la controladora fallida (A o B) mediante el comando shutdown a o shutdown b
Se ilumina el LED azul de OK para extraer (parte posterior del gabinete) que indica que el módulo de la controladora puede extraerse
sin problemas.
4. Ilumine el LED identificador blanco del gabinete que contiene el módulo de controladora que desea quitar mediante el comando set
led enclosure 0 on
El LED de la pantalla en el panel del operador ubicado en la orejeta izquierda del gabinete parpadeará en color verde cuando se invoque
el comando set led enclosure 0 on.
NOTA:
Consulte la Guía de la CLI del sistema de almacenamiento de Dell EMC PowerVault ME4 Series para obtener información
adicional.
Reemplazo y extracción del módulo 45

Verificación de falla de componente
Elija uno de los siguientes métodos para verificar una falla del componente:
● Utilice el PowerVault Manager para verificar los íconos o valores de estado del sistema y sus componentes para asegurarse de que
todo esté en condiciones o para desglosar un componente que presenta problemas. El PowerVault Manager utiliza los iconos para
mostrar los estados de Buen estado, Deteriorado, Error o Desconocido para el sistema y sus componentes. Si detecta un componente
con problemas, siga las acciones del campo Recomendación para resolver el problema.
● Otra alternativa al uso de PowerVault Manager es ejecutar el comando del sistema para mostrar la CLI y ver el estado del sistema y sus
componentes. Si algún componente presenta un problema, el estado del sistema se muestra como Degraded, Fault o Unknown. Si
descubre un componente con inconvenientes, sigas las acciones del campo Recomendaciones de estado para resolver el problema.
●
Monitorear la notificación de eventos: si tiene configurada y activada la notificación de eventos, use el PowerVault Manager para ver el
registro de eventos o ejecute el comando de detalles de evento para mostrar la CLI y ver los detalles de los eventos.
● Verifique el LED de error (parte posterior del gabinete en el módulo de controladora o placa frontal del IOM): Ámbar = Condición de
falla.
● Compruebe que el LED de buen estado (parte posterior del gabinete) está apagado.
Las unidades que puede reemplazar el cliente (CRU)
En las siguientes tablas, se describen los tipos de gabinetes de controladora de ME4 Series:
NOTA: Consulte Producto principal del gabinete 2U en la página 11 y Producto principal del gabinete 5U84 en la página 15 para
obtener vistas del módulo de la controladora y las CRU de IOM utilizadas en los distintos factores de forma de gabinete, compatibles
con sistemas de almacenamiento de la ME4 Series.
Tabla 25. Modelos de gabinete de controladora 2U de ME4 Series
Modelo Descripción Factor de forma Unidades
ME4012 Fibre Channel (16 Gbps) SFP
1, 3
2U12 Hasta 12 unidades de 3,5 pulgadas
(LFF)
ME4012 iSCSI (10 GbE) SFP
2, 3
2U12 Hasta 12 unidades de 3,5 pulgadas
(LFF)
ME4012 iSCSI 10Gbase-T (10 Gbps o 1 Gbps)
4
2U12 Hasta 12 unidades de 3,5 pulgadas
(LFF)
ME4012 MiniSAS HD (12 Gbps)
5
2U12 Hasta 12 unidades de 3,5 pulgadas
(LFF)
ME4024 Fibre Channel (16 Gbps) SFP
1, 3
2U24 Hasta 24 unidades de 2,5 pulgadas
(SFF)
ME4024 iSCSI (10 GbE) SFP
2, 3
2U24 Hasta 24 unidades de 2,5 pulgadas
(SFF)
ME4024 iSCSI 10Gbase-T (10 Gbps o 1 Gbps)
4
2U24 Hasta 24 unidades de 2,5 pulgadas
(SFF)
ME4024 MiniSAS HD (12 Gbps)
5
2U24 Hasta 24 unidades de 2,5 pulgadas
(SFF)
1-Este modelo utiliza una opción de SFP de FC calificada dentro de los puertos CNC (utilizados para conexiones de host). Cuando se
encuentre en el modo FC, los SFP deben ser una opción de fibra óptica calificada de 16 Gb. A 16 Gbps, SFP puede ejecutarse a 16 Gbps,
8 Gbps, 4 Gbps, o negociar automáticamente la velocidad de enlace.
2-Este modelo utiliza una opción de iSCSI de 10 GbE calificada dentro de los puertos CNC del módulo de controladora (utilizada para
conexiones de host).
3-Los puertos CNC admiten el mismo tipo o un tipo combinado de SFP,
4-Este modelo soporta velocidades de 10 Gbps o 1 Gbps (utilizadas para conexiones de host de iSCSI).
5-Este modelo utiliza conectores SFF-8644 y opciones de cable calificadas para conexiones de host.
46
Reemplazo y extracción del módulo

Tabla 26. Modelos de gabinete de controladora de 5U de alta densidad de ME4 Series
Modelo Descripción Factor de forma Unidades
ME4084 Canal de fibra (16 Gb/s) SFP
1,3
5U84 Hasta 84 unidades de 2,5 pulgadas
(SFF) o 3,5 pulgadas (LFF)
ME4084 iSCSI (10GbE) SFP
2, 4
5U84 Hasta 84 unidades de 2,5 pulgadas
(SFF) o 3,5 pulgadas (LFF)
ME4084 iSCSI 10Gbase-T (10 Gbps o 1 Gbps)
4
5U84 Hasta 84 unidades de 2,5 pulgadas
(SFF) o 3,5 pulgadas (LFF)
ME4084 MiniSAS HD (12 Gbps)
5
5U84 Hasta 84 unidades de 2,5 pulgadas
(SFF) o 3,5 pulgadas (LFF)
1-Este modelo utiliza una opción de SFP de FC calificada dentro de los puertos CNC (utilizados para la conexión del host). Cuando se
encuentre en el modo FC, los SFP deben ser una opción de fibra óptica calificada de 16 Gb. A 16 Gbps, SFP puede ejecutarse a 16 Gbps,
8 Gbps, 4 Gbps, o negociar automáticamente la velocidad de enlace.
2-Este modelo utiliza una opción de iSCSI de 10 GbE calificada dentro de los puertos CNC del módulo de controladora (utilizada para la
conexión del host).
3-Los puertos CNC admiten el mismo tipo o un tipo combinado de SFP,
4-Este modelo soporta velocidades de 10 Gbps o 1 Gbps (utilizadas para la conexión del host de iSCSI).
5-Este modelo utiliza conectores SFF-8644 y opciones de cable calificadas para la conexión del host.
Conectar o quitar el bisel frontal de un gabinete de 2U
En la siguiente ilustración, se muestra una vista parcial de un gabinete de 2U12:
Ilustración 37. Conexión o extracción del bisel frontal del gabinete de 2U
Para conectar el bisel frontal al gabinete de 2U, realice lo siguiente:
1. Localice el bisel y, mientras lo sostiene con las manos, póngalo de frente al panel frontal del gabinete de 2U12 o 2U24.
2. Enganche el extremo derecho del bisel en la cubierta de la orejeta derecha del sistema de almacenamiento.
3. Introduzca el extremo izquierdo del bisel en la ranura de fijación hasta que el pestillo de liberación encaje en su lugar.
4. Fije el bisel con la cerradura, como se muestra en Conexión o extracción del bisel frontal del gabinete 2U.
Para quitar el bisel del gabinete 2U, invierta el orden de los pasos anteriores.
NOTA: Consulte Variantes de gabinete para obtener detalles sobre varias opciones de gabinete .
Reemplazo de un módulo de portaunidades en un gabinete de 2U
En la sección, se describe cómo reemplazar un módulo de portaunidades en un gabinete de 2U.
Un módulo de portaunidades es una unidad de disco instalada en un módulo de portaunidades. Los módulos de portaunidades son
intercambiables en caliente, lo que significa que se pueden reemplazar sin detener la I/O a los grupos de discos y sin apagar el gabinete. La
nueva unidad de disco debe ser del mismo tipo y debe contener una capacidad igual o superior a la de la unidad que se reemplaza. De lo
contrario, el sistema de almacenamiento no podrá usar la nueva unidad de disco para reconstruir el grupo de discos.
Reemplazo y extracción del módulo
47

PRECAUCIÓN:
● Quitar un módulo de portaunidades afecta el flujo de aire y la capacidad de enfriamiento del gabinete. Si la
temperatura interna supera los límites aceptables, el gabinete podría sobrecalentarse y apagarse o reiniciarse
automáticamente.
● Cuando quite un módulo de portaunidades, espere 30 segundos después de desenganchar el módulo de
portaunidades para que la unidad de disco deje de girar.
NOTA:
● Familiarícese con las consideraciones sobre el cifrado de disco completo (FDE) relacionadas con la instalación y el reemplazo de
unidades de disco.
● Cuando mueva unidades de disco con capacidad para FDE para un grupo de discos, detenga la I/O al grupo de discos antes de
quitar los módulos de portaunidades. Importe las claves para las unidades de disco para que el contenido del disco esté disponible.
Consulte la Guía del administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series o la Guía de la CLI del
sistema de almacenamiento de Dell EMC PowerVault ME4 Series para obtener más información.
Antes de comenzar cualquiera de los procedimientos, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
Reemplazo de un módulo de portaunidades de LFF
Los procedimientos de reemplazo de módulos de portaunidades de LFF son los mismos que los de los módulos de SFF, con la excepción de
que los módulos de portaunidades de LFF se montan horizontalmente.
Extracción de un módulo de portaunidades de LFF
Realice los siguientes pasos para quitar un módulo de portaunidades de LFF de un gabinete de 2U:
1. Presione el pestillo en el portaunidades del módulo de unidad para abrir el asa.
Ilustración 38. Extracción de un módulo de portaunidades de LFF (1 de 2)
2. Mueva con cuidado el módulo del portaunidades aproximadamente 25 mm (1 pulgada) y espere 30 segundos hasta que la unidad deje
de girar.
48
Reemplazo y extracción del módulo

Ilustración 39. Extracción de un módulo de portaunidades de LFF (2 de 2)
3. Quite el módulo del portaunidades de la ranura de unidad.
PRECAUCIÓN: Para garantizar un enfriamiento óptimo en todo el gabinete, se deben instalar módulos de
portaunidades de relleno en todas las ranuras de unidad sin utilizar.
Instalación de un módulo de portaunidades de LFF
Realice los siguientes pasos para instalar un módulo de portaunidades de LFF en un gabinete de 2U:
1. Presione el pestillo en el portaunidades del módulo de unidad para abrir el asa.
Ilustración 40. Módulo del portaunidades LFF en posición abierta
2. Inserte el módulo del portaunidades en el gabinete.
3. Deslice suavemente el módulo del portaunidades en el gabinete hasta que deje de moverse.
Ilustración 41. Instalación de un módulo de portaunidades de LFF (1 de 2)
4. Empuje el módulo del portaunidades hacia el interior del gabinete hasta que el asa del pestillo empiece a engancharse.
Reemplazo y extracción del módulo
49

5. Continúe empujando firmemente hasta que el asa del pestillo se enganche por completo. Debería oír un clic cuando el asa del pestillo se
enganche y mantenga el asa cerrada.
Ilustración 42. Instalación de un módulo de portaunidades de LFF (2 de 2)
6. Utilice el PowerVault Manager o la CLI para verificar lo siguiente:
● La unidad de disco nueva está en buen estado
● El LED verde de actividad de disco está encendido/parpadeante
● Los estados del panel de operaciones no muestran errores de módulo en color ámbar.
Reemplazo de un módulo de portaunidades de SFF
Los procedimientos de reemplazo de módulos de portaunidades de SFF son los mismos que los de los módulos de LFF, con la excepción de
que los módulos de portaunidades de SFF se montan verticalmente.
Extracción de un módulo de portaunidades de SFF
Realice los siguientes pasos para quitar un módulo de portaunidades de SFF de un gabinete de 2U:
1. Presione el pestillo en el portaunidades del módulo de unidad para abrir el asa.
Ilustración 43. Extracción de un módulo de portaunidades de SFF (1 de 2)
2. Mueva con cuidado el módulo del portaunidades aproximadamente 25 mm (1 pulgada) y espere 30 segundos hasta que la unidad deje
de girar.
50
Reemplazo y extracción del módulo

Ilustración 44. Extracción de un módulo de portaunidades de SFF (2 de 2)
3. Quite el módulo del portaunidades de la ranura de unidad.
PRECAUCIÓN: Para garantizar un enfriamiento óptimo en todo el gabinete, se deben instalar módulos de
portaunidades de relleno en todas las ranuras de unidad sin utilizar.
Instalación de un módulo de portaunidades de SFF
Realice los siguientes pasos para instalar un módulo de portaunidades de SFF en un gabinete de 2U:
1. Presione el pestillo en el portaunidades del módulo de unidad para abrir el asa.
Ilustración 45. Módulo del portaunidades SFF en posición abierta
2. Inserte el módulo del portaunidades en el gabinete.
3. Deslice suavemente el módulo del portaunidades en el gabinete hasta que deje de moverse.
Reemplazo y extracción del módulo
51

Ilustración 46. Instalación de un módulo de portaunidades de SFF (1 de 2)
4. Empuje el módulo del portaunidades hacia el interior del gabinete hasta que el asa del pestillo empiece a engancharse.
5. Continúe empujando firmemente hasta que el asa del pestillo se enganche por completo. Debería oír un clic cuando el asa del pestillo se
enganche y mantenga el asa cerrada.
Ilustración 47. Instalación de un módulo de portaunidades de SFF (2 de 2)
6. Utilice el PowerVault Manager o la CLI para verificar lo siguiente:
● La unidad de disco nueva está en buen estado
● El LED verde de actividad de disco está encendido/parpadeante
● Los estados del panel de operaciones no muestran errores de módulo en color ámbar.
Reemplazo de un módulo de portaunidades de relleno
Instale módulos de portaunidades de relleno en todas las ranuras de unidad sin utilizar para garantizar un enfriamiento óptimo en todo el
gabinete.
Para quitar un módulo de portaunidades de relleno, presione el pestillo del módulo y tire del módulo para quitarlo de la ranura de unidad.
Para instalar un módulo de portaunidades de relleno, inserte el módulo en la ranura de unidad y empuje el módulo en la ranura para fijarlo en
su lugar.
Reemplazo de una DDIC en un gabinete de 5U
En esta sección, se describe cómo reemplazar una unidad de disco en portaunidades (DDIC) en un gabinete de 5U.
Una DDIC es una unidad de disco instalada en un módulo de portaunidades. Las DDIC son intercambiables en caliente, lo que significa que
se pueden reemplazar sin detener la I/O a los grupos de discos y sin apagar el gabinete. La nueva unidad de disco debe ser del mismo tipo
52
Reemplazo y extracción del módulo

y debe contener una capacidad igual o superior a la de la unidad que se reemplaza. De lo contrario, el sistema de almacenamiento no podrá
usar la nueva unidad de disco para reconstruir el grupo de discos.
PRECAUCIÓN:
● Quitar una DDIC afecta el flujo de aire y la capacidad de enfriamiento del gabinete. Si la temperatura interna supera
los límites aceptables, el gabinete podría sobrecalentarse y apagarse o reiniciarse automáticamente.
● Cuando quite una DDIC, espere 30 segundos después de desbloquear la DDIC de su posición asentada para que la
unidad de disco deje de girar.
NOTA:
● Familiarícese con las consideraciones sobre el cifrado de disco completo (FDE) relacionadas con la instalación y el reemplazo de
unidades de disco.
● Cuando mueva unidades de disco con capacidad para FDE para un grupo de discos, detenga la I/O al grupo de discos antes de
quitar las DDIC. Importe las claves para las unidades de disco para que el contenido del disco esté disponible. Consulte la Guía del
administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series o la Guía de la CLI del sistema de
almacenamiento de Dell EMC PowerVault ME4 Series para obtener más información.
Antes de comenzar cualquiera de los procedimientos, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
Acceso a los cajones de un chasis 5U84
El procedimiento de reemplazo para las DDIC se debe realizar en un plazo de dos minutos a partir de la apertura de un cajón.
Apertura de un cajón
1. Asegúrese de que los bloqueos antimanipulación no estén activados. Las flechas rojas de los bloqueos apuntan hacia dentro si estos no
están activados, como se muestra en la siguiente ilustración. Si fuera necesario, gírelos en el sentido contrario a las agujas del reloj con
un destornillador de punta Torx T20 para desbloquearlos.
Ilustración 48. Detalles del panel frontal del cajón
1.
Lado izquierdo 2. Lado derecho
3. Cerradura contra alteraciones 4. Sideplane en buen estado/buena alimentación
5. Falla de cajón 6. Falla lógica
7. Falla de cable 8. Actividad del cajón
9. Asa de tiro del cajón
2. Empuje los pestillos del cajón hacia adentro y manténgalos sujetados, como se muestra en la siguiente ilustración.
Reemplazo y extracción del módulo
53

Ilustración 49. Apertura de un cajón (1 de 2)
3. Tire del cajón hacia afuera hasta que se detenga en los topes, como se muestra en la siguiente ilustración.
El cajón se muestra vacío, que es la manera en que se entrega el gabinete. Hay un detalle del pestillo del riel deslizante del cajón
añadido.
Ilustración 50. Apertura de un cajón (2 de 2)
NOTA: El cajón no debe estar vacío durante más de dos minutos con el gabinete encendido.
Cierre de un cajón
1. Mantenga presionados los pestillos negros en los laterales del cajón abierto, en cada riel superior extendido.
En el diagrama anterior, se muestra un detalle aumentado de un pestillo de deslizamiento, que reside en los rieles del cajón izquierdo y
derecho.
2. Empuje el cajón ligeramente hacia adentro.
3. Suelte los pestillos del cajón.
4. Empuje el cajón completamente dentro del gabinete, asegurándose de que encaje hasta el fondo.
Extracción de una DDIC de un gabinete de 5U
Quite una DDIC solo si hay una DDIC de reemplazo disponible.
NOTA:
Es posible que cerrar un cajón con una o más DDIC faltantes cause problemas de enfriamiento. Consulte Ocupación de
cajones en la página 61.
1. Determine qué cajón contiene la unidad de disco que desea quitar.
● Si conoce el número de ranura, use Sistema de gabinete 5U84: plano del cajón accedido desde el panel frontal en la página 16, que
proporciona una vista de un cajón de índice doble con numeración de ranuras de cajón superior (entero izquierdo) y cajón inferior
(entero derecho).
● Si la unidad de disco ha fallado, se enciende un LED de error en el panel frontal del cajón afectado.
● Si la unidad de disco ha fallado, el LED de error de la unidad en la DDIC se ilumina con luz ámbar fija.
54
Reemplazo y extracción del módulo

2. Abra el cajón que contiene la DDIC que desea quitar.
3. Presione el botón de pestillo en la dirección de la siguiente ilustración para desbloquear la DDIC de la posición asentada en la ranura:
Ilustración 51. Extracción de una DDIC (1 de 2)
4. Tire de la DDIC hacia arriba y hacia fuera de la ranura del cajón.
Ilustración 52. Extracción de una DDIC (2 de 2)
Instalación de una unidad de disco de 2,5 pulgadas de reemplazo en una nueva
DDIC
Cada unidad de disco de reemplazo se envía con una nueva unidad de disco en portaunidades (DDIC).
Instale la unidad de disco de reemplazo en la nueva DDIC antes de abrir el cajón del gabinete para quitar la unidad fallida.
1. Instale la unidad de disco de reemplazo de 2,5 pulgadas en el adaptador de 3,5 pulgadas.
Reemplazo y extracción del módulo
55

2. Inserte el conector de SAS en la nueva DDIC.
3. Inserte el adaptador de 3,5 pulgadas con la unidad de disco de 2,5 pulgadas en la nueva DDIC y conecte la unidad de disco al conector
de SAS.
56
Reemplazo y extracción del módulo

4. Conecte el soporte inferior a la nueva DDIC.
5. Fije la unidad de disco en la nueva DDIC con los cuatro tornillos enviados con la nueva DDIC.
Reemplazo y extracción del módulo
57

6. Adhiera la etiqueta de tamaño de unidad de disco correspondiente a la parte superior de la nueva DDIC.
Instalación de una unidad de disco de repuesto de 3,5 pulgadas en una nueva
DDIC
Cada unidad de disco de reemplazo se envía con una nueva unidad de disco en portaunidades (DDIC).
Instale la unidad de disco de reemplazo en la nueva DDIC antes de abrir el cajón del gabinete para quitar la unidad fallida.
1. Quite el plástico protector de la nueva DDIC.
2. Inserte el conector de SAS en la nueva DDIC.
58
Reemplazo y extracción del módulo

3. Inserte la unidad de disco en la nueva DDIC y conecte la unidad de disco al conector de SAS. .
4. Conecte el soporte inferior a la nueva DDIC.
Reemplazo y extracción del módulo
59

5. Fije la unidad de disco en la nueva DDIC con los cuatro tornillos enviados con la nueva DDIC.
6. Adhiera la etiqueta de tamaño de unidad de disco correspondiente a la parte superior de la nueva DDIC.
60
Reemplazo y extracción del módulo

Instalación de una DDIC en un gabinete de 5U
Las unidades de disco fallidas se deben reemplazar por unidades de disco aprobadas. Comuníquese con el proveedor de servicios para
obtener más detalles.
1. Alinee la ranura de DDIC con la ranura de unidad de destino, como se muestra en Extracción de una DDIC (2 de 2) en la página 55, e
insértela en la ranura de unidad.
2. Baje la DDIC hacia la ranura de unidad.
a. Mantenga la DDIC presionado hacia abajo.
b. Mueva el pestillo de deslizamiento en la dirección que se muestra en la siguiente ilustración:
Ilustración 53. Instalación de una DDIC
a. Pestillo deslizante (se desliza hacia la izquierda)
b. Botón del pestillo (se muestra en la posición de bloqueo)
c. LED de error de unidad
3. Compruebe lo siguiente:
a. El botón del pestillo está en la posición de bloqueo.
b. El LED de error de la unidad no está encendido.
4. Cierre el cajón.
Ocupación de cajones
Las reglas generales para ocupar un cajón con DDIC se proporcionan en la Guía de implementación del sistema de almacenamiento de Dell
EMC PowerVault ME4 Series. Las reglas adicionales se proporcionan para reemplazar unidades de disco en cajones ocupados
anteriormente o para ocupar gabinetes enviados con la opción de configuración de gabinete a medio ocupar.
Preparación
Las unidades de disco se envían en paquetes de ampliación de 42 unidades. Los clientes con varios gabinetes podrán repartir las
42 unidades de disco de un paquete de expansión en varios gabinetes, siempre y cuando se instalen 14 DDIC cada vez para llenar
Reemplazo y extracción del módulo
61

completamente las filas vacías. En esta sección, se describe el patrón de instalación que proporciona el mejor flujo de aire y rendimiento
térmico posible.
Los cajones se deben ocupar con DDIC en filas completas. Cada cajón contiene 3 filas de 14 DDIC. Se enumeran las reglas y asunciones:
● El número mínimo de DDIC en un gabinete es 28.
● El número de filas no debe variar en más de 1 entre los cajones superior e inferior.
● Las filas se deben ocupar desde la parte frontal del cajón hacia la parte posterior del cajón
● Si se envía un segundo paquete de expansión de unidades de disco a un cliente, las unidades de disco del segundo paquete de
expansión deben coincidir con las unidades de disco que se enviaron originalmente con el gabinete 5U84. Ambos grupos de unidades
de disco deben compartir el mismo tipo de modelo y capacidad.
NOTA: Los números de referencia de los paquetes de expansión no aparecen en la lista porque cambian con el tiempo, cuando las
unidades de disco se envían con firmware nuevo o se encuentran disponibles nuevos modelos de unidad de disco. Comuníquese
con el administrador de cuentas para obtener los números de referencia.
● Si los dos grupos de unidades de disco tienen firmware diferente, todas las unidades de disco se deben actualizar con el firmware
actual/compatible. Consulte la Guía del administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series o la ayuda
en línea para obtener información adicional sobre la actualización de firmware.
Pautas para la instalación
El orden recomendado para ocupar unidades de disco parcialmente en el gabinete 5U84 optimiza el flujo de aire a través del chasis. En
Gabinete 5U84: componentes del panel frontal en la página 16, se muestra la ubicación y la indexación de los cajones a los que se accede
desde el panel frontal del gabinete.
El 5U84 se envía con cajones instalados en el chasis. Sin embargo, para evitar problemas de impacto y vibración durante el tránsito, el
gabinete no se envía con DDIC instalados en los cajones. Un gabinete se configura con 42 unidades de disco (a medio ocupar) u
84 unidades de disco (completamente ocupadas) para enviarlo al cliente. Si están a medio ocupar, las filas que contienen unidades de disco
se deben completar con un complemento total de DDIC (sin ranuras vacías en la fila). En la lista a continuación, se identifican las filas de los
cajones que deberían contener DDIC cuando el gabinete está configurado a medio ocupar:
● Cajón superior: fila frontal
● Cajón superior: fila central
● Cajón inferior: fila frontal
Si se instalan unidades de disco adicionales incrementalmente en un gabinete a medio ocupar, los DDIC se deben agregar una fila completa
a la vez (sin ranuras vacías en la fila) en la secuencia indicada:
● Cajón inferior: fila central
● Cajón superior: fila posterior
● Cajón inferior: fila posterior
Reemplazo de un módulo de controladora o IOM en un gabinete de 2U
o 5U
En esta sección, se proporcionan los procedimientos para quitar e instalar un módulo de controladora o IOM en un gabinete de 2U o 5U.
Los gabinetes de 2U son compatibles con configuraciones de módulo de controladora doble o único. Los gabinetes 5U84 solo son
compatibles con configuraciones de módulo de controladora doble.
Si un módulo de controladora falla, la controladora conmutará por error y se ejecutará en un solo módulo hasta restaurar la redundancia.
Para gabinetes 2U, se debe instalar un módulo de controladora en la ranura A y un módulo de controladora o controladora de relleno en la
ranura B para garantizar un flujo de aire suficiente por el gabinete durante el funcionamiento. Para gabinetes 5U84, se debe instalar un
módulo de controladora en ambas ranuras.
En una configuración de módulo de controladora doble, los módulos de controladora e IOM son intercambiables en caliente, lo cual significa
que podrá reemplazar un módulo sin detener la I/O a grupos de discos o apagar el gabinete. En este caso, el segundo módulo de
controladora se hace cargo el funcionamiento del sistema de almacenamiento hasta que instale el nuevo módulo.
Es posible que deba reemplazar un módulo de controladora o IOM en los siguientes casos:
● El LED de error está iluminado
● El estado que se informa en el PowerVault Manager indica un problema con el módulo
● Los eventos del PowerVault Manager indican un problema con el módulo
● La solución de problemas indica un problema con el módulo
62
Reemplazo y extracción del módulo

En la ilustración en las siguientes secciones, se muestra el reemplazo del módulo de controladora para la ranura superior (A) del gabinete.
Para reemplazar un módulo de controladora o IOM en la ranura inferior (B), gire el módulo 180º de modo que quede alineado
correctamente con sus conectores en la parte posterior del midplane.
Reemplazo de módulos de controladora en un gabinete de módulo de
controladora doble
La extracción de un módulo de controladora de un gabinete en funcionamiento cambia significativamente el flujo de aire dentro del
gabinete. Los módulos de la controladora deben ocupar las aberturas de ranuras para que el gabinete se enfríe correctamente. Deje los
módulos de controladora en el gabinete hasta que esté listo para instalar un módulo de controladora de reemplazo.
Cuando se instalan dos módulos de controladora en un gabinete, los módulos de controladora deben ser del mismo tipo de modelo.
PRECAUCIÓN: Cuando reemplace un módulo de controladora, asegúrese de que transcurran menos de 10 segundos
entre la inserción en una ranura y el bloqueo en el lugar. De lo contrario, es posible que la controladora falle. Si no se
bloquea dentro de 10 segundos, quite el módulo de controladora de la ranura y repita el proceso.
Siga estas reglas cuando reemplace un módulo de controladora en un gabinete en funcionamiento:
1. Registre la configuración del módulo de controladora antes de reemplazar los módulos de controladora.
2. Extraiga el módulo de la controladora del gabinete.
3. Instale el módulo de controladora de repuesto en el gabinete.
4. Espere 30 minutos y, a continuación, utilice la CLI o el PowerVault Manager para comprobar el estado del sistema y los registros de
eventos, a fin de verificar que el sistema esté estable.
NOTA:
Si la función de actualización del firmware del partner (PFU) no está habilitada, actualice el firmware en el módulo de
controladora de reemplazo.
Siga estas reglas cuando reemplace ambos módulos de controladora en un gabinete en funcionamiento:
1. Registre la configuración del módulo de controladora antes de reemplazar los módulos de controladora.
2. Quite un módulo de controladora del gabinete.
3. Instale el módulo de controladora de repuesto en el gabinete.
4. Espere 30 minutos y, a continuación, utilice la CLI o el PowerVault Manager para comprobar el estado del sistema y los registros de
eventos, a fin de verificar que el sistema esté estable.
NOTA:
Si la función de actualización del firmware del partner (PFU) no está habilitada, actualice el firmware en el módulo de
controladora de reemplazo. Para obtener más información sobre la actualización de firmware, consulte la Guía del administrador
del sistema de almacenamiento de Dell EMC PowerVault ME4 Series.
5. Quite el segundo módulo de controladora del gabinete.
6. Instale el módulo de controladora de repuesto en el gabinete.
7. Espere 30 minutos y, a continuación, utilice la CLI o el PowerVault Manager para comprobar el estado del sistema y los registros de
eventos, a fin de verificar que el sistema esté estable.
NOTA:
Si la función de actualización del firmware del partner (PFU) no está habilitada, actualice el firmware en el módulo de
controladora de reemplazo. Para obtener más información sobre la actualización de firmware, consulte la Guía del administrador
del sistema de almacenamiento de Dell EMC PowerVault ME4 Series.
Extracción de un módulo de controladora de un gabinete de módulo de controladora doble
Realice los siguientes pasos para quitar un módulo de controladora de un gabinete de módulo de controladora doble:
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
NOTA:
● Puede realizar el intercambio en caliente de un módulo de controladora único en un gabinete en funcionamiento, siempre y cuando
apague primero el módulo de controladora mediante el PowerVault Manager o la CLI.
● No quite un módulo de controladora fallido a menos que tenga el repuesto a mano. Todos los módulos deben estar colocados
mientras el sistema está en funcionamiento.
1. Verifique que haya apagado correctamente el módulo de controladora mediante el PowerVault Manager o la CLI.
2. Localice el gabinete con un LED de UID iluminado.
3. Dentro del gabinete, localice el módulo de controladora con un LED azul de Listo para quitar.
4. Desconecte todos los cables conectados al módulo de controladora.
Reemplazo y extracción del módulo
63

Etiquete cada cable para facilitar la reconexión al módulo de controladora de repuesto.
5. Sujete el pestillo del módulo entre el pulgar y el índice, presione el flanco y el asa para soltar el asa del pestillo y balancee el pestillo hacia
afuera para soltar el módulo de controladora de la posición asentada.
Ilustración 54. Extracción de un módulo de controladora de un gabinete
NOTA:
En Extracción de un módulo de controladora, se muestra un módulo de controladora de SAS de 4 puertos. Sin embargo,
todos los módulos de controladora utilizan el mismo mecanismo de pestillo.
6. Gire el asa del pestillo para abrirla, agarre el asa del pestillo y facilite el módulo de la controladora hacia adelante desde la ranura.
7. Coloque ambas manos en el cuerpo del módulo de controladora y tire hacia arriba para quitarlo del gabinete, de manera tal que el
módulo de controladora se mantenga nivelado durante la extracción.
Instalación de un módulo de controladora de repuesto en un gabinete de módulo de
controladora doble
Realice los siguientes pasos para instalar un módulo de controladora de repuesto en un gabinete de módulo de controladora doble:
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
1. Examine el módulo de la controladora de repuesto para ver si hay daños e inspeccione detenidamente el conector de interfaz. No
instale el módulo de controladora de repuesto si las clavijas están dobladas.
2. Sujete el módulo de controladora con ambas manos y, con el pestillo en la posición abierta, oriente el módulo de controladora y alinéelo
para insertarlo en la ranura de destino.
3. Asegúrese de que el módulo de controladora esté nivelado y deslícelo hacia el interior del gabinete hasta que haga tope.
Un módulo de controladora que solo esté parcialmente asentado no permitirá el rendimiento óptimo del gabinete de controladora.
Verifique que el módulo de controladora esté asentado completamente antes de continuar.
4. Cierre el pestillo manualmente para fijar el módulo de controladora en su posición.
Debería oír un clic cuando el asa del pestillo se enganche y fije el módulo de controladora al conector en la parte posterior del midplane.
5. Vuelva a conectar los cables.
64
Reemplazo y extracción del módulo

PRECAUCIÓN: Si los cables de cobre pasivo se conectan al módulo de controladora, el cable no debe tener una
conexión a un punto común de conexión a tierra.
6. Actualice el firmware en el módulo de controladora de repuesto a la misma versión que el otro módulo de la controladora.
NOTA: En un sistema de módulo de controladora doble en el que PFU esté habilitado, el sistema actualiza automáticamente el
firmware en un módulo de controladora de reemplazo.
Reemplazo de un módulo de la controladora en un gabinete de módulo de
controladora único
Siga estas reglas cuando reemplace un módulo de controladora en un gabinete de módulo de controladora único:
1. Si el módulo de controladora sigue funcionando, registre las direcciones IP y la configuración del sistema de almacenamiento en la hoja
de trabajo Información del sistema, que se encuentra en la Guía de implementación del sistema de almacenamiento de Dell EMC
PowerVault ME4 Series.
2. Utilice el PowerVault Manager o la CLI para apagar el sistema de almacenamiento.
3. Quite el módulo de la controladora del gabinete del sistema de almacenamiento. Para obtener instrucciones, consulte Extracción de un
módulo de controladora de un gabinete de módulo de controladora único en la página 65.
4. Mueva la tarjeta de memoria CompactFlash de la controladora defectuosa al módulo de controladora de repuesto. Para obtener
instrucciones, consulte Traslado de la tarjeta de memoria CompactFlash para un gabinete de módulo de controladora único en la página
66.
5. Instale el módulo de controladora de repuesto en el gabinete del sistema de almacenamiento y configure el módulo de controladora de
repuesto. Para obtener instrucciones, consulte Instalación y configuración de un módulo de controladora de repuesto en un gabinete
de módulo de controladora único en la página 67.
Extracción de un módulo de controladora de un gabinete de módulo de controladora único
Realice los siguientes pasos para quitar un módulo de controladora de un gabinete de módulo de controladora único:
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
1. Apague el sistema de almacenamiento mediante el PowerVault Manager o la CLI.
2. Desconecte todos los cables conectados al módulo de controladora.
Etiquete cada cable para facilitar la reconexión al módulo de controladora de repuesto.
3. Sujete el pestillo del módulo entre el pulgar y el índice, presione el flanco y el asa para soltar el asa del pestillo y balancee el pestillo hacia
afuera para soltar el módulo de controladora de la posición asentada.
Reemplazo y extracción del módulo
65

Ilustración 55. Extracción de un módulo de controladora de un gabinete
NOTA:
En las ilustraciones anteriores, se muestra un módulo de controladora de SAS de 4 puertos. Sin embargo, todos los
módulos de controladora utilizan el mismo mecanismo de pestillo.
4. Gire el asa del pestillo para abrirla, agarre el asa del pestillo y facilite el módulo de la controladora hacia adelante desde la ranura.
5. Coloque ambas manos en el cuerpo del módulo de controladora y tire hacia arriba para quitarlo del gabinete, de manera tal que el
módulo de controladora se mantenga nivelado durante la extracción.
Traslado de la tarjeta de memoria CompactFlash para un gabinete de módulo de controladora
único
Este procedimiento corresponde únicamente a configuraciones del gabinete de módulo de controladora. La tarjeta de memoria
CompactFlash se debe pasar del módulo de controladora fallido al módulo de controladora de repuesto para evitar la pérdida de datos.
Confirme que el transporte de CompactFlash sea la acción adecuada, según se explica en el capítulo Solución de problemas de la Guía
de implementación del sistema de almacenamiento de ME4 Series.
PRECAUCIÓN:
No mueva las tarjetas CompactFlash en un ambiente de módulo de controladora doble. La caché se
duplica entre las tarjetas de memoria CompactFlash en ambientes de módulo de controladora doble.
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
1. Quite el módulo de controladora fallido del gabinete de controladora.
2. Localice la tarjeta de memoria CompactFlash en el lado del módulo de controladora fallido de cara al midplane.
66
Reemplazo y extracción del módulo

Ilustración 56. Ubicación de la tarjeta de memoria CompactFlash
a. Tarjeta de memoria CompactFlash
b. Módulo de controladora visto desde la parte posterior
3. Sujete la tarjeta de memoria CompactFlash y tire con cuidado para quitarla de la ranura en el módulo de controladora fallido.
4. Etiquete la tarjeta de memoria CompactFlash como Datos, y déjela a un lado para guardarla.
5. Localice el módulo de controladora de repuesto y quite su tarjeta de memoria CompactFlash instalada.
6. Introduzca la tarjeta de memoria CompactFlash del módulo de controladora de repuesto en el módulo de controladora fallido.
Procure no confundir esta tarjeta de memoria con la que tiene la etiqueta Datos.
7. Inserte la tarjeta de memoria CompactFlash con la etiqueta Datos en el módulo de controladora de repuesto. Empuje la tarjeta de
memoria hacia adelante hasta que quede asentada en su lugar.
Instalación y configuración de un módulo de controladora de repuesto en un gabinete de
módulo de controladora único
Realice los siguientes pasos para instalar y configurar un módulo de controladora de repuesto en un gabinete de módulo de controladora
único:
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
NOTA:
Para obtener instrucciones sobre cómo realizar los siguientes pasos, consulte la Guía de implementación del sistema de
almacenamiento de Dell EMC PowerVault ME4 Series.
1. Examine el módulo de la controladora para ver si hay daños e inspeccione detenidamente el conector de interfaz. No instale el módulo
de controladora si las clavijas están dobladas.
2. Con el pestillo en posición abierta, sujete el módulo de controladora con ambas manos y alinéelo para insertarlo en la ranura de destino.
3. Asegúrese de que el módulo de controladora esté nivelado y deslícelo hacia el interior del gabinete hasta que haga tope.
Un módulo de controladora que solo esté parcialmente asentado no permitirá el rendimiento óptimo del gabinete de controladora.
Verifique que el módulo de controladora esté asentado completamente antes de continuar.
4. Cierre el pestillo manualmente para fijar el módulo de controladora en su posición.
Debería oír un clic cuando el asa del pestillo se enganche y fije el módulo de controladora al conector en la parte posterior del midplane.
5. Vuelva a conectar los cables al módulo de controladora.
PRECAUCIÓN:
Si los cables de cobre pasivo se conectan al módulo de controladora, el cable no debe tener una
conexión a un punto común de conexión a tierra.
● Para un módulo de controladora con puertos de CNC, siga las instrucciones de configuración en la Guía de implementación del
sistema de almacenamiento de Dell EMC PowerVault ME4 Series.
● Para un módulo de controladora con puertos de iSCSI 10Gbase-T, conecte los cables de Ethernet al módulo de controladora y
configure las direcciones IP para los puertos de iSCSI.
● Para un módulo de controladora con puertos de SAS, conecte los cables de SAS al módulo de controladora.
6. Actualice el firmware en el módulo de controladora a la misma versión del firmware que se encontraba en el módulo de controladora
fallido.
7. Configure los ajustes del sistema y realice la configuración de almacenamiento.
Reemplazo y extracción del módulo
67

PRECAUCIÓN: Si los grupos de discos entran en modo de cuarentena durante la configuración de almacenamiento,
comuníquese con soporte técnico antes de continuar con el paso siguiente.
8. Configure los ajustes de puertos de iSCSI o FC en la pestaña Puertos del cuadro de diálogo Configuración del sistema.
● Si el módulo de controladora contiene puertos de CNC, seleccione el modo de puerto de host.
○ Si se selecciona FC como el modo de puerto, configure los ajustes del puerto de FC.
○ Si se selecciona iSCSI como el modo de puerto, configure los ajustes de puerto de iSCSI.
○ Si se selecciona FC e iSCSI como el modo de puerto, configure los ajustes de puertos de FC e iSCSI.
● Si el módulo de controladora contiene puertos de iSCSI 10Gbase-T, configure los ajustes de puerto de iSCSI.
9. Vuelva a configurar las conexiones a los sistemas host y vuelva a asignar los volúmenes.
10. Configure las replicaciones entre sistemas de almacenamiento.
Extracción de un IOM
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
NOTA: Consideraciones para la extracción de IOM:
● Los gabinetes de expansión están equipados con dos IOM. Puede realizar el intercambio en caliente de un IOM único en un
gabinete en funcionamiento.
● Si va a reemplazar ambos IOM y el gabinete de expansión está en línea, puede realizar el intercambio en caliente del IOM en la
ranura “A” y, a continuación, realizar el intercambio en caliente del IOM en la ranura “B”, verificando que la controladora reconozca
cada módulo.
● No quite un IOM fallido a menos que tenga el repuesto a mano. Todos los IOM deben estar colocados mientras el sistema está en
funcionamiento.
1. Localice el gabinete de expansión que contiene el IOM que debe reemplazar. En el panel frontal del gabinete, verifique si hay una
condición de falla de luz ámbar en el panel del operador del gabinete. En el panel posterior del gabinete, busque una luz ámbar en el
LED de error del IOM.
2. Desconecte todos los cables conectados al IOM.
Etiquete cada cable para facilitar la reconexión al IOM de repuesto.
3. Sujete el pestillo del módulo entre el pulgar y el índice, presione el flanco y el asa para soltar el asa del pestillo y balancee el pestillo hacia
afuera para soltar el IOM de su posición asentada.
68
Reemplazo y extracción del módulo

Ilustración 57. Extracción de un IOM de un gabinete
4.
NOTA:
Extracción de un IOM de un gabinete en la página 69 Muestra un módulo de controladora de SAS de 4 puertos en lugar de
un IOM. Sin embargo, un IOM utiliza el mismo mecanismo de pestillo que el módulo de controladora.
5. Gire el asa del pestillo para abrirla, agarre el asa del pestillo y saque el IOM hacia adelante desde la ranura.
6. Coloque ambas manos en el cuerpo del IOM y tire para quitarlo del gabinete, de manera tal que el IOM se mantenga nivelado durante la
extracción.
Instalación de un IOM
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
1. Consulte el IOM para ver si hay daños e inspeccione detenidamente el conector de interfaz. No instale el IOM si los pins están
doblados.
2. Sujete el IOM con ambas manos y, con el pestillo en la posición abierta, oriente el IOM y alinéelo para insertarlo en la ranura de destino.
3. Asegúrese de que el IOM esté nivelado y deslícelo dentro del gabinete hasta donde sea posible.
Un IOM que solo esté parcialmente asentado no permitirá el rendimiento óptimo del gabinete de expansión. Verifique que el IOM esté
asentado completamente antes de continuar.
4. Cierre el pestillo manualmente para fijar el IOM en su posición.
Debería oír un clic cuando el asa del pestillo se enganche y fije el IOM a su conector en la parte posterior del midplane.
5. Vuelva a conectar los cables.
Reemplazo de una fuente de alimentación (PSU) en un gabinete de 5U
En esta sección, se proporcionan procedimientos para quitar e instalar una PSU en un gabinete de 5U.
En las imágenes de los procedimientos de instalación y extracción de la PSU, se muestran las vistas del panel posterior del gabinete de 5U.
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
Reemplazo y extracción del módulo
69

Extracción de una PSU
Antes de quitar la PSU, desconecte la alimentación mediante el interruptor de la red eléctrica (cuando esté presente) o mediante la
extracción física de la fuente de alimentación para garantizar que el sistema tenga una advertencia del apagado de alimentación inminente.
Asegúrese de identificar correctamente la PSU fallida antes de comenzar los pasos del procedimiento.
PRECAUCIÓN: Quitar una fuente de alimentación afecta de manera significativa el flujo de aire del gabinete. No quite la
PSU hasta tener el módulo de repuesto. Es importante que todas las ranuras estén ocupadas cuando el gabinete está en
funcionamiento.
1. Detenga toda la I/O de los hosts al gabinete. Consulte Apagado de un módulo de controladora en la página 45.
NOTA: Este paso no es necesario para el intercambio en caliente. Sin embargo, es necesario cuando reemplaza ambas PSU al
mismo tiempo.
2. Utilice el software de administración para apagar cualquiera de los otros componentes del sistema necesarios.
NOTA: Este paso no es necesario para el intercambio en caliente. Sin embargo, es necesario cuando reemplaza ambas PSU al
mismo tiempo.
3. Verifique que el LED de buen estado de alimentación esté encendido, apague la PSU fallida y desconecte el cable de la fuente de
alimentación.
4. Si reemplaza una sola PSU mediante el intercambio en caliente, continúe al paso 6.
5. Si reemplaza ambas PSU, verifique que el gabinete se haya desactivado mediante las interfaces de administración y que esté apagado.
6. Verifique que el cable de alimentación esté desconectado.
7. Presione el pestillo de liberación hacia la derecha y manténgalo en su lugar (detalle n.° 1).
8. Con la otra mano, sostenga el asa y tire de la PSU hacia afuera (detalle n.° 2).
Ilustración 58. Extracción de una PSU (1 de 2)
Ilustración 59. Extracción de una PSU (2 de 2)
9. Mientras sujeta la PSU con ambas manos, quítela del gabinete.
10. Si va a reemplazar ambas PSU, repita los pasos 5 a 9.
70
Reemplazo y extracción del módulo

NOTA: La ranura de la PSU no debe estar vacía durante más de 2 minutos con el gabinete encendido.
Instalación de una PSU
Si reemplaza ambas PSU, el gabinete se debe apagar mediante un apagado ordenado, utilizando las interfaces de administración.
1. Asegúrese de que la PSU esté apagada.
2. Oriente la PSU para la inserción en la ranura de destino en el panel posterior del gabinete, como se muestra en Extracción de una PSU
(2 de 2) en la página 70.
3. Deslice la PSU en la ranura hasta que el pestillo encaje en su posición.
4. Conecte el cable de alimentación de CA.
5. Mueva el interruptor de alimentación de la PSU a la posición de encendido.
6. Espere a que el LED de buen estado de la alimentación en la PSU que acaba de insertar se ilumine con luz verde. Consulte Fuente de
alimentación (PSU) en la página 19.
● Si el LED de buen estado de alimentación no se enciende, verifique que la PSU esté insertada y colocada correctamente en la
ranura.
● Si está colocado correctamente, puede haber una falla en el módulo. Verifique el PowerVault Manager y los registros de eventos
para obtener más información.
● Mediante las interfaces de administración (el PowerVault Manager o la CLI), determine si la nueva PSU está en buen estado.
Verifique que el LED de buen estado de alimentación se ilumine en color verde y que los estados del panel del operador no
muestren fallas de módulo en color ámbar.
7. Si va a reemplazar ambas PSU, repita los pasos 1 a 6.
Reemplazo de un módulo de enfriamiento con ventilador (FCM) en un
gabinete de 5U
En esta sección, se proporcionan procedimientos para quitar e instalar un FCM en un gabinete de 5U.
En las imágenes de los procedimientos de instalación y extracción del FCM, se muestran las vistas del panel posterior del gabinete de 5U.
Antes de comenzar con cualquier procedimiento, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
Extracción de un FCM
Puede cambiar todos los módulos de enfriamiento con ventilador, siempre y cuando los quite e inserte uno a la vez. Recomendamos que
apague la unidad después de quitar dos o más ventiladores.
PRECAUCIÓN:
Quitar un FCM afecta de manera significativa el flujo de aire del gabinete. No quite el FCM hasta tener el
módulo de repuesto. Es importante que todas las ranuras estén ocupadas cuando el gabinete está en funcionamiento.
1. Identifique el módulo de enfriamiento del ventilador (FCM) que desea quitar. Si el módulo de FCM falló, el LED de error del ventilador
se iluminará con luz ámbar fija. Consulte Módulo de enfriamiento con ventilador (FCM) en la página 19.
2. Presione el pestillo de liberación hacia abajo y manténgalo en su lugar (detalle n.° 1).
3. Con la otra mano, sostenga el asa y tire del FCM hacia afuera (detalle n.° 2).
Reemplazo y extracción del módulo
71

Ilustración 60. Extracción de un FCM (1 de 2)
4. Mientras sujeta el FCM con ambas manos, quítelo del gabinete.
Ilustración 61. Extracción de un FCM (2 de 2)
NOTA: La ranura del FCM no debe estar vacía durante más de 2 minutos con el gabinete encendido.
Instalación de un FCM
Puede realizar un intercambio en caliente del reemplazo de un FCM único: sin embargo, si reemplaza varios FCM, el gabinete se debe
apagar de manera ordenada mediante las interfaces de administración.
1. Oriente el FCM para la inserción en la ranura de destino en el panel posterior del gabinete, como se muestra en Extracción de un FCM
(2 de 2) en la página 72.
2. Deslice el FCM en la ranura hasta que el pestillo encaje en su posición.
El gabinete debería detectar y usar automáticamente el nuevo módulo.
3. Espere a que el LED de buen estado del módulo en el FCM recién insertado se ilumine en color verde. Consulte Módulo de enfriamiento
con ventilador (FCM) en la página 19.
● Si el LED de buen estado del módulo no se enciende, compruebe que el FCM esté correctamente insertado y colocado en la ranura.
● Si está colocado correctamente, puede haber una falla en el módulo. Verifique el PowerVault Manager y los registros de eventos
para obtener más información.
● Mediante las interfaces de administración (el PowerVault Manager o la CLI), determine si el nuevo FCM está en buen estado.
Verifique que el LED de buen estado del módulo se ilumine en color verde y que el panel del operador no muestre fallas de módulo
en color ámbar.
4. Si va a reemplazar varios FCM, repita los pasos 1 a 4.
72
Reemplazo y extracción del módulo

Reemplazo de un módulo de enfriamiento de alimentación (PCM) en
un gabinete de 2U
En esta sección, se proporcionan procedimientos para quitar e instalar un PCM en un gabinete de 2U.
En las imágenes de los procedimientos de instalación y extracción del PCM, se muestran las vistas del panel posterior del gabinete de 2U.
Un único PCM es suficiente para mantener el funcionamiento del gabinete. No es necesario detener las operaciones y apagar el gabinete
por completo al reemplazar solo un PCM; sin embargo, es necesario apagar completamente de manera ordenada si va a reemplazar ambas
unidades al mismo tiempo.
PRECAUCIÓN: No quite la cubierta del PCM, ya que se expondrá al riesgo de descarga eléctrica del interior. Devuelva el
PCM a su proveedor para la reparación.
Antes de comenzar cualquiera de los procedimientos, consulte Precauciones ante descargas electroestáticas (ESD) en la página 43.
NOTA: En las ilustraciones, se muestra el reemplazo del módulo de PCM en la ranura derecha, con usted viendo el panel posterior del
gabinete. Para reemplazar un PCM en la ranura izquierda, gire el módulo 180° para que se alinee adecuadamente con sus conectores
en la parte posterior del midplane.
Extracción de un PCM
PRECAUCIÓN: La extracción de fuente de alimentación interrumpe de manera significativa el flujo de aire del gabinete.
No extraiga el PCM hasta que haya recibido el módulo de reemplazo. Es importante que todas las ranuras estén
ocupadas cuando el gabinete esté en funcionamiento.
Antes de extraer el PCM, desconecte la alimentación del PCM mediante el interruptor de red (si lo hubiera) o si quita físicamente la fuente
de alimentación para garantizar que el sistema tenga una advertencia de apagado de alimentación inminente. Asegúrese de identificar el
PCM defectuoso en forma correcta antes de comenzar el procedimiento de pasos.
1. Detenga toda la I/O de los hosts al gabinete. Consulte Apagado de los hosts conectados en la página 45.
NOTA:
Este paso no es necesario para el intercambio en caliente. Sin embargo, debe implementarlo cuando reemplaza ambos
PCM a la vez.
2. Utilice el software de administración para apagar cualquiera de los otros componentes del sistema necesarios.
NOTA:
Este paso no es necesario para el intercambio en caliente. Sin embargo, debe implementarlo cuando reemplaza ambos
PCM a la vez.
3. Apague el PCM defectuoso y desconecte el cable de la fuente de alimentación.
4. Si reemplaza un solo PCM mediante un intercambio en activo, continúe con el paso 6.
5. Si reemplaza ambos PCM, compruebe que el gabinete se haya apagado con las interfaces de administración y que el gabinete esté
apagado.
6. Verifique que el cable de alimentación esté desconectado.
7. Sujete el pestillo y el lateral del asa del PCM entre el pulgar y el índice, apriete y abra el asa para accionar la leva del PCM y quitarlo del
gabinete, como se muestra en la siguiente ilustración.
Reemplazo y extracción del módulo
73

Ilustración 62. Extracción de un PCM (1 de 2)
8. Sujete el asa y retire el PCM: procure sostener la base del módulo con ambas manos a medida que lo quita del gabinete, como se
muestra en la siguiente ilustración.
Ilustración 63. Extracción de un PCM (2 de 2)
NOTA:
Las ilustraciones de extracción del PCM muestran un chasis configurado como un gabinete de controladora FC/iSCSI de
4 puertos. El procedimiento rige para todos los gabinetes de controladora de 2U y los gabinetes de expansión.
9. Si va a reemplazar dos PCM, repita los pasos 5 a 8.
Instalación de un PCM
Consulte Extracción de un PCM (1 de 2) en la página 74 y Extracción de un PCM (2 de 2) en la página 74 cuando realice este
procedimiento, pero ignore las flechas de dirección, ya que insertará el módulo en la ranura en lugar de extraerlo.
NOTA: Maneje el PCM con cuidado y evite dañar las patas del conector. No instale el PCM si alguna clavija parece estar doblada.
1. Compruebe si hay daños, especialmente en todos los conectores del módulo.
2. Con el asa del PCM en la posición de apertura, deslice el módulo en el gabinete y asegúrese de sostener la base y el peso del módulo
con ambas manos.
3. Lleve el módulo hasta su lugar; para ello, cierre manualmente el asa del PCM. Debe oír un clic, ya que el asa del pestillo se encaja y fija el
PCM a su conector en la parte posterior del midplane.
4. Conecte el cable de alimentación a la fuente de alimentación y al PCM.
5. Fije los sujetacables.
74
Reemplazo y extracción del módulo

6. Mediante las interfaces de administración (el PowerVault Manager o la CLI), compruebe si el estado del nuevo PCM es bueno.
Verifique que el LED de buen estado del PCM de color verde esté encendido/intermitente según Estados de LED de PCM en la página
34 . Verifique que los ventiladores de enfriamiento estén girando sin estados de falla. Verifique que los estados del panel de operador
no muestren errores del módulo en amarillo fijo.
7. Si va a reemplazar dos PCM, repita los pasos 1 a 5.
Conclusión del proceso de instalación de componentes
Esta sección proporciona un procedimiento para garantizar que los componentes instalados en el chasis del gabinete de controladora de
reemplazo funcionen correctamente.
1. Vuelva a conectar los cables de datos entre los dispositivos, según sea necesario, para volver a la configuración de cableado original:
● Entre gabinetes de almacenamiento en cascada.
● Entre la controladora y los dispositivos SAN periféricos.
● Entre el gabinete de controladora y el host.
2. Vuelva a conectar los cables de alimentación a los gabinetes de almacenamiento.
Verificación del funcionamiento de componentes
1. Mueva el interruptor de alimentación en la fuente de alimentación a la posición de Encendido en la siguiente secuencia para reiniciar
dispositivos de sistema:
a. Primero, los gabinetes de expansión.
b. Luego, el gabinete de controladora.
c. Por último, el host de datos (si está apagado con fines de mantenimiento).
Deje pasar el tiempo suficiente para que cada dispositivo complete sus pruebas automáticas de encendido (POST) antes de continuar.
2. Realice una reexploración para forzar un descubrimiento nuevo de todos los gabinetes de expansión conectados al gabinete de la
controladora. Este paso borra la información de diseño de la SAS interna, reasigna las ID de gabinete y garantiza que los gabinetes se
muestren en el orden correcto. Use la CLI o el PowerVault Manager para realizar la reexploración:
Para realizar una reexploración mediante la CLI, introduzca el siguiente comando: rescan
Para realizar una reexaminación mediante el PowerVault Manager:
a. Verifique que ambas controladoras funcionen normalmente.
b. En el tema Sistema, seleccione Acción > Reexaminar canales de disco.
c. Seleccione Reexaminar.
Uso de LED
En esta sección, se describen los LED utilizados para verificar el funcionamiento de los componentes. Estos LED están ubicados en los
paneles frontal y posterior del gabinete.
Verificar los indicadores LED del panel frontal
Los indicadores LED del panel frontal residen en el panel de operaciones que se encuentra en la brida izquierda. Los indicadores LED del
disco se encuentran en los módulos del portaunidades.
● Compruebe que el LED de encendido/en espera del sistema esté iluminado en verde y que el LED de error del módulo no esté
iluminado.
● Compruebe que el LED de ID del gabinete que está a la izquierda esté iluminado en verde.
● Verifique que el LED del módulo de disco se ilumine o parpadee con luz verde, y que no se ilumine en color ámbar.
Verificar los LED del panel posterior
Los LED del panel posterior se encuentran en el módulo de controladora, el IOM y las placas frontales del PCM.
● Para los módulos de controladora e IOM, compruebe que el LED de buen estado se ilumine con luz verde, lo que indica que el módulo
finalizó la inicialización y está en línea.
● Para PCM, compruebe que el LED de buen estado de la PCM se ilumine con luz verde en cada PCM.
Reemplazo y extracción del módulo
75

Uso de interfaces de administración
Además de ver los LED como se describió anteriormente, puede utilizar las interfaces de administración para supervisar el estado del
sistema y sus componentes, siempre y cuando haya configurado y aprovisionado el sistema y haya habilitado la notificación de eventos.
Elija uno de los siguientes métodos para verificar la operación de los componentes:
● Utilice el PowerVault Manager para supervisar los íconos o valores de estado del sistema y sus componentes para asegurarse de que
todo está en condiciones, o para desglosar un componente que tiene problemas. El PowerVault Manager utiliza los iconos para mostrar
los estados de Buen estado, Deteriorado, Error o Desconocido para el sistema y sus componentes. Si detecta un componente con
problemas, siga las acciones del campo Recomendación para resolver el problema.
●
Otra alternativa al uso del PowerVault Manager es ejecutar el comando show system en la CLI para ver el estado del sistema y sus
componentes. Si algún componente presenta un problema, el estado del sistema se muestra como show system, Degraded o
Fault. Si descubre un componente con inconvenientes, sigas las acciones del campo Recomendaciones de estado para resolver el
problema.
● Monitoreo de la notificación de eventos: con la notificación de eventos configurada y habilitada, puede ver los registros de eventos
para supervisar el estado del sistema y sus componentes. Si se muestra un mensaje en el que se recomienda que verifique si se ha
registrado un evento o que consulte la información sobre un evento en el registro, puede hacerlo mediante el PowerVault Manager o la
CLI. Con el PowerVault Manager, vea el registro de eventos y, a continuación, coloque el cursor sobre el mensaje de evento para ver
más detalles. Mediante la CLI, ejecute el comando show events detail con parámetros adicionales para filtrar la salida y ver los
detalles de un evento. Consulte la Guía de referencia de la CLI para obtener más información acerca de los parámetros y la sintaxis de
comandos.
Actualizaciones en el PowerVault Manager después de
reemplazar un HBA de SAS o FC
Después de reemplazar un HBA de SAS o FC en un host conectado, realice las siguientes tareas:
1. Para un HBA de FC, actualice la agrupación por zonas si se utiliza un switch y, a continuación, actualice la agrupación de hosts/
iniciadores en el PowerVault Manager.
2. Para un SAS de HBA, actualice la agrupación de hosts/iniciadores en el PowerVault Manager.
Para obtener más información acerca de la administración de hosts y grupos de hosts en el PowerVault Manager, consulte la Guía del
administrador del sistema de almacenamiento de Dell EMC PowerVault ME4 Series.
76
Reemplazo y extracción del módulo

Eventos y mensajes de evento
Cuando se produce un evento en un sistema de almacenamiento, se registra un mensaje de evento en el registro de eventos del sistema.
Según la configuración de notificaciones de eventos del sistema, el mensaje de evento también se puede enviar a usuarios (mediante
correo electrónico) y aplicaciones basadas en host (mediante SNMP o SMI-S).
NOTA: Una buena práctica es habilitar las notificaciones que se enviarán para eventos con gravedad Advertencia o una gravedad
superior.
Cada evento tiene un código numérico que identifica el tipo de evento producido y tiene uno de los siguientes niveles de gravedad:
● Crítica: se produjo una falla que podría provocar que una controladora se apague. Corrija el problema inmediatamente.
● Error: se produjo una falla que puede afectar la integridad de datos o la estabilidad del sistema. Corrija el problema lo antes posible.
● Advertencia: se produjo un problema que podría afectar la estabilidad del sistema, pero no la integridad de datos. Evalúe el problema y
corríjalo si es necesario.
● Informativa: se produjo un cambio de estado o configuración, o se produjo un problema que el sistema corrigió. No se requiere una
acción inmediata. En este documento, esta gravedad se abrevia como “Info”.
● Resuelta: se resolvió la condición que causó el registro de un evento.
Un mensaje de evento podría especificar un código de error o un código de motivo asociados, que proporcionan detalles adicionales para el
soporte técnico. Los códigos de error y los códigos de motivo se encuentran fuera del alcance de esta guía.
Temas:
• Descripciones de eventos
• Eventos
• Eventos eliminados
• Eventos enviados como indicaciones a clientes de SMI-S
• Uso del comando de confianza
Descripciones de eventos
En esta sección, se describen los mensajes de eventos que se pueden informar durante el funcionamiento del sistema y se especifican las
acciones recomendadas en respuesta a un evento.
Según el modelo del sistema y la versión de firmware, es posible que algunos eventos que se describen en este documento no se apliquen
a su sistema. Las descripciones de eventos se deben considerar como explicaciones de eventos que se pueden ver. No deben considerarse
como descripciones de los eventos que debería haber visto, pero no vio. En esos casos, es probable que esos eventos no se apliquen a su
sistema.
En esta sección:
● El término grupo de discos se refiere a un vDisk para almacenamiento lineal o a un grupo de discos virtuales para almacenamiento
virtual.
● El término pool se refiere a un único vDisk para almacenamiento lineal o a un pool virtual para almacenamiento virtual.
Para obtener un resumen de los eventos de almacenamiento y las indicaciones de SMI-S correspondientes, consulte Eventos enviados
como indicaciones a clientes de SMI-S en la página 152.
4
Eventos y mensajes de evento 77

Eventos
Tabla 27. Descripciones de eventos y acciones recomendadas
Número Gravedad Descripción/acciones recomendadas
1 Crítico Esta gravedad del evento tiene las siguientes variantes:
1. El grupo de discos está en línea y no puede tolerar otra falla de disco, y no hay ningún repuesto del
tamaño y el tipo adecuados para reconstruir automáticamente el grupo de discos.
● Si el grupo de discos que se indica es RAID 6, funciona con estado degradado debido a la falla de
dos discos.
● Si el grupo de discos que se indica no es RAID 6, funciona con estado degradado debido a la falla
de un disco.
Para grupos de discos lineales, si hay un disco disponible del tipo y el tamaño correcto y la función de
repuestos dinámicos está activada, se utiliza ese disco para reconstruir automáticamente el grupo de
discos y se registra el evento 37.
2. El grupo de discos está en línea y no puede tolerar otra falla de disco. Si el grupo de discos indicado
es RAID 6, funciona con estado degradado debido a la falla de dos discos. Si el grupo de discos
indicado no es RAID 6, funciona con estado degradado debido a la falla de un disco.
Acciones recomendadas:
● Si el evento 37 no se registró, no había un repuesto del tamaño y tipo adecuados para la
reconstrucción. Reemplace el disco fallido con uno del mismo tipo y de la misma o mayor capacidad,
y, si es necesario, desígnelo como repuesto. Verifique si se registran los eventos 9 y 37 para
confirmar esto.
● De lo contrario, la reconstrucción comenzó automáticamente y se registró el evento 37. Reemplace
el disco fallido y configure el repuesto como un repuesto dedicado (solo lineal) o global para usarlo en
el futuro.
● Para un rendimiento de I/O óptimo y continuo, el disco de repuesto debería tener el mismo
rendimiento o un mejor rendimiento.
● Confirme que haya reemplazado todos los discos fallidos y que haya suficientes discos de repuesto
configurados para usarlos en el futuro.
Aviso
El grupo de discos está en línea, pero no puede tolerar otra falla de disco.
● Si el grupo de discos que se indica es RAID 6, funciona con estado degradado debido a la falla de dos
discos.
● Si el grupo de discos que se indica no es RAID 6, funciona con estado degradado debido a la falla de
un disco.
Se utiliza un repuesto dedicado o un repuesto global del tamaño y el tipo adecuados para reconstruir
automáticamente el grupo de discos. Se registran los eventos 9 y 37 para indicar esto.
Acciones recomendadas:
● Si el evento 37 no se registró, no había un repuesto del tamaño y tipo adecuados para la
reconstrucción. Reemplace el disco fallido con uno del mismo tipo y de la misma o mayor capacidad,
y, si es necesario, desígnelo como repuesto. Verifique si se registran los eventos 9 y 37 para
confirmar esto.
● De lo contrario, la reconstrucción comenzó automáticamente y se registró el evento 37. Reemplace
el disco fallido y configure el repuesto como un repuesto dedicado (solo lineal) o global para usarlo en
el futuro.
● Para un rendimiento de I/O óptimo y continuo, el disco de repuesto debería tener el mismo
rendimiento o un mejor rendimiento.
● Confirme que haya reemplazado todos los discos fallidos y que haya suficientes discos de repuesto
configurados para usarlos en el futuro.
3 Error
El grupo de discos indicado está offline.
Falló un disco para RAID 0 o NRAID, fallaron tres discos para RAID 6 o fallaron dos discos para otros
niveles de RAID. No se puede reconstruir el grupo de discos. Este no es un estado normal para un grupo
de discos, a menos que lo haya quitado de cuarentena manualmente.
Para grupos de discos virtuales en el nivel Rendimiento, cuando ocurre una falla de discos, los datos del
grupo de discos que usa ese disco se migrarán automáticamente a otro grupo de discos disponible si hay
espacio, para no perder datos de usuario. Los datos solo se perderán su ocurren varias fallas de discos
78 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
rápidamente, por lo cual no hay suficiente tiempo para migrar los datos, si no hay suficiente espacio para
pasar los datos a otro nivel o si el usuario no reemplaza los discos fallidos enseguida.
Acciones recomendadas:
● El comando de la CLI trust podría ser capaz de recuperar algunos de los datos en el grupo de
discos. Consulte la ayuda de la CLI para obtener el comando de confianza. Comuníquese con el
soporte técnico para ayudar a determinar si la operación de confianza corresponde a su situación y
para obtener ayuda para llevarla a cabo.
● Si decide no utilizar el comando de confianza, realice los siguientes pasos:
○ Reemplace el disco o los discos fallidos. (Busque el evento 8 en el registro de eventos para
determinar qué discos fallaron y obtener consejo sobre cómo reemplazarlos).
○
Elimine el grupo de discos (comando de la CLI remove disk-groups).
○ Vuelva a crear el grupo de discos (comando de la CLI add disk-group).
Para evitar este problema en el futuro, utilice un nivel de RAID tolerante a fallas, configure uno o más
discos como discos de repuesto y reemplace los discos fallidos enseguida.
4 Información El disco indicado tenía un bloque dañado que se corrigió.
Acciones recomendadas:
● Supervise la tendencia del error y si el número de errores se aproxima al número total de repuestos
de bloque fallido disponibles.
5 Información Se reinició la controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
6 Aviso Se produjo una falla durante la inicialización del grupo de discos indicado. Probablemente, esto fue
causado por la falla de una unidad de disco. Puede que la inicialización se haya completado, pero el grupo
de discos, probablemente, tiene un estado de FTDN (tolerante a fallas con un disco desactivado), CRIT
(crítico) u OFFL (offline), según en nivel de RAID y el número de discos fallidos.
Acciones recomendadas:
● Busque otro evento registrado aproximadamente al mismo tiempo que indique una falla de disco,
como el evento 55, 58 o 412. Siga las acciones recomendadas para ese evento.
Información Realice una de estas acciones:
● El grupo de discos se creó correctamente.
● La creación del grupo de discos falló inmediatamente. Se envió una retroalimentación al usuario
inmediatamente sobre el fallo en el momento en que intentó agregar el grupo de discos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
7 Error En un ambiente de pruebas, un diagnóstico de la controladora falló e informa un código de diagnóstico
específico del producto.
Acciones recomendadas:
● Realice un análisis de falla.
8 Aviso Se produjo una de las siguientes condiciones:
● Hay un disco que formaba parte de un grupo desactivado. El disco indicado en el grupo de discos
indicado falló y, probablemente, el grupo de discos tenía un estado de FTDN (tolerante a fallas con
un disco desactivado), CRIT (crítico) u OFFL (offline), según el nivel de RAID y el número de discos
que fallaron. Si hay un repuesto y el grupo de discos no está offline, la controladora usa el repuesto
automáticamente para reconstruir el grupo de discos. Los eventos subsecuentes indican los cambios
que ocurren al grupo de discos. Cuando se resuelve el problema, se registra el evento 9.
● Falló la reconstrucción de un grupo de discos. El disco indicado se usó como disco objetivo para
reconstruir el grupo de discos indicado. Cuando se reconstruía el grupo de discos, otro disco en el
grupo falló y el estado del grupo pasó a ser OFFL (offline). El disco indicado tiene un estado de
LEFTOVR (sobrante).
Eventos y mensajes de evento 79

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Una SSD que formaba parte de un grupo de discos informó que ya no tiene vida útil restante. El
disco indicado en el grupo de discos indicado falló y, probablemente, el grupo de discos tenía un
estado de FTDN (tolerante a fallas con un disco desactivado), CRIT (crítico) u OFFL (offline), según
el nivel de RAID y el número de discos que fallaron. Si hay un repuesto y el grupo de discos no está
offline, la controladora usa el repuesto automáticamente para reconstruir el grupo de discos. Los
eventos subsecuentes indican los cambios que ocurren al grupo de discos. Cuando se resuelve el
problema, se registra el evento 9.
Acciones recomendadas:
● Si un disco que formaba parte de un grupo de discos está desactivado:
○ Si el disco indicado falló por una de estas razones: errores de medio excesivos, falla de disco
inminente, posible falla de hardware, disco no compatible, demasiados errores recuperables de la
controladora, solicitud ilegal, degradación o lentitud excesiva, reemplace el disco con uno del
mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o mayor capacidad. Para un
rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un rendimiento igual o
mejor que el que está reemplazando.
○ Si el disco indicado falló porque un usuario forzó el disco fuera del grupo de discos, porque falló la
inicialización de RAID-6, o por una razón desconocida:
■ Si el grupo de discos asociado está offline o en cuarentena, comuníquese con el soporte
técnico.
■ De lo contrario, anule los metadatos del disco para volver a utilizarlo.
○ Si el disco indicado falló debido a que un disco detectado anteriormente ya no está disponible:
■ Vuelva a insertar el disco o inserte un disco de repuesto del mismo tipo (SSD, enterprise SAS
o midline SAS) y de la misma o mayor capacidad que el que estaba en la ranura. Para un
rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un rendimiento igual o
mejor que el que está reemplazando.
■ Si el disco, a continuación, tiene estado de sobrante (LEFTOVR), borre los metadatos para
volver a usar el disco.
■ Si el grupo de discos asociado está offline o en cuarentena, comuníquese con el soporte
técnico.
● Si falló la reconstrucción de un grupo de discos:
○ Si el grupo de discos asociado está en línea, borre los metadatos del disco indicado para poder
volver a usarlo.
○ Si el grupo de discos asociado está offline, el comando de la CLI trust podría recuperar algunos
o todos los datos del grupo. Sin embargo, confiar en un disco parcialmente reconstruido podría
corromper los datos. Consulte la ayuda de la CLI para el comando trust. Comuníquese con el
soporte técnico para obtener ayuda a fin de determinar si la operación de confianza corresponde
a su situación y para obtener ayuda para llevarla a cabo.
● Si el grupo de discos asociado está offline y no desea usar el comando de confianza, realice los
siguientes pasos:
○ Elimine el grupo de discos (comando de la CLI remove disk-groups).
○ Borre los metadatos del disco indicado para poder volver a usarlo (comando de la CLI clear
disk-metadata).
○ Reemplace el disco o los discos fallidos. (Busque otras instancias del evento 8 en el registro de
eventos para determinar qué discos fallaron).
○ Vuelva a crear el grupo de discos (comando de la CLI para agregar grupo de discos).
● Si una SSD que formaba parte de un grupo de discos informó que no tiene vida útil restante,
reemplace el disco con uno del mismo tipo y la misma o mayor capacidad. Para un rendimiento de
I/O óptimo continuo, el disco de repuesto debe tener un rendimiento igual o mejor que el que está
reemplazando.
9
Información El disco de repuesto indicado se usó en el grupo de discos indicado para devolverlo a un estado de
tolerancia a fallas.
La reconstrucción del grupo de discos comienza automáticamente. Este evento indica que se resolvió un
problema informado por el evento 8.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
80 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
16 Información Se designó un repuesto global al disco indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
18 Error La reconstrucción del grupo de discos se completó con errores.
Cuando un disco falla, la reconstrucción se realiza mediante un disco de repuesto. Sin embargo, esta
operación falló. Algunos de los datos en los otros discos del grupo de discos no se pueden leer (error de
medios incorregible), por lo cual algunos datos no se pueden reconstruir.
Acciones recomendadas:
● Si no tiene una copia de respaldo de los datos, realice una.
● Busque otro evento registrado aproximadamente al mismo tiempo que indique una falla de disco,
como el evento 8 , 55, 58 o 412. Siga las acciones recomendadas para ese evento.
Información Se completó la reconstrucción del grupo de discos.
Para el grupo de discos ADAPT que se completó parcialmente, no hay espacio de repuesto disponible o
el espacio de repuesto no se puede utilizar por los requisitos de tolerancia a fallas de ADAPT.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
19 Información Se completó la repetición de la exploración.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
20 Información Se completó la actualización del firmware de la controladora de almacenamiento.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
21 Error Se completó la verificación del grupo de discos. Se encontraron errores, pero no se corrigieron.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Aviso La verificación del grupo de discos no se completó por una condición detectada internamente, como un
disco fallido. Si un disco falla, los datos podrían estar en riesgo.
Acciones recomendadas:
● Resuelva los problemas de hardware que no sean de disco, como un problema de enfriamiento o una
fuente de alimentación, un módulo de controladora o un módulo de expansión defectuosos.
● Verifique si algún disco en el grupo de discos registró eventos de SMART o errores de lectura
irrecuperables.
○ Si es así y el grupo de discos tiene un nivel de RAID sin tolerancia a fallas (RAID 0 o no RAID),
copie los datos a un grupo diferente y reemplace los discos fallidos.
○ Si es así y el grupo de discos tiene un nivel de RAID con tolerancia a fallas, verifique el estado
actual del grupo de discos. Si no es FTOL, respalde los datos, ya que podrían estar en riesgo. Si
es FTOL, reemplace el disco indicado. Si más de un disco en el grupo de discos registró un
evento de SMART, respalde los datos y reemplace todos los discos, uno a la vez. En
almacenamiento virtual, podría ser posible quitar el grupo de discos afectado, lo que volcará sus
datos en otro grupo y volverá a agregar el grupo de discos.
Información La verificación del grupo de discos falló inmediatamente, fue cancelada por un usuario o se realizó con
éxito.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
23 Información Comenzó la creación de un grupo de discos.
Acciones recomendadas:
Eventos y mensajes de evento 81

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● No es necesario realizar ninguna acción.
25 Información Se restablecieron las estadísticas del grupo de discos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
28 Información Se modificaron los parámetros de la controladora.
Este evento se registra cuando se realizan cambios en la configuración general, por ejemplo, prioridad de
utilidades, ajustes de notificación remota, contraseñas de interfaz de usuario y valores de IP de puerto
de red. Este evento no se registra cuando se realizan cambios al grupo de discos o a la configuración del
volumen.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
31 Información El disco indicado ya no está designado como repuesto.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
32 Información Comenzó la verificación del grupo de discos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
33 Información Se cambió la fecha y hora de la controladora.
Este evento se registra antes de que suceda el cambio, por lo que la fecha y hora del evento muestra la
hora anterior. Este evento puede ocurrir a menudo si la opción NTP está habilitada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
34 Información La configuración de la controladora se restauró a los valores de fábrica.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
37 Información Comenzó la reconstrucción del grupo de discos. Cuando se completa, se registra el evento 18.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
38 Información Una temperatura, un voltaje o una medición de corriente cambió de error o advertencia a buen estado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
39 Aviso Los sensores supervisaron una temperatura o voltaje en el rango de advertencia. Cuando se resuelve el
problema, se registra el evento 47 para el componente que registró el evento 39.
Si el evento se refiere a un sensor de disco, el comportamiento del disco podría ser impredecible en este
rango de temperatura.
Compruebe el registro de eventos para determinar si más de un disco informó este evento.
● Si varios discos informaron esta condición, podría haber un problema en el ambiente.
● Si un disco informa esta condición, podría haber un problema en el ambiente o una falla en el disco.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
82 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si ninguna de estas explicaciones corresponde, reemplace el disco o el módulo de controladora que
registró el error.
40 Error Los sensores supervisaron una temperatura o voltaje en el rango de falla. Cuando se resuelve el
problema, se registra el evento 47 para el componente que registró el evento 40.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
● Si ninguna de estas explicaciones corresponde, reemplace el disco o el módulo de controladora que
registró el error.
41 Información El disco indicado se designó como repuesto para el grupo de discos indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
43 Información El grupo de discos indicado se eliminó.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
44 Aviso La controladora contiene datos de caché para el volumen indicado pero el grupo de discos
correspondiente no está en línea.
Acciones recomendadas:
● Determine la razón para que los discos que componen el grupo no estén en línea.
● Si hay un gabinete desactivado, determine la acción correctiva.
● Si el grupo de discos ya no es necesario, puede borrar los datos huérfanos. Esto dará como resultado
una pérdida de datos.
● Si no se encuentra el grupo de discos y no se quitó intencionalmente, consulte Solución de
problemas en la página 31.
47 Información Se borró un error detectado por los sensores. Este evento indica que se resolvió un problema informado
por los eventos 39 o 40.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
48 Información Se cambió el nombre del grupo de discos indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
49 Información Se completó un comando de mantenimiento de SCSI prolongado (esto suele ocurrir durante la
actualización del firmware del disco).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
50 Error Se produjo un error de ECC corregible en la memoria caché más de 10 veces durante un período de
24 horas, indicando una probable falla de hardware.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
Aviso Se produjo un error de ECC corregible en la memoria caché.
Eventos y mensajes de evento 83

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Este evento se registra con gravedad de Advertencia para proporcionar información que puede resultar
útil al soporte técnico, pero no es necesario realizar ninguna acción en este momento. Se registrará con
gravedad de Error, si es necesario, para reemplazar el módulo de controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
51 Error Se produjo un error de ECC incorregible en la memoria caché más de una vez durante un período de
48 horas, indicando una probable falla de hardware.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
Aviso Se produjo un error de ECC incorregible en la memoria caché.
Este evento se registra con gravedad de Advertencia para proporcionar información que puede resultar
útil al soporte técnico, pero no es necesario realizar ninguna acción en este momento. Se registrará con
gravedad de Error, si es necesario, para reemplazar el módulo de controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
52 Información Comenzó la expansión del grupo de discos.
Esta operación puede demorar días, o semanas en algunos casos, en completarse. Permita un tiempo
adecuado para que se complete la expansión.
Cuando se completa, se registra el evento 53.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
53 Aviso La expansión del grupo de discos no pudo continuar porque se produjeron demasiados errores.
Acciones recomendadas:
● Si la expansión falló debido a un problema de disco, reemplace el disco con uno del mismo tipo (SSD,
enterprise SAS o midline SAS) y de la misma o mayor capacidad. Para un rendimiento de I/O óptimo
continuo, el disco de repuesto debe tener un rendimiento igual o mejor que el que está
reemplazando. Si comienza la reconstrucción del grupo de discos, espere a que se complete y vuelva
a intentar la expansión.
Información La expansión del grupo de discos se completó, falló inmediatamente o fue cancelada por un usuario.
Acciones recomendadas:
● Si la expansión falló debido a un problema de disco, reemplace el disco con uno del mismo tipo (SSD,
enterprise SAS o midline SAS) y de la misma o mayor capacidad. Para un rendimiento de I/O óptimo
continuo, el disco de repuesto debe tener un rendimiento igual o mejor que el que está
reemplazando. Si comienza la reconstrucción del grupo de discos, espere a que se complete y vuelva
a intentar la expansión.
54 Información Debe reemplazar la batería.
La batería proporciona alimentación de respaldo para el reloj de tiempo real (fecha/hora). En caso de
una falla de alimentación, la fecha y hora se revertirán a 1980-01-01 00:00:00.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
55 Aviso El disco indicado informó un evento de SMART.
Un evento de SMART indica una falla de disco inminente.
Acciones recomendadas:
● Resuelva los problemas de hardware que no sean de disco, especialmente los problemas de
enfriamiento o una fuente de alimentación fallida.
84 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si el disco está en un grupo de discos que tiene un nivel de RAID sin tolerancia a fallas (RAID 0 o no
RAID), copie los datos a un grupo diferente y reemplace el disco fallido.
● Si el disco está en un grupo de discos que tiene un nivel de RAID con tolerancia a fallas, verifique el
estado actual del grupo de discos. Si no es FTOL, respalde los datos, ya que podrían estar en riesgo.
Si es FTOL, reemplace el disco indicado. Si más de un disco en el grupo de discos registró un evento
de SMART, respalde los datos y reemplace todos los discos, uno a la vez. En almacenamiento virtual,
podría ser posible quitar el grupo de discos afectado, lo que volcará sus datos en otro grupo y
volverá a agregar el grupo de discos.
56 Información Se encendió o reinició una controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
58 Error Una unidad de disco detectó un error grave, como un error de paridad o una falla de hardware de disco.
Acciones recomendadas:
● Reemplace el disco fallido por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma
o mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un
rendimiento igual o mejor que el que está reemplazando.
Aviso Una unidad de disco se restableció automáticamente debido a un error lógico interno.
Acciones recomendadas:
● La primera vez que se registró este evento con gravedad de Advertencia, si el disco indicado no
ejecuta el firmware más reciente, actualice el firmware de disco.
● Si este evento se registra con gravedad de Advertencia para el mismo disco más de cinco veces por
semana y el disco indicado está ejecutando el firmware más reciente, reemplace el disco con uno del
mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o mayor capacidad. Para un
rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un rendimiento igual o mejor
que el que está reemplazando.
Información Una unidad de disco informó un evento.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
59 Aviso La controladora detectó un evento de paridad mientras se comunicaba con el dispositivo SCSI indicado.
El evento fue detectado por la controladora y no por el disco.
Acciones recomendadas:
● Si el evento indica que un disco o un módulo de expansión está dañado, reemplace el dispositivo
indicado.
Información La controladora detectó un error que no es de paridad mientras se comunicaba con el dispositivo SCSI
indicado. El evento fue detectado por la controladora y no por el disco.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
61 Error La controladora restableció un canal de disco para recuperarse de un error de comunicación. Este
evento se registra para identificar una tendencia de errores a través del tiempo.
Acciones recomendadas:
● Si la controladora se recupera, no es necesario realizar ninguna acción.
● Vea otros eventos registrados para determinar otras acciones necesarias.
62 Aviso El disco de repuesto dedicado indicado o el disco de repuesto global falló.
Acciones recomendadas:
● Reemplace el disco por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o
mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un
rendimiento igual o mejor que el que está reemplazando.
Eventos y mensajes de evento 85

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si el disco fallido era un repuesto global, configure el nuevo disco como repuesto global.
● Si el disco fallido era un repuesto dedicado, configure el nuevo disco como repuesto dedicado para el
mismo grupo de discos.
65 Error Se produjo un error de ECC incorregible en la memoria caché al iniciar.
La controladora se reinicia automáticamente y los datos de caché se restauran desde la caché de la
controladora asociada.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
68 Información La controladora que registró este evento está apagada, o ambas controladoras están apagadas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
71 Información La controladora se inició o completó la conmutación por errores.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
72 Información Tras la conmutación por errores, la recuperación comenzó o se completó.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
73 Información Las dos controladoras se comunican entre sí y la redundancia de caché está habilitada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
74 Información La ID de loop de FC para el grupo de discos indicado se cambió para ser consistente con la ID de otros
grupos de discos. Esto puede ocurrir cuando los discos que forman un grupo se insertan de un gabinete
con una ID de loop de FC diferente.
La nueva controladora propietaria también registra este evento después de que cambia la propiedad del
grupo de discos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
75 Información El número de unidad lógica (LUN) del volumen indicado se desasignó por sus conflictos con LUN
asignados a otros volúmenes. Esto puede ocurrir cuando los discos que contienen datos de un volumen
asignado se mueven de un sistema de almacenamiento a otro.
Acciones recomendadas:
● Si desea que los hosts accedan a los datos de volumen de los discos insertados, asigne el volumen
con un LUN diferente.
76 Información La controladora está utilizando la configuración predeterminada. Este evento ocurre durante el primer
encendido y es posible que ocurra después de una actualización de firmware.
Acciones recomendadas:
● Si acaba de realizar una actualización de firmware y el sistema requiere ajustes de configuración
especiales, debe hacer esos cambios en la configuración antes de que su sistema vuelva a funcionar
como antes.
77 Información La caché se inicializó como resultado del encendido o la conmutación por errores.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
78 Aviso La controladora no pudo utilizar un repuesto asignado para un grupo de discos porque la capacidad del
repuesto es demasiado pequeña.
86 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Esto ocurre cuando falla un disco en el grupo de discos, no hay ningún repuesto dedicado disponible y
todos los repuestos globales son demasiado pequeños, la función de repuestos dinámicos está habilitada,
todos los repuestos globales y discos disponibles son demasiado pequeños o no hay ningún repuesto del
tipo adecuado. Podría haber más de un disco fallido en el sistema.
Acciones recomendadas:
● Reemplace cada disco fallido por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la
misma o mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe
tener un rendimiento igual o mejor que el que está reemplazando.
● Configure discos como repuestos dedicados o repuestos globales.
○ Para un repuesto dedicado, el disco debe ser del mismo tipo que los demás discos en el grupo, al
menos tan grande como el disco de menor capacidad en el grupo de discos, y tener un
rendimiento igual o mejor.
○ Para un repuesto global, es mejor elegir un disco que sea igual o más grande que el disco más
grande de su tipo en el sistema, y que tenga el mismo o mejor rendimiento. Si el sistema tiene
una combinación de tipos de discos (SSD, enterprise SAS o midline SAS), debería haber al menos
un repuesto global de cada tipo (a menos que los repuestos dedicados se utilicen para proteger
cada grupo de discos de un tipo determinado).
79 Información Se completó una operación de confianza para el grupo de discos indicado.
Acciones recomendadas:
● Asegúrese de completar el procedimiento de confianza, como se documenta en la ayuda de la CLI
para el comando trust.
80 Información La controladora habilitó o deshabilitó los parámetros indicados para uno o más discos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
81 Información La controladora actual revivió la controladora asociada. La otra controladora se reiniciará.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
82 Información Conflicto de ID de canal de disco.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
83 Información La controladora asociada está cambiando de estado (se está apagando o reiniciando).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
84 Aviso La controladora actual que registró este evento forzó la conmutación por errores de la controladora
asociada.
Acciones recomendadas:
● Descargue los registros de depuración del sistema de almacenamiento y comuníquese con el soporte
técnico. Un técnico de servicio puede usar los registros de depuración para determinar el problema.
86 Información Se cambiaron los parámetros de canal de disco o puerto de host.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
87 Aviso La configuración duplicada recuperada por esta controladora desde la controladora asociada tiene una
verificación de redundancia cíclica (CRC) errónea. En su lugar, se usará la configuración de flash local.
Acciones recomendadas:
● Restaure la configuración predeterminada mediante el comando restore defaults, como se
describe en la guía de referencia de la CLI.
Eventos y mensajes de evento 87

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
88 Aviso La configuración duplicada recuperada por esta controladora desde la controladora asociada está
corrupta. En su lugar, se usará la configuración de flash local.
Acciones recomendadas:
● Restaure la configuración predeterminada mediante el comando restore defaults, como se
describe en la guía de referencia de la CLI.
89 Aviso La configuración duplicada recuperada por esta controladora desde la controladora asociada tiene un
nivel de configuración demasiado alto para que lo procese el firmware de la controladora. En su lugar, se
usará la configuración de flash local.
Acciones recomendadas:
● Es probable que la controladora actual que registró este evento tenga un firmware de nivel inferior.
Actualice el firmware en la controladora de nivel inferior. Ambas controladoras deben tener las
mismas versiones de firmware.
Cuando se resuelve el problema, se registra el evento 20.
90 Información La controladora asociada no tiene una imagen de configuración duplicada para la controladora actual,
por lo que se está utilizando la configuración de flash local de la controladora actual.
Se espera que suceda este evento si la otra controladora es nueva o si se cambió su configuración.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
91 Error En un ambiente de pruebas, el diagnóstico que verifica señales de restablecimiento de hardware entre
controladoras de modo activo-activo falló.
Acciones recomendadas:
● Realice un análisis de falla.
95 Error Ambas controladoras en una configuración activa-activa tienen el mismo número de serie. Los números
de serie repetidos pueden causar problemas en el sistema. El número de serie, por ejemplo, determina
los WWN.
Acciones recomendadas:
● Quite uno de los módulos de controladora, coloque un repuesto y devuelva el módulo quitado para la
reprogramación.
96 Información Los cambios de configuración pendientes que se aplican al inicio se ignoraron, ya que datos de los
clientes podrían estar presentes en la caché.
Acciones recomendadas:
● Si no se produjeron los cambios en la configuración solicitados, realícelos nuevamente, use un
comando de interfaz de usuario para apagar la controladora de almacenamiento y reiníciela.
103 Información Se cambió el nombre del volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
104 Información Se cambió el tamaño del volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
105 Información Se cambió número de unidad lógica (LUN) predeterminado para el volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
106 Información El volumen indicado se agregó al pool indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
88 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
107 Error La controladora detectó un error grave. En una configuración de controladora única, la controladora se
reiniciará automáticamente. En una configuración activa-activa, la controladora asociada desactivará la
controladora que experimentó el error.
Acciones recomendadas:
● Descargue los registros de depuración del sistema de almacenamiento y comuníquese con el soporte
técnico. Un técnico de servicio puede usar los registros de depuración para determinar el problema.
108 Información El volumen indicado se eliminó del pool indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
109 Información Se restablecieron las estadísticas del volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
110 Información La propiedad del grupo de discos indicado se entregó a la otra controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
111 Información El vínculo del puerto de host indicado está activado.
Este evento indica que se resolvió un problema informado por el evento 112. Para un sistema con
puertos de FC, este evento también aparece después de la inicialización del loop.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
112 Aviso El vínculo del puerto de host indicado se desactivó inesperadamente. Esto puede afectar las
asignaciones de host.
Acciones recomendadas:
● Busque el evento 111 correspondiente y supervise las transiciones excesivas que indican un problema
de interruptor o de conectividad de host. Si este evento sucede más de 8 veces por hora, se debe
investigar.
● Este evento, probablemente, está causado por equipo fuera del sistema de almacenamiento, como
un cableado fallido o un interruptor fallido.
● Si el problema no se encuentra fuera del sistema de almacenamiento, reemplace el módulo de
controladora que registró este evento.
Información El vínculo del puerto de host indicado se desactivó porque se está iniciando la controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
114 Información El vínculo del puerto de canal de disco indicado está desactivado. Tenga en cuenta que los eventos 114 y
211 se registran cuando se realiza una nueva exploración solicitada por el usuario y no indican un error.
Acciones recomendadas:
● Busque el evento 211 correspondiente y supervise las transiciones excesivas que indiquen problemas
de disco. Si hay más de 8 transiciones por hora, consulte Solución de problemas en la página 31.
116 Error Después de una recuperación, la controladora asociada se desactivó mientras duplicaba datos de caché
con reescritura a la controladora que registró este evento. Esta última controladora se reinició para
evitar la pérdida de datos de la caché de la controladora asociada, pero, si la otra controladora no se
reinicia correctamente, los datos se perderán.
Acciones recomendadas:
● Para determinar si hubo una pérdida de datos, verifique si este evento fue seguido del evento 56 (la
controladora de almacenamiento se inició) y, luego, el evento 71 (falló la conmutación por errores).
La conmutación por errores indica que no se reinició correctamente.
Eventos y mensajes de evento 89

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
117 Aviso Este módulo de controladora detectó o generó un error en el canal de host indicado.
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si se detectan más errores, verifique la conectividad entre la controladora y el host conectado.
● Si se generan más errores, apague la controladora de almacenamiento y reemplace el módulo de
controladora.
118 Información Se cambiaron los parámetros de la caché para el volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
127 Aviso La controladora detectó una conexión de doble puerto de disco no válida. Este evento indica que un
puerto de host de controladora está conectado a un puerto de expansión, en lugar de a un puerto en un
host o un interruptor.
Acciones recomendadas:
● Desconecte el puerto de host del puerto de expansión o viceversa y conéctelos a los dispositivos
adecuados.
136 Aviso Los errores detectados en el canal de disco indicado provocaron que la controladora marque el canal
como degradado.
Acciones recomendadas:
● Determine el origen de los errores en el canal de disco indicado y reemplace el hardware fallido.
Cuando se resuelve el problema, se registra el evento 189.
139 Información Se encendió o reinició la controladora de administración (MC).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
140 Información La controladora de administración está a punto de reiniciarse.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
141 Información Este evento se registra cuando un usuario o un servidor DHCP (si DHCP está habilitado) cambió la
dirección IP usada para la administración del sistema. Este evento también se registra durante la
recuperación de la conmutación por errores o el encendido, incluso cuando la dirección no ha cambiado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
152 Aviso La controladora de administración (MC) no se comunicó con la controladora de almacenamiento (SC)
durante 15 minutos y puede haber fallado.
Este evento se registra inicialmente con gravedad de Informacional. Si continúa, se registra nuevamente
con gravedad de Advertencia y se reinicia la MC automáticamente para intentar recuperarse del
problema. Se registra el evento 156.
Acciones recomendadas:
● Si este evento se registra solo una vez con gravedad de Advertencia, no es necesario realizar
ninguna acción.
● Si este evento se registra más de una vez con gravedad de Advertencia, realice lo siguiente:
○ Verifique la versión del firmware de la controladora y actualice al firmware más reciente si es
necesario.
○ Si el firmware más reciente ya está instalado, el módulo de controladora que registró este evento
probablemente tiene una falla de hardware. Reemplace el módulo.
● Si no puede acceder a las interfaces de administración de la controladora que registró este evento,
realice lo siguiente:
90 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
○ Apague esa controladora y vuelva a colocar el módulo.
○ Si, a continuación, puede acceder a las interfaces de administración, verifique la versión del
firmware de la controladora y actualice al firmware más reciente si es necesario.
○ Si el problema persiste, reemplace el módulo.
Información La controladora de administración (MC) no se comunicó con la controladora de almacenamiento (SC)
durante 160 segundos.
Si la comunicación se restaura en menos de 15 minutos, se registra el evento 153. Si el problema
continúa, el evento se registra nuevamente con gravedad de Advertencia.
NOTA: Es normal que se registre este evento con gravedad Informativa durante la actualización de
firmware.
Acciones recomendadas:
● Verifique la versión del firmware de la controladora y actualice al firmware más reciente si es
necesario.
●
Si el firmware más reciente ya está instalado, no es necesario realizar ninguna acción.
153 Información La controladora de administración (MC) ha vuelto a establecer la comunicación con la controladora de
almacenamiento (SC).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
156 Aviso La controladora de administración (MC) se reinició desde la controladora de almacenamiento (SC) para
la recuperación por errores.
Acciones recomendadas:
● Consulte las acciones recomendadas para el evento 152, que se registra a aproximadamente el
mismo tiempo.
Información La controladora de administración (MC) se reinició desde la controladora de almacenamiento (SC) en un
caso normal, como cuando la inicia un usuario.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
157 Error Se produjo una falla al intentar escribir en el chip flash de la controladora de almacenamiento (SC).
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
158 Error Se produjo un error de ECC incorregible en la memoria de la CPU de la controladora de almacenamiento
más de una vez durante un período de 12 horas, indicando una probable falla de hardware.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
Aviso Se produjo un error de ECC corregible en la memoria de la CPU de la controladora de almacenamiento.
Este evento se registra con gravedad de Advertencia para proporcionar información que puede resultar
útil al soporte técnico, pero no es necesario realizar ninguna acción en este momento. Se registrará con
gravedad de Error, si es necesario, para reemplazar el módulo de controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
161 Información Uno o más gabinetes no tienen una ruta válida a un procesador de administración de gabinetes (EMP).
Todos los EMP de gabinetes están deshabilitados.
Acciones recomendadas:
● Descargue los registros de depuración del sistema de almacenamiento y comuníquese con el soporte
técnico. Un técnico de servicio puede usar los registros de depuración para determinar el problema.
Eventos y mensajes de evento 91

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
162 Aviso Los WWN del host (nodo y puerto) presentados previamente por este módulo de controladora son
desconocidos. En un sistema de controladora doble, este evento tiene dos causas posibles:
● Se reemplazaron o movieron uno o ambos módulos de controladora cuando el sistema estaba
apagado.
● Se borró la configuración de flash de uno o ambos módulos de controladora (aquí es donde se
almacenan los WWN usados anteriormente).
El módulo de controladora genera un WWN basado en su propio número de serie para recuperarse de
esta situación.
Acciones recomendadas:
● Si se reemplazó el módulo de controladora o alguien reprogramó sus datos de ID de FRU, verifique la
información de la WWN para este módulo de controladora en todos los hosts que tienen acceso a él.
163 Aviso Los WWN del host (de nodo y puerto) presentados anteriormente por el módulo de controladora
asociado, que está offline, son desconocidos.
Este evento tiene dos causas posibles:
● Se reemplazó o quitó el módulo de controladora en línea que informó el evento mientras el sistema
estaba apagado.
● Se borró la configuración flash (donde se almacenan los WWN usadas anteriormente) del módulo de
controladora en línea.
El módulo de controladora en línea genera un WWN basado en su propio número de serie para el otro
módulo de controladora a fin de recuperarse de esta situación.
Acciones recomendadas:
● Si se reemplazó el módulo de controladora o alguien reprogramó sus datos de ID de FRU, verifique la
información de la WWN para el otro módulo de controladora en todos los hosts que tienen acceso a
él.
166 Aviso El nivel de metadatos de RAID de las dos controladoras no coindice, lo que indica que las controladoras
tienen distintos niveles de firmware.
Por lo general, la controladora con el nivel de firmware superior puede leer los metadatos escritos por
una controladora con un nivel de firmware inferior. Por lo general, lo contrario no sucede. Por lo tanto, si
la controladora con el nivel de firmware superior falló, la controladora sobreviviente con el nivel de
firmware inferior no puede leer los metadatos en los discos que realizaron la conmutación por errores.
Acciones recomendadas:
● Si esto ocurre después de una actualización de firmware, indica que el formato de metadatos
cambió, lo que es poco común. Actualice la controladora con el nivel de firmware más bajo para que
coincida con el nivel de firmware de la otra controladora.
167 Aviso Una prueba de diagnóstico en el arranque de la controladora detectó un funcionamiento anormal y
podría ser necesario un ciclo de encendido y apagado para corregirla.
Acciones recomendadas:
● Descargue los registros de depuración del sistema de almacenamiento y comuníquese con el soporte
técnico. Un técnico de servicio puede usar los registros de depuración para determinar el problema.
170 Información La última vez que se repitió la exploración se detectó que el gabinete indicado se agregó al sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
171 Información La última vez que se repitió la exploración se detectó que el gabinete indicado se quitó del sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
172 Error o
advertencia
El grupo de discos indicado se puso en cuarentena por uno de los siguientes motivos:
● No se puede acceder a todos los discos. Mientras el grupo de discos se encuentra en cuarentena, en
almacenamiento lineal, fallará cualquier intento de acceder a sus volúmenes en el grupo de discos
desde un host. En almacenamiento virtual, todos los volúmenes del pool pasarán a ser de solo lectura
92 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
de manera forzada. Si de pronto se puede acceder a todos los discos, el grupo de discos se quitará
de cuarentena automáticamente con un estado resultante de FTOL. Si no se puede acceder a todos
los discos pero los suficientes pasan a ser accesibles para permitir la lectura y la escritura al grupo de
discos, se quitará de cuarentena automáticamente con un estado resultante de FTDN o CRIT. Si hay
un disco de repuesto disponible, la reconstrucción comenzará automáticamente. Cuando el grupo de
discos se quita de cuarentena, se registra el evento 173. Para una discusión más detallada sobre la
quita de discos de cuarentena, consulte la documentación de la CLI o de la SMC.
PRECAUCIÓN:
○ Evite usar la operación de quita de cuarentena manual como método de
recuperación cuando registra el evento 172, ya que esto provoca que la
recuperación de datos sea más difícil o imposible.
○ Si borra los datos de caché no escritos mientras un grupo de discos se encuentra
en cuarentena u offline, los datos se perderán permanentemente.
● Contiene datos en un formato no compatible con este sistema. La controladora no es compatible
con grupos de discos lineales.
Acciones recomendadas:
● Si el grupo de discos se puso en cuarentena debido a que no se puede acceder a todos sus discos:
○ Si el evento 173 se registró subsecuentemente para el grupo de discos indicado, no es necesario
realizar ninguna acción. Ya se quitó el grupo de discos de cuarentena.
○ De lo contrario, realice las siguientes acciones:
■ Verifique que todos los gabinetes estén encendidos.
■
Verifique que todos los discos y módulos de I/O en cada gabinete estén completamente
asentados en sus ranuras y que sus pestillos estén bloqueados.
■ Vuelva a colocar cualquier disco en el disco de cuarentena que se informe como perdido o
fallido en la interfaz de usuario (NO quite y vuelva a colocar discos que no sean miembros del
grupo de discos en cuarentena).
■ Verifique que los cables de expansión de SAS están conectados entre cada gabinete del
sistema de almacenamiento y que estén completamente asentados (NO quite y vuelva a
insertar los cables, ya que esto puede causar problemas con grupos de discos adicionales).
■ Verifique que no se hayan quitado discos del sistema sin intención.
■ Verifique si hay otros eventos que indiquen fallas en el sistema y siga las acciones
recomendadas para esos eventos. Pero si el evento indica un disco fallido y la acción
recomendada es reemplazar el disco, NO reemplace el disco en este momento, ya que podría
ser necesario más adelante para la recuperación de datos.
■ Si el grupo de discos sigue en cuarentena después de realizar los pasos, apague ambas
controladoras y, a continuación, apague todo el sistema de almacenamiento. Vuelva a
encenderlo, comenzando con cualquier gabinete de disco (gabinete de expansión) y, luego, el
gabinete de controladora.
■ Si el grupo de discos sigue en cuarentena después de realizar las acciones recomendadas,
comuníquese con el soporte técnico.
● Si el grupo de discos se puso en cuarentena porque contiene datos en un formato no compatible con
el sistema:
○ Reemplace las controladoras con las controladoras compatibles con este tipo de grupo de discos
y recupere la facilidad de administración y el soporte total de los volúmenes y los grupos de
discos en cuarentena.
○ Si está seguro de que los datos de este grupo de discos no son necesarios, simplemente quite el
grupo de discos y, por lo tanto, los volúmenes, mediante las controladoras instaladas
actualmente.
173
Información Se quitó de cuarentena el grupo de discos indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
174 Información La actualización del firmware de disco o gabinete se realizó con éxito, un usuario la canceló o falló.
Si falla la actualización de firmware, se notificará el problema al usuario inmediatamente y este deberá
resolver el problema en ese momento, para que cuando haya una falla el evento se registre con
gravedad Informativa.
Eventos y mensajes de evento 93

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
175 Información El vínculo de Ethernet del puerto de red cambió de estado (superior o inferior) para la controladora
indicada.
Acciones recomendadas:
● Si este evento se registra indicando que el puerto de red está activado poco después del arranque
de la controladora de almacenamiento (MC, evento 139), no es necesario realizar ninguna acción.
● De lo contrario, supervise las ocurrencias de este evento para observar la tendencia de errores. Si
este evento sucede más de 8 veces por hora, deberá investigarlo.
○ Este evento, probablemente, está causado por equipo fuera del sistema de almacenamiento,
como un cableado fallido o un switch Ethernet fallido.
○ Si solo una controladora en un sistema de controladora doble registra este evento, intercambie
los cables de Ethernet entre las dos controladoras. Esto mostrará si el sistema es en el interior o
en el exterior del sistema de almacenamiento.
○ Si el problema no se encuentra fuera del sistema de almacenamiento, reemplace el módulo de
controladora que registró este evento.
176 Información Se restablecieron las estadísticas de error del disco indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
177 Información Se purgaron los datos de caché para el volumen faltante indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
181 Información Se cambiaron uno o más parámetros de configuración asociados con la controladora de almacenamiento
(MC), como la configuración para SNMP, SMI-S, notificación por correo electrónico y las cadenas del
sistema (nombre del sistema, ubicación del sistema, etc.).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
182 Información Se pausaron todos los canales de disco. No se realizará ninguna actividad de I/O en los discos hasta que
todos los canales se reanuden.
Acciones recomendadas:
● Si este evento ocurre en relación con una actualización de firmware de disco, no es necesario
realizar ninguna acción. Cuando se borra la condición, se registra el evento 183.
● Si se produce este evento y no está realizando una actualización de firmware de disco, consulte
Solución de problemas en la página 31.
183 Información Todos los canales de disco se reanudaron y la I/O puede continuar. La reanudación inicia una nueva
exploración que se registra como evento 19 cuando se completa.
Este evento indica que terminó la pausa informada por el evento 182.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
185 Información Se completó un comando de escritura del procesador de administración del gabinete (EMP).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
186 Información Un usuario cambió los parámetros del gabinete.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
187 Información Se habilitó la caché con reescritura
94 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
El evento 188 es el evento correspondiente que se registra cuando se habilita la caché de escritura no
simultánea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
188 Información Se deshabilitó la caché de escritura no simultánea.
El evento 187 es el evento correspondiente que se registra cuando se deshabilita la caché con
reescritura.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
189 Información Un canal de disco que estaba degradado o fallido ahora se encuentra en buen estado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
190 Información El paquete de supercapacitor del módulo de controladora comenzó a cargar.
Este cambio cumplió una condición para desencadenar la función de escritura simultánea automática,
que deshabilitó la caché con reescritura y puso el sistema en modo de escritura simultánea. Cuando se
resuelve la falla, se registra el evento 191 para indicar que se restauró el modo de escritura no simultánea.
Acciones recomendadas:
● Si el evento 191 no se registra dentro de los 5 minutos después del evento, el supercapacitor
probablemente falló y deberá reemplazar el módulo de controladora.
191 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 190.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
192 Información La temperatura del módulo de controladora superó el rango de funcionamiento normal.
Este cambio cumplió una condición para desencadenar la función de escritura simultánea automática,
que deshabilitó la caché con reescritura y puso el sistema en modo de escritura simultánea. Cuando se
resuelve la falla, se registra el evento 193 para indicar que se restauró el modo de escritura no
simultánea.
Acciones recomendadas:
● Si el evento 193 no se registró desde que se registró este evento, probablemente aún exista la
condición de temperatura superior al límite y deberá investigar. Probablemente, se registró otro
evento de temperatura superior al límite aproximadamente al mismo tiempo que este evento (como
los eventos 39, 40, 168, 307, 469, 476 o 477). Consulte las acciones recomendadas para ese evento.
193 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 192.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
194 Información La controladora de almacenamiento en el módulo de controladora asociado no está activa.
Esto indica que se produjo una condición de activación que provocó que la función de escritura
simultánea automática deshabilite la caché con reescritura y ponga el sistema en modo de escritura
simultánea. Cuando se resuelve la falla, se registra el evento 195 para indicar que se restauró el modo de
escritura no simultánea.
Acciones recomendadas:
● Si el evento 195 no se registró desde que se registró este evento, la otra controladora de
almacenamiento probablemente sigue desactivada y deberá investigar la razón. Probablemente, se
registraron otros eventos al mismo tiempo que este. Consulte las acciones recomendadas para esos
eventos.
Eventos y mensajes de evento 95

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
195 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 194.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
198 Información Falló una fuente de alimentación.
Esto indica que se produjo una condición de activación que provocó que la función de escritura
simultánea automática deshabilite la caché con reescritura y ponga el sistema en modo de escritura
simultánea. Cuando se resuelve la falla, se registra el evento 199 para indicar que se restauró el modo de
escritura no simultánea.
Acciones recomendadas:
● Si el evento 199 no se registró desde que se registró este evento, la fuente de alimentación
probablemente no está en buen estado y deberá investigar la razón. Probablemente, se registró otro
evento de fuente de alimentación aproximadamente al mismo tiempo que este evento (como el
evento 168). Consulte las acciones recomendadas para ese evento.
199 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 198.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
200 Información Falló un ventilador.
Esto indica que se produjo una condición de activación que provocó que la función de escritura
simultánea automática deshabilite la caché con reescritura y ponga el sistema en modo de escritura
simultánea. Cuando se resuelve la falla, se registra el evento 201 para indicar que se restauró el modo de
escritura no simultánea.
Acciones recomendadas:
● Si el evento 201 no se registró desde que se registró este evento, el ventilador probablemente no
está en buen estado y deberá investigar la razón. Probablemente, se registró otro evento de
ventilador aproximadamente al mismo tiempo que este evento (como el evento 168). Consulte las
acciones recomendadas para ese evento.
201 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 200.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
202 Información Se eliminó una condición de activación de escritura simultánea automática, que causó que se vuelva a
habilitar la caché con reescritura. El cambio ambiental también se registra aproximadamente al mismo
tiempo que este evento (eventos 191, 193, 195, 199, 201 y 241).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
203 Aviso Se produjo un cambio ambiental que permite que se vuelva a habilitar la caché con reescritura, pero la
preferencia de escritura no simultánea automática no está establecida. El cambio ambiental también se
registra aproximadamente al mismo tiempo que este evento (eventos 191, 193, 195, 199, 201 o 241).
Acciones recomendadas:
● Habilite la caché con reescritura manualmente.
204 Error Se produjo un error con el dispositivo NV o el mecanismo de transporte. El sistema podría intentar la
recuperación automática.
La tarjeta CompactFlash se utiliza para respaldar los datos de caché no escritos cuando una
controladora se desactiva inesperadamente, por ejemplo, en una falla de alimentación. Este evento se
genera cuando la controladora de almacenamiento (SC) detecta un problema con la tarjeta
CompactFlash durante el arranque.
96 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace la
CompactFlash.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace el
módulo de controladora.
Aviso El sistema se inició y encontró un problema con el dispositivo NV. El sistema intentará la recuperación
automática.
La tarjeta CompactFlash se utiliza para respaldar los datos de caché no escritos cuando una
controladora se desactiva inesperadamente, por ejemplo, en una falla de alimentación. Este evento se
genera cuando la controladora de almacenamiento (SC) detecta un problema con la tarjeta
CompactFlash durante el arranque.
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace el
módulo de controladora.
Información El sistema se inició normalmente y el dispositivo NV está en un estado esperado normal.
Este evento se registrará como un evento de Error o Advertencia si es necesaria alguna acción del
usuario.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
205 Información Se asignó o desasignó el volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
206 Información Se inició la limpieza del grupo de discos.
La limpieza verifica los discos en el grupo de discos en búsqueda de los siguientes tipos de errores:
● Errores de paridad de datos para un grupo de discos RAID 3, 5, 6 o 50.
● Errores de verificación de duplicación para un grupo de discos RAID 1 o RAID 10.
● Errores de medios para todos los niveles de RAID, incluyendo grupos de discos no RAID y RAID 0.
Cuando se detectan errores, se corrigen automáticamente.
Cuando la limpieza se completa, se registra el evento 207.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
207 Error Se completó la limpieza del grupo de discos y hay un número de errores excesivo en el grupo de discos
indicado.
Este evento se registra con gravedad de Error cuando se encuentran y corrigen más de
100 discordancias de paridad o duplicación durante una limpieza o cuando se encuentran y corrigen de
1 a 99 discordancias de paridad o duplicación durante cada una de 10 limpiezas del mismo grupo de
discos.
Para niveles de RAID sin tolerancia a fallas (RAID 0 y no RAID), los errores de medios pueden indicar una
pérdida de datos.
Acciones recomendadas:
● Resuelva los problemas de hardware que no sean de disco, como un problema de enfriamiento o una
fuente de alimentación, un módulo de controladora o un módulo de expansión defectuosos.
● Verifique si algún disco en el grupo de discos registró eventos de SMART o errores de lectura
irrecuperables.
○ Si es así y el grupo de discos tiene un nivel de RAID sin tolerancia a fallas (RAID 0 o no RAID),
copie los datos a un grupo diferente y reemplace los discos fallidos.
Eventos y mensajes de evento 97

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
○ Si es así y el grupo de discos tiene un nivel de RAID con tolerancia a fallas, verifique el estado
actual del grupo de discos. Si no es FTOL, respalde los datos, ya que podrían estar en riesgo. Si
es FTOL, reemplace el disco indicado. Si más de un disco en el grupo de discos registró un
evento de SMART, respalde los datos y reemplace todos los discos, uno a la vez. En
almacenamiento virtual, podría ser posible quitar el grupo de discos afectado, lo que volcará sus
datos en otro grupo y volverá a agregar el grupo de discos.
Aviso La limpieza del grupo de discos no se completó por una condición detectada internamente, como un
disco fallido. Si un disco falla, los datos podrían estar en riesgo.
Acciones recomendadas:
● Resuelva los problemas de hardware que no sean de disco, como un problema de enfriamiento o una
fuente de alimentación, un módulo de controladora o un módulo de expansión defectuosos.
○ Si es así y el grupo de discos tiene un nivel de RAID sin tolerancia a fallas (RAID 0 o no RAID),
copie los datos a un grupo diferente y reemplace los discos fallidos.
○ Si es así y el grupo de discos tiene un nivel de RAID con tolerancia a fallas, verifique el estado
actual del grupo de discos. Si no es FTOL, respalde los datos, ya que podrían estar en riesgo. Si
es FTOL, reemplace el disco indicado. Si más de un disco en el grupo de discos registró un
evento de SMART, respalde los datos y reemplace todos los discos, uno a la vez. En
almacenamiento virtual, podría ser posible quitar el grupo de discos afectado, lo que volcará sus
datos en otro grupo y volverá a agregar el grupo de discos.
Información La limpieza del grupo de discos se completó o fue cancelada por un usuario.
Este evento se registra con gravedad Informativa cuando se encuentran y corrigen menos de
100 errores de paridad o duplicación durante una limpieza.
Para niveles de RAID sin tolerancia a fallas (RAID 0 y no RAID), los errores de medios pueden indicar una
pérdida de datos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
208 Información Comenzó un trabajo de limpieza de disco para el disco indicado. El resultado se registrará como
evento 209.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
209 Error Se completó un trabajo de limpieza de disco registrado con el evento 208 y se encontraron uno o más
errores de medios, eventos de SMART o errores duros (no de medios). Si este disco se usa en un grupo
de discos sin tolerancia a fallas, puede haber una pérdida de datos.
Acciones recomendadas:
● Reemplace el disco por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o
mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un
rendimiento igual o mejor que el que está reemplazando.
Aviso Un usuario canceló un trabajo de limpieza de disco registrado con el evento 208, o se reasignó un bloque
de discos. Estos reemplazos de bloqueo erróneo se informan como "otros errores". Si este disco se usa
en un grupo de discos sin tolerancia a fallas, puede haber una pérdida de datos.
Acciones recomendadas:
● Supervise la tendencia del error y si el número de errores se aproxima al número total de repuestos
de bloque fallido disponibles.
Información Se completó sin errores un trabajo de limpieza de disco registrado con el evento 208, se agregó un disco
a un grupo de discos durante la limpieza (sin errores) o un usuario canceló el trabajo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
210 Información Se eliminaron todas las instantáneas para el volumen principal indicado cuando se usaba el
almacenamiento virtual.
98 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
211 Aviso La topología de SAS cambió. No se detectan elementos en la asignación de SAS. El mensaje especifica el
número de elementos en la asignación de SAS, el número de expansores detectados, el número de
niveles de expansión en el lado nativo (controladora local) y en el lado asociado (controladora asociada),
y el número de PHY del dispositivo.
Acciones recomendadas:
● Vuelva a realizar una exploración para volver a llenar la asignación de SAS.
● Si esto no resuelve el problema, apague y reinicie ambas controladoras de almacenamiento.
● Si el problema continúa, consulte Solución de problemas en la página 31.
Información La topología de SAS cambió. Aumentó o disminuyó el número de expansores de SAS. El mensaje
especifica el número de elementos en la asignación de SAS, el número de expansores detectados, el
número de niveles de expansión en el lado nativo (controladora local) y en el lado asociado (controladora
asociada), y el número de PHY del dispositivo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
212 Información Se eliminaron todos los volúmenes maestros asociados con un pool de instantáneas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
213 Información Un volumen maestro se convirtió en un volumen estándar o un volumen estándar se convirtió en un
volumen maestro
Acciones recomendadas:
● No es necesario realizar ninguna acción.
214 Información La creación de instantáneas se completó. Se indica la cantidad de instantáneas.
Los eventos adicionales proporcionan más información para cada instantánea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
215 Información Las instantáneas que se crearon anteriormente ahora se confirman y están listas para su uso. Los
eventos adicionales proporcionan más información para cada instantánea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
216 Información Se eliminó una instantánea sin confirmar. La extracción de la instantánea indicada se completó con éxito.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
217 Error Se produjo una falla del supercapacitor en la controladora.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
218 Aviso Está por terminar la vida útil del paquete de supercapacitor.
Acciones recomendadas:
● Reemplace el módulo de controladora que informó este evento.
219 Información Un usuario cambió la prioridad de utilidades.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Eventos y mensajes de evento 99

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
220 Información Un usuario inició la reversión de los datos en el volumen indicado a los datos en la instantánea indicada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
221 Información Se completó el restablecimiento de instantáneas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
222 Información Se configuró la política de pools de instantáneas. Un usuario cambió la política para el pool de
instantáneas. Una política especifica la acción que el sistema debe realizar automáticamente cuando el
pool de instantáneas alcanza el nivel de umbral asociado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
223 Información Se establecieron niveles de umbral del pool de instantáneas. Un usuario cambió el nivel de umbral para el
pool de instantáneas. Cada pool de instantáneas tiene tres niveles de umbral que le notifican cuando el
pool de instantáneas está llegando a la reducción de capacidad. Cada nivel de umbral tiene una política
asociada que especifica el comportamiento del sistema cuando se alcanza el umbral.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
224 Información Se completó la reversión de los datos en el volumen indicado a los datos en la instantánea indicada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
225 Error Se produjo una falla de copia en escritura al copiar datos desde un volumen maestro a una instantánea.
Debido a un problema de acceso al pool de instantáneas, no se pudo completar la operación de escritura
en el disco. Los datos quedan en la caché.
Acciones recomendadas:
● Elimine todas las instantáneas del volumen maestro y convierta el volumen maestro en un volumen
estándar.
226 Error No se inició una reversión porque no se pudo inicializar el pool de instantáneas. La reversión se
encuentra en un estado suspendido.
Acciones recomendadas:
● Asegúrese de que el pool de instantáneas y el pool en el que existe este volumen estén en línea.
Reinicie la operación de reversión.
227 Error Una reversión falló. No se pudo ejecutar la reversión para un determinado rango de LBA (dirección de
bloque lógico) del volumen primario indicado.
Acciones recomendadas:
● Reinicie la operación de reversión.
228 Error Una reversión no pudo finalizar porque no se pudo inicializar el pool de instantáneas. La reversión se
encuentra en estado suspendido.
Acciones recomendadas:
● Asegúrese de que el pool de instantáneas y el pool en el que existe este volumen estén en línea.
Reinicie la operación de reversión.
229 Aviso Se alcanzó el umbral de Advertencia para un pool de instantáneas.
Acciones recomendadas:
● Puede expandir el pool de instantáneas o eliminar instantáneas.
100 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
230 Aviso Se alcanzó el umbral de Error para un pool de instantáneas. Cuando se alcanza el umbral de error, el
sistema realiza automáticamente la acción configurada en la política para este nivel de umbral. La política
predeterminada para el umbral de error es expandir automáticamente el pool de instantáneas.
Acciones resultantes:
● Se eliminaron todas las instantáneas.
● Las operaciones de escritura se detuvieron en todas las instantáneas y los volúmenes maestros
asociados.
● Se eliminó la instantánea más antigua.
● Solo notificación; no se realizó ninguna acción.
● Se invalidaron todas las instantáneas.
● Se solicitó la expansión del pool de instantáneas
Acciones recomendadas:
● Puede expandir el pool de instantáneas o eliminar instantáneas.
231 Aviso Se alcanzó el umbral Crítico para un pool de instantáneas. Cuando se alcanza el umbral crítico, el sistema
realiza automáticamente la acción configurada en la política para este nivel de umbral. La política
predeterminada para el umbral crítico es eliminar todas las instantáneas en el pool de instantáneas.
Acciones resultantes:
● Se eliminaron todas las instantáneas.
● Las operaciones de escritura se detuvieron en todas las instantáneas y los volúmenes maestros
asociados.
● Se eliminó la instantánea más antigua.
● Solo notificación; no se realizó ninguna acción.
● Se invalidaron todas las instantáneas.
● Se solicitó la expansión del pool de instantáneas
Acciones recomendadas:
● Si la política es detener las escrituras, debe eliminar instantáneas para liberar espacio en el pool de
instantáneas.
232 Aviso Se superó el número máximo de gabinetes permitidos para la configuración actual.
La plataforma no es compatible con el número de gabinetes configurados. Se quitó el gabinete indicado
por este evento de la configuración.
Acciones recomendadas:
● Vuelva a configurar el sistema.
233 Aviso El tipo de disco indicado no es válido y la configuración actual no lo permite.
Todos los discos del tipo no permitido se quitaron de la configuración.
Acciones recomendadas:
● Reemplace los discos no permitidos con discos compatibles.
234 Error Un pool de instantáneas tuvo un error fatal y ya no se puede utilizar.
Acciones recomendadas:
● Todas las instantáneas asociadas con este pool de instantáneas son inválidas y es posible que desee
eliminarlas. Sin embargo, los datos en el volumen maestro pueden recuperarse convirtiéndolo en un
volumen estándar.
235 Error Un procesador de administración del gabinete (EMP) detectó un error grave.
Acciones recomendadas:
● Reemplace el módulo de expansión o el módulo de controladora indicado.
Información Un procesador de administración del gabinete (EMP) informó un evento.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Eventos y mensajes de evento 101

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
236 Error Se inició una operación de apagado especial. Estos tipos de apagado especial indican una función
incompatible.
Acciones recomendadas:
● Reemplace el módulo de controladora indicado con uno compatible con la función indicada.
Información Se inició una operación de apagado especial. Estos tipos de apagado especiales se utilizan como parte
del proceso de actualización de firmware.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
237 Error Se anuló un intento de actualización de firmware por problemas de estado del sistema generales o datos
en caché que no se pueden escribir y que se perderían durante una actualización de firmware.
Acciones recomendadas:
● Resuelva antes de volver a intentar una actualización de firmware. Para problemas de estado, emita
el comando de la CLI show system para determinar los problemas de estado específicos. Para
datos en caché no escritos, utilice el comando de la CLI show unwritable-cache
Información Una actualización de firmware se inició y está en progreso. Este evento proporciona detalles de los
pasos en una operación de actualización de firmware que podrían interesarle si tiene problemas con la
actualización de firmware.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
238 Aviso Falló un intento de instalar una función con licencia debido a una licencia no válida.
Acciones recomendadas:
● Verifique la licencia para ver qué está permitido para la plataforma, realice correcciones según
corresponda y vuelva a instalar.
239 Aviso Se produjo un error de tiempo de espera agotado durante el vaciado de la CompactFlash.
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace la
CompactFlash.
240 Aviso Se produjo una falla durante el vaciado de la CompactFlash.
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace la
CompactFlash.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace el
módulo de controladora.
241 Información Se resolvió el evento de activación de escritura simultánea automática que provocó que se genere el
evento 242.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
242 Error La tarjeta CompactFlash en el módulo de controladora falló.
Este cambio cumplió una condición para desencadenar la función de escritura simultánea automática,
que deshabilitó la caché con reescritura y puso el sistema en modo de escritura simultánea. Cuando se
resuelve la falla, se registra el evento 241 para indicar que se restauró el modo de escritura no
simultánea.
Acciones recomendadas:
102 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si el evento 241 no se registró desde que se registró este evento, la CompactFlash probablemente
no está en buen estado y deberá investigar la razón. Probablemente, se registró otro evento de
CompactFlash aproximadamente al mismo tiempo que este evento (como el evento 239, 240 o 481).
Consulte las acciones recomendadas para ese evento.
243 Información Se detectó un nuevo gabinete de controladora. Esto sucede cuando se pasa un módulo de controladora
de un gabinete a otro y la controladora detecta que la WWN del midplane es distinta de la WWN que
tiene en la memoria flash local.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
245 Información Un dispositivo de destino de canal de disco existente no responde a comandos de descubrimiento de
SCSI.
Acciones recomendadas:
● Verifique el dispositivo de destino indicado para ver si hay un cable o hardware en mal estado e inicie
una nueva exploración.
246 Aviso La batería de tipo botón no está presente, no está conectada correctamente o ha llegado al final del
ciclo de vida.
La batería proporciona alimentación de respaldo para el reloj de tiempo real (fecha/hora). En caso de
una falla de alimentación, la fecha y hora se revertirán a 1980-01-01 00:00:00.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
247 Aviso No se puede leer la SEEPROM de ID de FRU para la unidad reemplazable in situ (FRU) indicada. Los
datos de ID de FRU podrían no programarse.
Los datos de ID de FRU incluyen el nombre mundial, los números de serie, las versiones de hardware y
firmware, la información de marca, etc. Este evento se registra cada vez que una controladora de
almacenamiento (SC) se inicia para cada FRU no programada.
Acciones recomendadas:
● Devuelva la FRU para que se reprogramen los datos de ID de la FRU.
248 Información Se instaló una licencia de función válida correctamente. Consulte el evento 249 para obtener detalles
acerca de cada función con licencia.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
249 Información Una vez que se instala una licencia válida, este evento se registra para que cada función con licencia
muestre el nuevo valor de licencia para esa función. El evento especifica si la función tiene licencia, si la
licencia es temporal y si la licencia temporal está vencida.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
250 Aviso No se pudo instalar una licencia.
La licencia no es válida o especifica una función que no es compatible con el producto.
Acciones recomendadas:
● Revise el archivo Readme enviado con la licencia. Verifique que esté intentando instalar la licencia en
el sistema para el que se generó la licencia.
251 Información Se inició una operación de copia de volumen para el volumen de origen indicado.
No monte ninguno de los volúmenes hasta que se complete la copia (como lo indica el evento 268).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
252 Información Los datos escritos en una instantánea después de su creación se han eliminado.
Eventos y mensajes de evento 103

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
La instantánea ahora representa el estado del volumen primario cuando se creó la instantánea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
253 Información Se desinstaló una licencia.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
255 Información Las PBC entre controladoras no coinciden, ya que la PBC de la controladora A y la de la controladora B
son de diferentes proveedores.
Esto puede limitar las configuraciones disponibles.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
256 Información Se creó una instantánea para un volumen, pero aún no se confirmó.
Se creó una instantánea interna para un volumen de replicación virtual, pero aún no se ha confirmado.
Esto puede ocurrir cuando una aplicación toma una instantánea, como el proveedor de hardware de
VSS, que tiene una limitación de tiempo y debe tomar una instantánea en dos etapas. Una vez que se
confirma la instantánea y se registra el evento 258, se puede usar la instantánea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
257 Información La instantánea indicada se preparó y se confirmó, y está lista para su uso.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
258 Información Se confirmó una instantánea para un volumen. La instantánea ahora está lista para usar.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
259 Información Se deshabilitaron los comandos de CAPI dentro de banda.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
260 Información Se habilitaron los comandos de CAPI dentro de banda.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
261 Información Se deshabilitaron los comandos de SES dentro de banda.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
262 Información Se habilitaron los comandos de SES dentro de banda.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
263 Aviso No se encuentra el disco de repuesto indicado. Se quitó o no responde.
Acciones recomendadas:
● Reemplace el disco por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o
mayor capacidad.
● Configure el disco como repuesto.
266 Información Un usuario canceló una operación de copia de volumen para el volumen maestro indicado.
104 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
267 Error Se completó una operación de copia de volumen con una falla.
Este evento tiene dos variantes:
1. Si el volumen de origen es un volumen maestro, puede volver a montarlo. Si el volumen de origen es
una instantánea, no vuelva a montarlo hasta completar la copia (como lo indica el evento 268).
2. Las causas posibles son que el pool se esté quedando sin espacio disponible y esté superando el
umbral superior, que los volúmenes no estén disponibles o errores de I/O generales.
Acciones recomendadas:
● Para la variante 1: no es necesario realizar ninguna acción.
● Para la variante 2: busque otros eventos registrados aproximadamente al mismo tiempo que indicen
una falla de volumen o espacio de pool. Siga las acciones recomendadas para esos eventos.
268 Información Se completó una operación de copia de volumen para el volumen indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
269 Error No se pudo realizar una operación de actualización de firmware del partner.
Este evento tiene las siguientes variantes:
1. El estado del sistema no es suficiente para la compatibilidad con la actualización de firmware del
partner.
2. El sistema tiene datos en caché que no se pueden escribir.
3. No se puede determinar si hay datos en caché que no se pueden escribir.
4. Hay versiones de firmware incompatibles en los módulos de controladora.
5. Hay firmware incompatible en el sistema.
Acciones recomendadas:
● Para las variantes 1, 2 o 3: debe resolver esta condición antes de que continúe la actualización de
firmware. Inicie sesión en el sistema y ejecute el comando show system para identificar los
componentes en mal estado, y buscar recomendaciones para restaurar el estado del sistema. El
comando check firmware-upgrade-health se puede utilizar para verificar que el sistema
esté listo para la actualización de firmware. Para datos en caché no escritos, utilice el comando de la
CLI show unwritable-cache.
● Para la variante 4: esta función se puede volver a habilitar manualmente después de que ambos
módulos de la controladora ejecuten firmware compatible.
● Para la variante 5: los módulos de la controladora se deben actualizar a la versión más reciente del
firmware.
Información Se inició una operación de actualización de firmware asociado. Esta operación se utiliza para copiar
firmware de una controladora a otra, para tener ambas controladoras en la misma versión de firmware.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
270 Aviso Hubo un problema con la lectura o escritura de los datos de IP persistente de la SEEPROM de ID de
FRU, o se leyeron datos no válidos de la SEEPROM de ID de FRU.
Acciones recomendadas:
● Compruebe la configuración de IP (incluyendo la configuración de IP de puerto de host de iSCSI para
un sistema iSCSI) y actualícela si es incorrecta.
271 Información El sistema de almacenamiento no pudo obtener un número de serie válido de la SEEPROM de ID de
FRU, ya sea porque no pudo leer los datos de ID de FRU o porque los datos que contiene no son válidos
o no han sido programados. Por lo tanto, la dirección MAC se deriva con el número de serie de la
controladora desde la memoria flash. Este evento solo se registra una vez durante el arranque.
Acciones recomendadas:
Eventos y mensajes de evento 105

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● No es necesario realizar ninguna acción.
272 Información Se expandió un pool de instantáneas debido a un activador de políticas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
273 Información Un usuario habilitó o deshabilitó el aislamiento de fallas de PHY para el gabinete y el módulo de
controladora indicados.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
274 Aviso Un usuario deshabilitó la PHY indicada o esta se deshabilitó automáticamente. Las PHY de unidades se
deshabilitan automáticamente para ranuras de disco vacías o si se detecta un problema. Las siguientes
razones indican una probable falla de hardware:
● Deshabilitada por interrupciones de conteo de errores
● Deshabilitada por conteos de cambio de PHY excesivos
● PHY está lista pero no pasó COMINIT
Acciones recomendadas:
● Si no corresponde ninguna de las razones anteriores, no se requiere ninguna acción.
● Si se indica alguna de las razones enumeradas anteriormente y el evento sucede poco después de
encender el sistema de almacenamiento, realice lo siguiente:
○ Apague las controladoras de almacenamiento. Luego, apague la alimentación para el gabinete
indicado, espere unos segundos, y vuelva a encenderla.
○ Si el problema persiste y el mensaje de evento identifica una ranura de disco, reemplace el disco
en esa ranura.
○ Si el problema persiste y el mensaje de evento identifica un módulo, realice lo siguiente:
■ Si el tipo de PHY indicado es Egress, reemplace el cable en el puerto de egreso del módulo
■ Si el tipo de PHY indicado es Ingress, reemplace el cable en el puerto de ingreso del módulo
■ Para otros tipos de PHY indicados o si reemplazar el cable no soluciona el problema,
reemplace el módulo indicado.
○ Si el problema persiste, verifique si hay otros eventos que puedan indicar hardware defectuoso,
como un evento que indique una condición de temperatura superior al límite o falla de la fuente
de alimentación, y siga las acciones recomendadas para estos eventos.
○ Si el problema persiste, la falla podría estar en el midplane del gabinete. Reemplace la FRU del
chasis.
● Si se indica alguna de las razones enumeradas anteriormente y el evento se registra poco después
de una conmutación por errores, una nueva exploración iniciada por el usuario o un reinicio, realice lo
siguiente:
○ Si el mensaje de evento identifica una ranura de disco, vuelva a colocar el disco en esa ranura.
○ Si el problema persiste tras volver a colocar el disco, reemplace el disco.
○ Si el mensaje de evento identifica un módulo, realice lo siguiente:
■ Si el tipo de PHY indicado es Egress, reemplace el cable en el puerto de egreso del módulo.
■ Si el tipo de PHY indicado es Ingress, reemplace el cable en el puerto de ingreso del módulo.
■ Para otros tipos de PHY indicados o si reemplazar el cable no soluciona el problema,
reemplace el módulo indicado.
○ Si el problema persiste, verifique si hay otros eventos que puedan indicar hardware defectuoso,
como un evento que indique una condición de temperatura superior al límite o falla de la fuente
de alimentación, y siga las acciones recomendadas para estos eventos.
○ Si el problema persiste, la falla podría estar en el midplane del gabinete. Reemplace la FRU del
chasis.
275
Información Se habilitó la PHY indicada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
276 Información Se creó un conjunto en espejo.
106 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
277 Información Se eliminó un conjunto en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
278 Información Se verificó un conjunto en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
279 Información Se completó un comando de interrupción de componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
280 Información Se completó el comando de división de un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
281 Información Se completó un comando de unión de conjunto en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
282 Información Se completó el comando de reunión de un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
283 Información Se completó el comando de replateado de un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
284 Información Se eliminó un componente en espejo de un conjunto en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
285 Información Un almacén de marcador ya no se puede utilizar.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
286 Información Se inició la verificación para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
287 Información Se completó la verificación para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
288 Información Se anuló la verificación para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
289 Información Falló la verificación para un componente en espejo.
Eventos y mensajes de evento 107

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
290 Información Se produjo un error de I/O para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
291 Información Se inició el plateado para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
292 Información Se completó el plateado para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
293 Información Se canceló el plateado para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
294 Información Se completó un comando de quiebre para un componente en espejo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
295 Información Se completó un comando de división.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
296 Información Se completó un comando de unión.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
297 Información Se completó un comando de reunión.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
298 Aviso La configuración del reloj de tiempo real (RTC) en la controladora no es válida.
Este evento ocurrirá con más frecuencia después de una pérdida de alimentación si falló la batería del
reloj de tiempo real. La hora puede haberse establecido a un valor de hasta 5 minutos antes de la pérdida
de alimentación o podría haberse reiniciado a 1980-01-01 00:00:00.
Acciones recomendadas:
● Verifique la fecha y la hora del sistema. Si alguna es incorrecta, corríjala.
● Busque el evento 246 y siga la acción recomendada para ese evento.
Cuando se resuelve el problema, se registra el evento 299.
299 Información La configuración de RTC en la controladora se recuperó correctamente.
Este evento ocurrirá con más frecuencia después de una pérdida de alimentación inesperada.
Acciones recomendadas:
● No es necesario realizar ninguna acción, pero si el evento 246 también se registra, siga la acción
recomendada para ese evento.
300 Información La frecuencia de la CPU cambió a high.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
108 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
301 Información La frecuencia de la CPU cambió a low.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
302 Información La frecuencia de reloj de memoria DDR cambió a high.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
303 Información La frecuencia de reloj de memoria DDR cambió a low.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
304 Información La controladora detectó errores I
2
C que se pueden haber recuperado por completo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
305 Información Se descubrió que un número de serie en la memoria flash de la controladora de almacenamiento (SC) no
era válido cuando se comparó con el número de serie en el SEEPROM de ID de FRU del midplane o el
módulo de controladora. El número de serie válido se recuperó automáticamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
306 Información Se descubrió que un número de serie del módulo de la controladora en la memoria flash de la
controladora de almacenamiento (SC) no era válido cuando se comparó con el número de serie en el
SEEPROM de ID de FRU del módulo de controladora. El número de serie válido se recuperó
automáticamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
307 Crítico Un sensor de temperatura en una FRU de controladora detectó una condición de temperatura superior
al límite que provocó que se apague la controladora.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
Si el problema persiste, reemplace el módulo de controladora que registró el error.
309 Información Normalmente, cuando se inicia la controladora de administración (MC), los datos de IP se obtienen del
SEEPROM de ID de FRU del midplane donde persiste. Si el sistema no puede escribirlos a la SEEPROM
en el último cambio, se establece una marca en la memoria flash. Esta marca se verifica durante el inicio
y, si está establecida, se registra este evento y se utilizan los datos de IP de la memoria flash. La única
ocasión en que estos datos de IP no serían correctos es el caso en que el módulo de controladora se
intercambió; en ese caso, se utiliza cualquier dato en la memoria flash de la controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
310 Información Después de una nueva exploración, se completó la inicialización y el descubrimiento de back-end para al
menos un EMP (procesador de administración del gabinete). Este evento no se vuelve a registrar
cuando se completa el procesamiento para otros EMP del sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Eventos y mensajes de evento 109

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
311 Información Este evento se registra cuando un usuario inicia un ping de un host mediante la interfaz de iSCSI.
Acciones recomendadas:
● Si la operación de ping falló, verifique la conectividad entre el sistema de almacenamiento y el host
remoto.
312 Información Las capturas de SNMP y los correos electrónicos utilizan este evento cuando prueban ajustes de
notificaciones. Este evento no se guarda en el registro de eventos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
313 Error Falló el módulo de controladora indicado. Se puede ignorar este evento para una configuración de
controladora única.
Acciones recomendadas:
● Si se trata de un sistema de controladora doble, reemplace el módulo de controladora fallido. El LED
correspondiente de servicio/falla del módulo se iluminará (sin parpadear).
314 Error La FRU indicada falló o no funciona correctamente. Este evento sigue a otros eventos específicos de
FRU que indican un problema.
Acciones recomendadas:
● Para determinar si se debe reemplazar la FRU, consulte el tema sobre la verificación de falla de
componentes en la Guía de instalación y mantenimiento de hardware del producto.
315 Crítico Este IOM no es compatible con el gabinete en que se inserta.
Acciones recomendadas:
● Reemplace este IOM con uno compatible con el gabinete.
316 Aviso Se venció la licencia temporal para una función.
Aún se puede acceder a cualquier componente creado con la función, pero no se pueden crear nuevos
componentes.
Acciones recomendadas:
● Para seguir utilizando la función, compre una licencia permanente.
Información La licencia temporal de una función vencerá en 10 días. Aún se podrá acceder a cualquier componente
creado con la función, pero no se podrán crear nuevos componentes.
Acciones recomendadas:
● Para continuar utilizando la función después del periodo de prueba, compre una licencia permanente.
317 Error Se detectó un error grave en la interfaz de disco de la controladora de almacenamiento. La controladora
del partner desactivará esta controladora.
Acciones recomendadas:
● Realice un seguimiento visual del cableado entre los módulos de controladora y de expansión.
● Si el cableado está en buen estado, reemplace el módulo de controladora que registró este evento.
● Si el problema persiste, reemplace el módulo de expansión conectado al módulo de controladora.
319 Aviso El disco disponible indicado falló.
Acciones recomendadas:
● Reemplace el disco por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o
mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un
rendimiento igual o mejor que el que está reemplazando.
322 Aviso La controladora tiene una versión de controladora de almacenamiento (SC) anterior a la utilizada para
crear la base de datos de autenticación de CHAP en la memoria flash de la controladora.
110 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
No se puede leer o actualizar la base de datos de CHAP. Sin embargo, se pueden agregar nuevos
registros, que reemplazarán la base de datos existente con una nueva mediante el último número de
versión conocido.
Acciones recomendadas:
● Actualice el firmware de la controladora a una versión cuya SC sea compatible con la versión de base
de datos indicada.
○ Si no se agregaron registros, se puede acceder a la base de datos y permanece intacta.
○ Si se agregaron registros, se puede acceder a la base de datos pero solo contiene los nuevos
registros.
352 Información Están disponibles los datos de volcado de pila o datos de aserción de la controladora del expansor (EC).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
353 Información Se borraron los datos de volcado de pila y datos de aserción de la controladora del expansor (EC).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
354 Aviso Cambió la topología de SAS en un puerto de host. Se desactivó al menos una PHY. Por ejemplo, se
desconectó el cable de SAS que conectaba un puerto de host de controladora a un host.
Acciones recomendadas:
● Compruebe la conexión del cable entre el puerto indicado y el host.
● Supervise el registro para ver si el problema persiste.
Información Cambió la topología de SAS en un puerto de host. Se activó al menos una PHY. Por ejemplo, se conectó
el cable de SAS que conectaba un puerto de host de controladora a un host.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
356 Aviso Este evento solo puede ser el resultado de pruebas ejecutadas en el ambiente de fabricación.
Acciones recomendadas:
● Siga el proceso de fabricación.
357 Aviso Este evento solo puede ser el resultado de pruebas ejecutadas en el ambiente de fabricación.
Acciones recomendadas:
● Siga el proceso de fabricación.
358 Crítico Todas las PHY están desactivadas para el canal de disco indicado. El sistema está degradado y no es
tolerante a fallas, ya que todos los discos están en un estado de puerto único.
NOTA: Los sistemas de la ME4 Series solo admiten discos de dos puertos.
Acciones recomendadas:
● Apague la alimentación del gabinete de la controladora, espere unos segundos y vuelva a encenderla.
● Si el evento 359 se registró para el canal indicado, es decir, la condición ya no existe, no es necesario
realizar ninguna acción.
● Si la condición persiste, esto indica un problema de hardware en uno de los módulos de controladora
o en el midplane del gabinete de controladora. Para obtener ayuda a fin de identificar la FRU que
debe reemplazar, consulte Solución de problemas en la página 31.
Aviso Algunas PHY, pero no todas, están desactivadas para el canal de disco indicado.
Acciones recomendadas:
● Supervise el registro para ver si la condición persiste.
● Si el evento 359 se registró para el canal indicado, es decir, la condición ya no existe, no es necesario
realizar ninguna acción.
Eventos y mensajes de evento 111

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si la condición persiste, esto indica un problema de hardware en uno de los módulos de controladora
o en el midplane del gabinete de controladora. Para obtener ayuda a fin de identificar la FRU que
debe reemplazar, consulte Solución de problemas en la página 31.
359 Información Todas las PHY que estaban desactivadas para el canal de disco indicado se recuperaron y están activas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
360 Información Se renegoció la velocidad de la PHY del disco indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
361 Crítica, Error o
Advertencia
El programador tuvo un problema con el programa indicado.
Acciones recomendadas:
● Realice las acciones correspondientes según el problema indicado.
Información Se inició una tarea programada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
362 Crítica, Error o
Advertencia
El programador tuvo un problema con la tarea indicada.
Acciones recomendadas:
● Realice las acciones correspondientes según el problema indicado.
Información El programador tuvo un problema con la tarea indicada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
363 Error Cuando se reinicia la controladora de administración (MC), las versiones de firmware instaladas
actualmente se comparan con las del paquete instalado más recientemente. Cuando se actualiza el
firmware, es importante que se actualicen todos los componentes correctamente o el sistema podría no
funcionar. Los componentes verificados incluyen el CPLD, la controladora del expansor (EC), la
controladora de almacenamiento (SC) y la MC.
Acciones recomendadas:
● Vuelva a instalar el paquete de firmware.
Información Cuando se reinicia la controladora de administración (MC), las versiones de firmware instaladas
actualmente se comparan con las del paquete instalado más recientemente. Si las versiones coinciden,
este evento se registra con gravedad Informativa. Los componentes verificados incluyen el CPLD, la
controladora del expansor (EC), la controladora de almacenamiento (SC) y la MC.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
364 Información El bus de transmisión está funcionando como generación 1.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
365 Error Se produjo un error de ECC incorregible en la memoria de la CPU de la controladora de almacenamiento
más de una vez, indicando una probable falla de hardware.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
Aviso Se produjo un error de ECC incorregible en la memoria de la CPU de la controladora de almacenamiento.
112 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Este evento se registra con gravedad de Advertencia para proporcionar información que puede resultar
útil al soporte técnico, pero no es necesario realizar ninguna acción en este momento. Se registrará con
gravedad de Error, si es necesario, para reemplazar el módulo de controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
400 Información El registro indicado se llenó y debe ser transferido a un sistema de recopilación de registros.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
401 Aviso El registro indicado se llenó y los datos de diagnóstico se perderán si no se transfiere a un sistema de
recopilación de registros.
Acciones recomendadas:
● Transfiera el archivo de registro al sistema de recopilación de registros.
402 Error El registro indicado se encapsuló y comenzó a sobrescribir los datos de diagnóstico más antiguos.
Acciones recomendadas:
● Investigue por qué el sistema de recopilación de registros no transfiere los registros antes de
sobrescribirlos. Por ejemplo, podría haber habilitado los registros administrados sin configurar un
destino para enviar registros.
412 Aviso Un disco en el grupo de discos RAID-6 indicado falló. El grupo de discos está en línea, pero con un
estado de FTDN (tolerante a fallas con un disco desactivado).
Si hay un repuesto dedicado (solo lineal) o un repuesto global del tipo y tamaño adecuados, se usa para
reconstruir el grupo de discos automáticamente. Para indicar esto, se registran los eventos 9 y 37. Si no
hay ningún disco de repuesto, pero hay un disco disponible del tipo y tamaño adecuados, y la función de
repuestos dinámicos está habilitada, ese disco se utiliza para reconstruir el grupo de discos
automáticamente y se registra el evento 37.
Acciones recomendadas:
RAID 6:
● Si el evento 37 no se registró, no había un repuesto del tamaño y tipo adecuados para la
reconstrucción. Reemplace el disco fallido con uno del mismo tipo y de la misma o mayor capacidad,
y, si es necesario, desígnelo como repuesto. Verifique si se registran los eventos 9 y 37 para
confirmar esto.
● De lo contrario, la reconstrucción comenzó automáticamente y se registró el evento 37. Reemplace
el disco fallido y configure el repuesto como un repuesto dedicado (solo lineal) o un repuesto global
para usarlo en el futuro.
● Para un rendimiento de I/O óptimo y continuo, el disco de repuesto debería tener el mismo
rendimiento o un mejor rendimiento.
● Confirme que haya reemplazado todos los discos fallidos y que haya suficientes discos de repuesto
configurados para usarlos en el futuro.
ADAPT:
● Si no se registró el evento 37, el espacio de repuesto no estaba disponible para la reconstrucción.
Reemplace el disco fallido por uno del mismo tipo y la misma capacidad o mayor capacidad. La
reconstrucción debería comenzar y el evento 37 se debería registrar automáticamente.
● Para un rendimiento de I/O óptimo y continuo, el disco de repuesto debería tener el mismo
rendimiento o un mejor rendimiento.
● Confirme el reemplazo de todos los discos fallidos para la futura tolerancia a fallas.
413
Información Una solicitud para crear un conjunto de replicación se completó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
414 Error Una solicitud para crear un conjunto de replicación falló.
Eventos y mensajes de evento 113

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Esta operación no se permite si el volumen especificado ya está en un conjunto de replicación o no es un
volumen maestro.
Acciones recomendadas:
● Si el volumen es un volumen maestro y no se encuentra en un conjunto de replicación, vuelva a
intentar la operación.
415 Información Una solicitud para eliminar un conjunto de replicación se completó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
416 Error Una solicitud para eliminar un conjunto de replicación falló.
Esto puede ocurrir si se especificó un identificador no válido para el conjunto de replicación o si el
volumen primario especificado no está en el sistema local.
Acciones recomendadas:
● Repita la eliminación mediante un identificador de conjunto de replicación válido o en el sistema local
para el volumen principal.
417 Información Se eliminó una instantánea.
● Para crear espacio para un volumen de proxy de instantánea remota.
● Para crear espacio para una nueva instantánea.
● Al cambiar un volumen secundario a un volumen principal.
● Para crear espacio para una nueva instantánea, ya que se alcanzó el número máximo de instantáneas
por volumen.
● Para crear espacio para una nueva instantánea, ya que se alcanzó el número máximo de instantáneas
de replicación por sistema.
● Para crear espacio por un motivo desconocido.
Se eliminó una instantánea virtual porque se superó el límite de espacio de instantáneas especificado por
el usuario.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
418 Aviso Falló una operación de instantánea remota.
● Porque se alcanzó el límite de volumen del pool remoto.
● Porque se alcanzó el límite de volumen de la controladora remota.
● Porque se alcanzó el límite de volumen del pool remoto.
● Debido a un motivo desconocido.
Una operación de replicación no se puede completar porque debe crear un volumen de proxy y una
instantánea de replicación en el pool secundario, pero el número máximo de volúmenes existe para ese
pool o su controladora propietaria y el pool no contiene ninguna instantánea adecuada para eliminar
automáticamente.
Este evento se registra en el sistema del volumen secundario únicamente.
Acciones recomendadas:
● Para permitir que la operación de replicación continúe, elimine al menos un volumen que no sea
necesario del pool de destino o de otro pool que pertenezca a la misma controladora. Después de
realizar la acción anterior, si la replicación falla por el mismo motivo y se suspende, se registrarán los
eventos 431 y 418. Repita la acción anterior y reanude la replicación.
● Para permitir que se creen volúmenes adicionales en el futuro (volúmenes estándar, volúmenes de
replicación o instantáneas), elimine los volúmenes que no sean necesarios.
419 Información Se inició una solicitud para agregar un volumen secundario.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
420 Error Falló una solicitud para agregar un volumen secundario.
114 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Esto puede ocurrir por varios motivos, como los siguientes:
● El volumen ya es un volumen de replicación.
● El volumen no es local en el sistema.
● El vínculo de comunicación está ocupado o se ha producido un error.
● El volumen no tiene el mismo tamaño que el volumen existente o ya no está en el conjunto.
● El registro del volumen no está actualizado.
● La replicación no tiene licencia o se superaría el límite de licencias.
Acciones recomendadas:
● Si ocurre alguno de los problemas anteriores, resuélvalo. A continuación, repita la operación de
adición con un volumen válido.
421 Información Una solicitud para agregar un volumen secundario se completó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
422 Información Una solicitud para eliminar un volumen secundario se completó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
423 Error Falló una solicitud para eliminar un volumen secundario.
Esto puede ocurrir por varios motivos, como los siguientes:
● No se encuentra el registro del volumen.
● El registro del volumen aún no está disponible.
● Existe un conflicto de volumen principal.
● No puede eliminar el volumen desde un sistema remoto.
● No puede eliminar el volumen debido a que es el volumen principal.
Acciones recomendadas:
● Si ocurre alguno de los problemas anteriores, resuélvalo. A continuación, repita la operación de
eliminación con un volumen válido.
424 Información Una solicitud para modificar un volumen secundario se completó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
425 Información Se inició una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
426 Información Se completó una replicación correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
427 Aviso
● Falló un intento de un volumen principal de enviar una etiqueta de configuración local a un volumen
remoto.
● Falló un intento de un volumen secundario de enviar una etiqueta de configuración local a un
volumen remoto.
● Falló un intento de enviar una etiqueta de configuración local a un volumen remoto.
Se produjo un error de comunicación al enviar información entre sistemas de almacenamiento.
Acciones recomendadas:
● Compruebe la red o la red fabric por problemas de conectividad o de congestión anormalmente alta.
428 Información Un usuario suspendió una replicación.
Eventos y mensajes de evento 115

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
429 Información Un usuario reanudó una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
430 Información Un usuario canceló una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
431 Error Se suspendió una replicación debido a un error o se suspendió la replicación debido a un error de medios
en un volumen principal. Se requiere intervención del usuario para reanudar la replicación.
Se suspendió la replicación al volumen indicado debido a un error detectado durante el proceso de
replicación. Esto puede ocurrir por varios motivos, como los siguientes:
● Se canceló la solicitud de caché.
● La caché detectó que el volumen de origen o de destino está desconectado.
● La caché detectó un error de medios.
● El pool de instantáneas está lleno.
● El vínculo de comunicación está ocupado o se ha producido un error.
● La instantánea que se utiliza para la replicación no es válida.
● Se produjo un problema al establecer la comunicación del proxy.
Acciones recomendadas:
● Si el problema informado es de un volumen principal, respalde el volumen tanto como sea posible.
● Resuelva el error y reanude la replicación.
432 Error Se canceló una replicación debido a un error en un volumen secundario.
Acciones recomendadas:
● Verifique que el volumen secundario sea válido y que se pueda acceder al sistema en que reside el
volumen.
433 Información Se omitió una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
434 Aviso Una replicación entró en conflicto con una replicación en curso.
Esto puede ser una funcionamiento normal, pero, en algunos casos, puede indicar un problema.
Acciones recomendadas:
● Asegúrese de que no haya problemas de red.
● Asegúrese de que haya suficiente ancho de banda entre los sistemas principal y secundario.
● Asegúrese de que el intervalo entre replicaciones esté configurado en una cantidad suficiente de
tiempo para permitir que se completen las replicaciones. Tener demasiadas replicaciones en línea de
espera puede provocar que algunas no se completen.
435 Aviso Un conjunto de replicación no se pudo inicializar. La versión del firmware del sistema remoto no es
compatible con el sistema local.
Acciones recomendadas:
● Actualice el firmware en uno o ambos sistemas para que ejecuten la misma versión.
● Compruebe la red o la red fabric por problemas de conectividad o de congestión anormalmente alta.
436 Aviso El firmware del sistema remoto no es compatible con el firmware del sistema local, de modo que no se
pueden comunicar entre sí para realizar operaciones de replicación.
Acciones recomendadas:
116 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Actualice el firmware en uno o ambos sistemas para que ejecuten la misma versión.
437 Información Un usuario inició una solicitud para cambiar el volumen principal de un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
438 Información Una solicitud de un usuario para cambiar el volumen principal de un conjunto de replicación se completó
correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
439 Error Falló una solicitud para cambiar un volumen principal.
Esto puede ocurrir por varios motivos, como los siguientes:
● El volumen no está en el conjunto de replicación.
● No se encontraron la etiqueta de configuración o los datos de configuración.
● Se alcanzó el límite de reintentos.
Acciones recomendadas:
● Verifique que el volumen especificado forme parte del conjunto de replicación.
● Verifique que no haya problemas de red que impidan la comunicación entre los sistemas de
almacenamiento local y remoto.
440 Aviso Se está reintentando una replicación debido a un error en el volumen secundario.
Esto puede ocurrir por varios motivos, como los siguientes:
● Se canceló la solicitud de caché.
● La caché detectó que el volumen de origen o de destino está desconectado.
● La caché detectó un error de medios.
● El pool de instantáneas está lleno.
● El vínculo de comunicación está ocupado o se ha producido un error.
● La instantánea que se utiliza para la replicación no es válida.
● Se produjo un problema al establecer la comunicación del proxy.
●
La replicación se reintenta automáticamente según las políticas configuradas. Si el problema se
resuelve antes de que se agoten los reintentos, la replicación continuará por sí misma. De lo
contrario, entrará en un estado suspendido, a menos que la política esté configurada para reintentar
para siempre.
Acciones recomendadas:
● Si ocurre alguno de los problemas anteriores, resuélvalo.
441 Error Una solicitud para agregar un volumen secundario falló. Es necesaria la intervención del usuario para
eliminar el volumen del conjunto.
Acciones recomendadas:
● Elimine el volumen secundario indicado del conjunto de replicación.
442 Aviso Los diagnósticos de la prueba de encendido automático (POST) detectaron un error de hardware en un
chip UART.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
443 Error El firmware para el gabinete indicado no es compatible con esta configuración.
El firmware para el gabinete indicado no es compatible con este gabinete para su uso como un chasis de
expansión. El firmware es compatible con este gabinete solo como JBOD de conexión directa.
Acciones recomendadas:
● Reemplace el gabinete indicado. No es compatible.
Eventos y mensajes de evento 117

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
444 Información Un pool de instantáneas se está quedando sin espacio.
Un pool de instantáneas alcanzó un umbral de capacidad y la política asociada se completó
correctamente:
● Eliminar instantáneas
● Detener escrituras
● Eliminar la instantánea más antigua
● Solo notificar
● Invalidar instantáneas
● Expandir automáticamente
● Política desconocida
Por ejemplo, el pool de instantáneas se expandió correctamente, se eliminó la instantánea más antigua o
se eliminaron todas las instantáneas. Si la política es Eliminar la instantánea más antigua, se informa el
número de serie de la instantánea eliminada.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Aviso Un pool de instantáneas se está quedando sin espacio.
Un pool de instantáneas alcanzó un umbral de capacidad y la política de expansión automática asociada
falló debido a que no hay suficiente espacio disponible en el grupo de discos.
Acciones recomendadas:
● Expanda el grupo de discos o elimine los volúmenes que no sean necesarios para aumentar el espacio
disponible en el grupo de discos.
449 Información Se canceló una reversión debido a un error u otra condición detectada internamente.
Esto puede ocurrir si hay una reversión en curso y un usuario decide revertir un volumen diferente, lo
que cancelará la primera reversión e iniciará una nueva. Un usuario no puede cancelar explícitamente una
reversión debido a que podría dañar el volumen primario.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
450 Aviso El estado de un volumen remoto cambió de en línea a offline.
Esto puede ocurrir por varios motivos, como los siguientes:
● El vínculo de comunicación está ocupado o se ha producido un error.
● Ocurrió un error en el iniciador local.
Acciones recomendadas:
● Verifique que no haya problemas de red que impidan la comunicación entre los sistemas de
almacenamiento local y remoto.
451 Información El estado de un volumen remoto cambió de offline a en línea.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
452 Información Un volumen remoto se desconectó correctamente de un conjunto de replicación.
El volumen ahora se puede mover físicamente a otro sistema de almacenamiento.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
453 Información Un volumen remoto se volvió a conectar correctamente a un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
118 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
454 Información Un usuario cambió la demora de desactivación de la unidad para el grupo de discos indicado al valor
indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
455 Aviso La controladora detectó que la velocidad de vínculo de puerto de host configurada superó la
funcionalidad de un SFP de FC. La velocidad se redujo automáticamente al valor máximo compatible con
todos los componentes de hardware en la ruta de datos.
Acciones recomendadas:
● Reemplace el SFP del puerto indicado con un SFP compatible con mayor velocidad.
456 Aviso El IQN del sistema se generó desde la OUI predeterminada porque las controladoras no pudieron leer la
OUI desde los datos de ID de FRU del midplane durante el inicio. Si el IQN no es el correcto para la
marca del sistema, es posible que los hosts de iSCSI no puedan acceder al sistema.
Acciones recomendadas:
● Si se registra el evento 270 con el código de estado 0 aproximadamente al mismo tiempo, reinicie las
controladoras de almacenamiento.
457 Información Se creó el pool virtual indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
458 Información Se agregaron grupos de discos al pool virtual indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
459 Información Se inició la extracción de los grupos de discos indicados.
Cuando se completa esta operación, se registra el evento 470.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
460 Error El grupo de discos indicado no está en el pool virtual indicado.
Esto puede ser a causa de unidades faltantes o gabinetes apagados o desconectados.
Acciones recomendadas:
● Asegúrese de que todos los discos estén instalados y de que los gabinetes estén conectados y
encendidos. Cuando se resuelve el problema, se registra el evento 461.
461 Información Se recuperó el grupo de discos indicado que no estaba en el pool virtual indicado.
Este evento indica que se resolvió un problema informado por el evento 460.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
462 Error El pool virtual indicado alcanzó su límite de almacenamiento.
Hay tres umbrales, dos de los cuales puede definir el usuario. La controladora establece el tercer y más
alto ajuste automáticamente, y no se puede cambiar. Este evento se registra con gravedad de
Advertencia si se supera el umbral superior y se sobreasigna el pool virtual. Sobreasignado significa que
el tamaño asignado total de todos los virtual volumes supera el espacio físico del pool virtual. Si el uso del
almacenamiento se reduce a un nivel inferior al de un umbral, se registra el evento 463.
Acciones recomendadas:
● Deberá tomar medidas inmediatamente para reducir el uso de almacenamiento o agregar capacidad.
Aviso El conjunto virtual indicado superó el umbral superior para páginas asignadas, y el conjunto virtual está
sobreasignado.
Eventos y mensajes de evento 119

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Hay tres umbrales, dos de los cuales puede definir el usuario. La controladora establece el tercer y más
alto ajuste automáticamente, y no se puede cambiar. Este evento se registra con gravedad de
Advertencia si se supera el umbral superior y se sobreasigna el pool virtual. Sobreasignado significa que
el tamaño asignado total de todos los virtual volumes supera el espacio físico del pool virtual. Si el uso del
almacenamiento se reduce a un nivel inferior al de un umbral, se registra el evento 463.
Acciones recomendadas:
● Deberá tomar medidas inmediatamente para reducir el uso de almacenamiento o agregar capacidad.
Información El pool virtual indicado supera uno de los umbrales para páginas asignadas.
Hay tres umbrales, dos de los cuales puede definir el usuario. La controladora establece el tercer y más
alto ajuste automáticamente, y no se puede cambiar. Este evento se registra con gravedad de
Advertencia si se supera el umbral superior y se sobreasigna el pool virtual. Sobreasignado significa que
el tamaño asignado total de todos los virtual volumes supera el espacio físico del pool virtual. Si el uso del
almacenamiento se reduce a un nivel inferior al de un umbral, se registra el evento 463.
Acciones recomendadas:
● No es necesario realizar ninguna acción para los umbrales bajo e intermedio. Sin embargo, quizá
desee determinar si su uso del almacenamiento crece a una tasa que superará el umbral superior en
un futuro cercano. Si determina que ocurrirá esto, tome medidas para reducir el uso de
almacenamiento o adquiera capacidad adicional.
● Si se supera el umbral superior, deberá tomar medidas para reducir el uso de almacenamiento o
agregar capacidad inmediatamente.
463 Información El espacio del pool virtual indicado se redujo a un nivel inferior al de uno de los umbrales para páginas
asignadas.
Este evento indica que ya no corresponde una condición informada por el evento 462.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
464 Aviso Un usuario insertó un SFP o cable no compatible en el puerto de host de controladora indicado.
Acciones recomendadas:
● Reemplace el cable o SFP con un tipo compatible.
465 Información Un usuario quitó un SFP o cable no compatible del puerto de host de controladora indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
466 Información Se eliminó el pool virtual indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
467 Información Se agregó el grupo de discos indicado correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
468 Información La temperatura del FPGA regresó al rango de funcionamiento normal y se restauró la velocidad de los
buses que conectan el FPGA a los adaptadores descendentes. Se redujo la velocidad para compensar
por una condición de temperatura superior al límite de la FPGA.
Este evento indica que se resolvió un problema informado por el evento 469.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
469 Aviso Se redujo la velocidad de los buses que conectaban la FPGA a los adaptadores descendentes para
compensar por una condición de temperatura superior al límite de la FPGA.
120 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
El sistema de almacenamiento funciona, pero se redujo el rendimiento de I/O.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
● Si ninguna de las acciones recomendadas resuelve el problema, reemplace el módulo de controladora
que registró el error.
Cuando se resuelve el problema, se registra el evento 468.
470 Aviso Se completó la extracción de los grupos de discos indicados con fallas.
La extracción de grupos de discos puede fallar por varios motivos, y la razón específica de la falla se
incluye con el evento. La extracción falla a menudo porque no queda lugar en el espacio de pool restante
para mover páginas de datos fuera de los discos del grupo de discos.
Acciones recomendadas:
● Resuelva el problema especificado por el mensaje de error incluido con este evento y vuelva a emitir
la solicitud para quitar el grupo de discos.
Información Se completó la extracción de los grupos de discos indicados correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
471 Error Una replicación se puso en línea de espera porque el volumen secundario está desconectado.
Acciones recomendadas:
● Para permitir que la replicación continúe, vuelva a conectar el volumen secundario y reanude la
replicación.
473 Información El volumen indicado utiliza un porcentaje mayor al del umbral del pool virtual.
Esto indica que el uso de almacenamiento superó el umbral especificado por el usuario para este
volumen. Si el uso de almacenamiento se reduce a un nivel inferior al de un umbral, se registra el
evento 474.
Acciones recomendadas:
● No es necesario realizar ninguna acción. El uso de esta información queda a discreción del usuario.
474 Información El volumen indicado ya no utiliza un porcentaje mayor al del umbral del pool virtual.
Este evento indica que ya no corresponde la condición informada por el evento 473.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
475 Información La replicación se puso en línea de espera porque el volumen secundario está en estado offline.
Acciones recomendadas:
● Para permitir que la replicación continúe, solucione el problema que impide el acceso al volumen
secundario.
476 Aviso La temperatura de la CPU superó el rango seguro, por lo cual la CPU ingresó al estado de protección
automática. Se redujeron las IOPS.
El sistema de almacenamiento funciona, pero se redujo el rendimiento de I/O.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
Eventos y mensajes de evento 121

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
● Si ninguna de las acciones recomendadas resuelve el problema, reemplace el módulo de controladora
que registró el error.
Cuando se resuelve el problema, se registra el evento 478.
477 Información La temperatura de la CPU superó el rango normal, por lo cual se redujo la velocidad de CPU. Se
redujeron las IOPS.
El sistema de almacenamiento funciona, pero se redujo el rendimiento de I/O.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
●
Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
● Si ninguna de las acciones recomendadas resuelve el problema, reemplace el módulo de controladora
que registró el error.
Cuando se resuelve el problema, se registra el evento 478.
478 Información Se resolvió un problema informado por el evento 476 o el 477.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
479 Error La controladora que informó este evento no pudo vaciar o restaurar datos de memoria no volátil.
Esto probablemente indica una falla de CompactFlash, pero puede ser resultado de algún otro problema
con el módulo de controladora. La controladora asociada desactivará la controladora de almacenamiento
que registró este evento y utilizará su propia copia de los datos para realizar el vaciado o restaurar el
funcionamiento.
Acciones recomendadas:
● Si este evento se registra por primera vez, reinicie la controladora de almacenamiento desactivada.
● Si, a continuación, se vuelve a registrar este evento, reemplace la CompactFlash.
● Si, a continuación, este evento se registra nuevamente, apague la controladora de almacenamiento y
reemplace el módulo de controladora.
480 Error Se ha detectado un conflicto de dirección IP para el puerto iSCSI indicado del sistema de
almacenamiento. La dirección IP indicada ya estaba en uso.
Acciones recomendadas:
● Comuníquese con su administrador de red de datos para ayudar a solucionar el conflicto de dirección
IP.
481 Error El monitor periódico de hardware de CompactFlash detectó un error. La controladora pasó a modo de
escritura simultánea, que reduce el rendimiento de I/O.
Acciones recomendadas:
● Reinicie la controladora de almacenamiento que registró este evento.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace la
CompactFlash.
● Si este evento se registra nuevamente, apague la controladora de almacenamiento y reemplace el
módulo de controladora.
482 Aviso Uno de los buses de PCIe funciona con menos canales de los que debería.
122 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Este evento es el resultado de un problema de hardware que provocó que la controladora utilice menos
canales. El sistema funciona con menos canales, pero se degrada el rendimiento de I/O.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
483 Error Se detectó una conexión de módulo de expansión no válida para el canal de discos indicado. Hay un
puerto de egreso conectado a otro puerto de egreso o un puerto de ingreso conectado a un puerto de
egreso incorrecto.
Acciones recomendadas:
● Realice un seguimiento visual del cableado entre los gabinetes y corríjalo.
484 Aviso No hay repuestos compatibles disponibles para reconstruir este grupo de discos si experimenta una falla
de disco. Solo los grupos de discos con repuestos globales adecuados o dedicados comenzarán la
reconstrucción automática.
Esta situación pone los datos en un mayor riesgo, ya que se necesita la acción del usuario para
configurar un disco como repuesto global o dedicado antes de poder comenzar la reconstrucción en el
grupo de discos indicado, si un disco en ese grupo falla en un futuro.
Si se eliminó el último repuesto global o se utilizó para la reconstrucción, TODOS los grupos de disco que
no tienen al menos un repuesto global o dedicado están en mayor riesgo. Tenga en cuenta que, aunque
aún podrían haber repuestos globales disponibles, no se pueden usar para la reconstrucción de un grupo
de discos si ese grupo utiliza discos de mayor capacidad o de un tipo diferente. Por lo tanto, este evento
se puede registrar aunque hayan repuestos globales sin utilizar. Si la función de repuestos dinámicos
está habilitada, se registrará este evento aunque haya un disco disponible que se pueda utilizar para la
reconstrucción.
Acciones recomendadas:
● Configure discos como repuestos dedicados o repuestos globales.
○ Para un repuesto dedicado, el disco debe ser del mismo tipo que los demás en el grupo de discos
lineales y al menos tan grande como el disco de menor capacidad en el grupo de discos lineales, y
debe tener un rendimiento igual o mejor.
○ Para un repuesto global, es mejor elegir un disco que sea igual o más grande que el disco más
grande de su tipo en el sistema, y que tenga el mismo o mejor rendimiento. Si el sistema tiene
una combinación de tipos de discos (SSD, enterprise SAS o midline SAS), debería haber al menos
un repuesto global de cada tipo (a menos que los repuestos dedicados se utilicen para proteger
cada grupo de discos de un tipo determinado, lo que solo corresponde a una configuración de
almacenamiento lineal).
485
Aviso El grupo de discos indicado se puso en cuarentena para evitar la escritura de datos no válidos en la
controladora que registró este evento.
Este evento se registra para informar que el grupo de discos indicado pasó al estado de cuarentena
offline (QTOF) para evitar la pérdida de datos. La controladora que registró este evento detectó
(mediante la información guardada en los metadatos del grupo de discos) que podría contener datos
desactualizados que no se deberían escribir en el grupo de discos. Podría perder datos si no sigue las
acciones recomendadas con atención. Esta situación suele suceder cuando se quita un módulo de
controladora sin apagarlo primero y se inserta un módulo de controladora diferente en su lugar. Para
evitar este problema en el futuro, apague siempre la controladora de almacenamiento en un módulo de
controladora antes de quitarla. Esta situación también puede ocurrir por una falla de la tarjeta
CompactFlash, como lo indica el evento 204.
Acciones recomendadas:
● Si se registra el evento 204, siga las acciones recomendadas para el evento 204.
● Si NO se registra el evento 204, realice las siguientes acciones recomendadas:
○ Si el evento 486 no se registra aproximadamente al mismo tiempo que el evento 485, vuelva a
insertar el módulo de controladora quitado, apáguelo y vuelva a quitarlo.
○ Si se registran los eventos 485 y 486 aproximadamente al mismo tiempo, espere al menos
5 minutos a que se complete el proceso de recuperación automática. Luego, inicie sesión y
confirme que funcionen ambos módulos de controladora (puede determinar si las controladoras
Eventos y mensajes de evento 123

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
funcionan mediante el comando para mostrar controladoras de la CLI o la SMC). En la mayoría
de los casos, el sistema volverá a activarse y no será necesario realizar ninguna acción. Si ambos
módulos de controladora no funcionan en 5 minutos, puede haber una pérdida de datos. Si
ambas controladoras no funcionan, siga este proceso de recuperación:
■ Quite el módulo de controladora que registró primero el evento 486.
■ Apague la alimentación del gabinete de controladora, espere unos segundos y vuelva a
encenderla.
■ Espere a que el módulo de controladora se reinicie y vuelva a iniciar sesión.
■ Verifique el estado de los grupos de discos. Si están en cuarentena offline (QTOF), sáquelos
de cuarentena.
■ Vuelva a insertar el módulo de controladora que quitó. Debería reiniciarse correctamente.
486 Aviso Se inició un proceso de recuperación para evitar la escritura de datos no válidos en la controladora que
registró este evento.
La controladora que registró este evento detectó (mediante la información guardada en los metadatos
del grupo de discos) que podría contener datos desactualizados que no se deberían escribir en el grupo
de discos. La controladora registrará este evento, reiniciará la controladora asociada, esperará
10 segundos y se desactivará. La controladora asociada volverá a activar esta controladora y duplicará
los datos de caché correctos en ella. En la mayoría de los casos, este procedimiento permitirá que se
escriban todos los datos correctamente sin pérdida de datos y sin escribir datos desactualizados.
Acciones recomendadas:
● Espere al menos 5 minutos para que se complete el proceso de recuperación automática. A
continuación, inicie sesión y confirme que ambos módulos de controladora funcionen (puede
determinar si las controladoras funcionan mediante el comando de la CLI show redundancy-
mode). En la mayoría de los casos, el sistema volverá a activarse y no será necesario realizar ninguna
acción.
● Si ambos módulos de controladora no funcionan en 5 minutos, consulte las acciones recomendadas
para el evento 485, que se registrará aproximadamente al mismo tiempo.
487 Información Se restablecieron las estadísticas de rendimiento histórico.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
488 Información Se inició la creación de un grupo de volúmenes.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
489 Información Se completó la creación de un grupo de volúmenes.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
490 Información Falló la creación de un grupo de volúmenes.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
491 Información Se inició la creación de un grupo de volúmenes.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
492 Información Se desagruparon los volúmenes de un grupo de volúmenes.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
493 Información Se modificó un grupo de volúmenes.
Acciones recomendadas:
124 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● No es necesario realizar ninguna acción.
494 Información Se completó la reinicialización de un pool de instantáneas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
495 Aviso El algoritmo para mejor ruta de colocación seleccionó la ruta alternativa para el disco indicado, ya que el
conteo de errores de I/O en la ruta principal alcanzó el umbral.
La controladora que registra este evento indica qué canal (ruta) tiene el problema. Por ejemplo, si la
controladora B registra el problema, el problema está en la cadena de cables y los módulos de expansión
conectados al módulo de controladora B.
Acciones recomendadas:
● Si este evento ser registra consistentemente para solo un disco en un gabinete, realice las siguientes
acciones:
○ Reemplace el disco.
○ Si esto no resuelve el problema, la falla probablemente está en el midplane del gabinete.
Reemplace la FRU del chasis para el gabinete indicado.
● Si este evento se registra para más de un disco en un gabinete o discos en varios gabinetes, realice
las siguientes acciones:
○ Verifique si hay cables de SAS desconectados en la ruta fallida. Si no hay cables desconectados,
reemplace el cable que conecta al puerto de ingreso en el gabinete más ascendente con fallas
informadas. Si esto no resuelve el problema, reemplace otros cables en la ruta fallida, uno a la
vez, hasta que se resuelva.
○ Si el problema no se resuelve, reemplace los módulos de expansión en la ruta fallida. Comience
con el módulo más ascendente en un gabinete con fallas informadas. Si esto no resuelve el
problema, reemplace otros módulos de expansión (y el módulo de controladora) en dirección
ascendente del gabinete afectado, uno a la vez, hasta que se resuelva.
○
Si el problema no se resuelve, la falla probablemente está en el midplane del gabinete. Reemplace
la FRU del chasis del gabinete más ascendente con fallas informadas. Si esto no resuelve el
problema y hay más de un gabinete con fallas informadas, reemplace la FRU del chasis de los
otros gabinetes con gallas informadas hasta que se resuelva el problema.
496
Aviso Se encontró un tipo de disco no compatible.
Acciones recomendadas:
● Reemplace el disco con un tipo compatible.
Aviso Se encontró un proveedor de disco no compatible.
Acciones recomendadas:
● Reemplace el disco con uno compatible por su proveedor de sistema.
497 Información Se inició una operación de escritura diferida del disco. El disco indicado es el disco de origen.
Cuando un disco falla, la reconstrucción se realiza mediante un disco de repuesto. Cuando se reemplaza
el disco fallido, los datos que se reconstruyeron en el disco de repuesto (y los datos nuevos que se
escribieron en él) se copian en el disco en la ranura donde los datos se encontraban originalmente. Esto
se conoce como afinidad de ranuras.
Para la operación de escritura diferida, el disco reconstruido se denomina disco de origen y el disco
recién reemplazado se denomina disco de destino. Todos los datos se copian del disco de origen al disco
de destino y el disco de origen vuelve a ser un disco de repuesto.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
498 Información Se completó una operación de escritura diferida del disco.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Eventos y mensajes de evento 125

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Aviso Falló una operación de escritura diferida del disco.
Cuando un disco falla, la reconstrucción se realiza mediante un disco de repuesto. Cuando se reemplaza
el disco fallido, los datos que se reconstruyeron en el disco de repuesto (y los datos nuevos que se
escribieron en él) se copian en el disco en la ranura donde los datos se encontraban originalmente. Esto
se conoce como afinidad de ranuras.
Sin embargo, esta operación de escritura diferida falló. Esto puede ocurrir debido a que el disco que se
insertó como reemplazo del disco fallido también presenta fallas o porque el disco de origen para la
escritura diferida tiene una falla. Esta falla también puede deberse a una falla en el midplane del gabinete
en que los discos están insertados.
Acciones recomendadas:
● Busque otro evento registrado aproximadamente al mismo tiempo que indique una falla de disco,
como el evento 8 , 55, 58 o 412. Siga las acciones recomendadas para ese evento. Si el problema
vuelve a ocurrir para la misma ranura, reemplace la FRU del chasis.
499 Información Se inició una operación de escritura diferida del disco. El disco indicado es el disco de destino.
Cuando un disco falla, la reconstrucción se realiza mediante un disco de repuesto. Cuando se reemplaza
el disco fallido, los datos que se reconstruyeron en el disco de repuesto (y los datos nuevos que se
escribieron en él) se copian en el disco en la ranura donde los datos se encontraban originalmente. Esto
se conoce como afinidad de ranuras.
Para la operación de escritura diferida, el disco reconstruido se denomina disco de origen y el disco
recién reemplazado se denomina disco de destino. Todos los datos se copian del disco de origen al disco
de destino y el disco de origen vuelve a ser un disco de repuesto.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
500 Información Se completó una operación de escritura diferida del disco. El disco indicado se restauró nuevamente a
repuesto.
Cuando un disco falla, la reconstrucción se realiza mediante un disco de repuesto. Cuando se reemplaza
el disco fallido, los datos que se reconstruyeron en el disco de repuesto (y los datos nuevos que se
escribieron en él) se copian en el disco en la ranura donde los datos se encontraban originalmente. Esto
se conoce como afinidad de ranuras.
Para la operación de escritura diferida, el disco reconstruido se denomina disco de origen y el disco
recién reemplazado se denomina disco de destino. Todos los datos se copian del disco de origen al disco
de destino y el disco de origen vuelve a ser un disco de repuesto.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
501 Error El hardware del gabinete no es compatible con el firmware del módulo de I/O.
El firmware de la controladora del expansor detectó una incompatibilidad con el tipo de midplane. Como
medida de prevención, se deshabilitó el acceso al disco en el gabinete.
Acciones recomendadas:
● Si utiliza un gabinete compatible, actualice el sistema de almacenamiento al firmware más reciente.
Si utiliza un gabinete no compatible, reemplace el gabinete no compatible por uno compatible.
502 Aviso La SSD indicada tiene 5 % o menos de vida útil restante.
Este evento se registrará nuevamente cuando el dispositivo se acerque y alcance el final de su vida útil.
Acciones recomendadas:
● Asegúrese de tener una SSD de repuesto del mismo tipo y capacidad disponible.
● Si hay un repuesto disponible, reemplace la SSD en este momento.
Información La SSD indicada tiene 20 % o menos de vida útil restante.
Este evento se volverá a registrar con gravedad de Advertencia a medida que la SSD se aproxime al final
de su vida útil.
126 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● Adquiera una SSD de repuesto del mismo tipo y capacidad si aún no tiene una disponible.
503 Información El monitor de errores de back-end inteligente (IBEEM) descubrió que se informaron errores continuos
para la PHY indicada.
IBEEM registró este evento tras supervisar la PHY durante 30 minutos.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
504 Información Un usuario habilitó o deshabilitó el acceso de depuración de servicio al sistema. Permitir el acceso de
depuración de servicio puede tener consecuencias de seguridad. Después de completar el diagnóstico,
quizá desee deshabilitar ese acceso.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
505 Aviso Se creó el pool virtual indicado con un tamaño menor a 500 GB, lo que puede causar un
comportamiento impredecible.
El sistema de almacenamiento puede no funcionar correctamente.
Acciones recomendadas:
● Agregue grupos de discos al pool virtual para aumentar el tamaño del pool.
506 Información Se inició el agregado del grupo de discos indicado.
Cuando se completa esta operación, se registra el evento 467.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
507 Información La velocidad de vínculo del disco indicado no coincide con la velocidad de vínculo de la que es capaz el
gabinete.
Este evento se registra cuando la velocidad de vínculo negociada automáticamente es menor a la
velocidad máxima compatible con el gabinete. El disco funciona, pero se reduce el rendimiento de I/O.
Este evento se puede registrar para uno o ambos canales de disco.
Acciones recomendadas:
● Si el disco es miembro de un grupo de discos sin tolerancia a fallas (RAID 0 o no RAID), pase los
datos a un grupo diferente.
● Reemplace el disco por uno del mismo tipo (SSD, enterprise SAS o midline SAS) y de la misma o
mayor capacidad. Para un rendimiento de I/O óptimo continuo, el disco de repuesto debe tener un
rendimiento igual o mejor que el que está reemplazando.
508 Error Se desconectó el pool virtual indicado. También se desconectaron todos sus volúmenes.
Se perdieron todos los datos en el pool virtual. Esta condición puede ocurrir a causa de metadatos de
pool virtual inaccesibles o corruptos.
Acciones recomendadas:
● Verifique si hay otros eventos que indican fallas en el sistema y siga las acciones recomendadas para
esos eventos.
● Vuelva a crear el pool virtual.
● Restaure los datos desde una copia de respaldo, si está disponible.
509 Error Se desconectó el volumen de metadatos para el pool virtual indicado. Las asignaciones de volumen y las
reservas persistentes se perdieron o no son accesibles.
Acciones recomendadas:
● Verifique si hay otros eventos que indican fallas en el sistema y siga las acciones recomendadas para
esos eventos.
Eventos y mensajes de evento 127

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Cree nuevas asignaciones para los volúmenes. Los sistemas host restaurarán las reservas
persistentes automáticamente.
510 Información Un usuario cambió o estableció la tecla de bloqueo de FDE.
Acciones recomendadas:
● Asegúrese de registrar la frase de contraseña de la tecla de bloqueo y la nueva ID de bloqueo.
511 Información Un usuario estableció la tecla de bloqueo de importación de FDE.
Por lo general, esto se utiliza para importar un disco FDE bloqueado por otro sistema a este sistema.
Acciones recomendadas:
● Asegúrese de que los discos importados estén integrados en el sistema.
512 Información Un usuario estableció el sistema al estado seguro de FDE.
El cifrado de disco total se encuentra habilitado. Los discos quitados de este sistema no se podrán leer a
menos que se importen a otro sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
513 Información Un usuario estableció el sistema al estado de readaptación de FDE.
Todos los discos se readaptaron y se establecieron a sus estados de fábrica iniciales. FDE ya no está
habilitado en el sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
514 Información Un usuario borró la tecla de importación y la tecla de bloqueo de FDE.
Las operaciones de I/O pueden continuar siempre y cuando no se reinicie el sistema.
Acciones recomendadas:
● Si el sistema se reinicia y se planea acceder a los datos, se debe reinstaurar la tecla de bloqueo.
515 Información Un usuario readaptó un disco de FDE.
El disco se restableció al estado original de fábrica.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
516 Error Un disco de FDE se pasó a estado no disponible.
El mensaje de evento relacionado 518, que indica que falló una operación de disco, puede proporcionar
información adicional.
Acciones recomendadas:
● Consulte la acción recomendada especificada en el mensaje de evento.
517 Información Un disco que solía estar en el estado no disponible de FDE ahora está disponible.
El disco volvió al funcionamiento normal.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
518 Error Falló una operación de disco de FDE.
Este evento proporciona detalles sobre la operación fallida.
Acciones recomendadas:
● Es posible que se deba quitar, reimportar, readaptar o reemplazar el disco.
519 Error El sistema cambió a un estado degradado de cifrado de disco completo.
128 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Por lo general, se produjo una condición relacionada con el disco.
Acciones recomendadas:
● Es posible que deba quitar, importar, readaptar o reemplazar uno o más discos.
520 Información El sistema que estaba en estado degradado de cifrado de disco completo ya no está degradado.
El sistema volvió al funcionamiento normal.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
521 Error Se produjo un error al acceder al SEEPROM del midplane para almacenar o recuperar las claves de
cifrado de disco total.
La memoria del midplane se utiliza para almacenar la tecla de bloqueo de FDE.
Acciones recomendadas:
● Es posible que se deba reemplazar el midplane si el error persiste.
522 Aviso Hubo un error de un trabajo de limpieza de grupo de discos en la dirección de bloque lógico indicada.
El mensaje de evento siempre incluye el nombre del grupo de disco y la dirección de bloque lógico del
error dentro del grupo de discos. Si el bloque con un error falla dentro del rango de LBA que usa un
volumen, el mensaje de evento también incluye el nombre del volumen y el LBA dentro de ese volumen.
Acciones recomendadas:
● Examine el evento 207 que se registró antes que este evento. Siga las acciones recomendadas para
ese evento.
523 Información Este evento proporciona detalles adicionales asociados con un trabajo de limpieza de grupo de discos,
expandiendo la información del evento 206 , 207 o 522.
Acciones recomendadas:
● Siga las acciones recomendadas para el evento asociado.
524 Error Un sensor de voltaje o temperatura alcanzó un umbral crítico.
Un sensor supervisó una temperatura o voltaje en el rango crítico. Cuando se resuelve el problema, se
registra el evento 47 para el componente que registró el evento 524.
Si el evento se refiere a un sensor de disco, el comportamiento del disco podría ser impredecible en este
rango de temperatura.
Compruebe el registro de eventos para determinar si más de un disco informó este evento.
● Si varios discos informaron esta condición, podría haber un problema en el ambiente.
● Si un disco informa esta condición, podría haber un problema en el ambiente o una falla en el disco.
Acciones recomendadas:
● Verifique que funcionen los ventiladores del sistema de almacenamiento.
● Verifique que la temperatura ambiente no sea demasiado alta. El rango de funcionamiento del
gabinete de la controladora es de 5 °C a 35 °C (41 °F a 95 °F). El rango de funcionamiento del
gabinete de expansión es de 5 °C a 40 °C (41 °F a 104 °F).
● Verifique que no haya obstrucciones en el flujo de aire.
● Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
● Si ninguna de las acciones recomendadas resuelve el problema, reemplace el disco o el módulo de
controladora que registró el error.
525 Información Un usuario detuvo un cajón.
El cajón se apagó y se puede quitar de manera segura. Se debe volver a explorar antes de que la
información del cajón actualizada esté disponible.
Acciones recomendadas:
● Reinicie el cajón mediante el comando start drawer o quítelo para reemplazarlo.
Eventos y mensajes de evento 129

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
526 Información Un usuario inició un cajón.
Se inició el cajón. Los discos del cajón pueden demorar unos minutos en activarse. Se debe realizar una
nueva exploración antes de que la información del cajón actualizada esté disponible.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
527 Error El firmware de la controladora del expansor (EC) no es compatible con el gabinete.
Como medida de prevención, la controladora del expansor (EC) deshabilitó todas las PHY e informó la
página de estado de gabinete corto en la lista de diagnóstico compatible.
Acciones recomendadas:
● Actualice el módulo de controladora a la versión de paquete compatible más reciente.
528 Error El firmware de la controladora del expansor detectó que la controladora del expansor (EC) asociada no
es compatible con el gabinete.
Como medida de prevención, la controladora del expansor (EC) deshabilitó todas las PHY e informó la
página de estado de gabinete corto en la lista de diagnóstico compatible.
Acciones recomendadas:
● Actualice el módulo de controladora asociado a la versión de paquete compatible más reciente.
529 Error La controladora del expansor (EC) local no es compatible con el gabinete.
Como medida de prevención, la controladora del expansor (EC) deshabilitó todas las PHY e informó la
página de estado de gabinete corto en la lista de diagnóstico compatible.
Acciones recomendadas:
● Reemplace el módulo de controladora con uno compatible con el gabinete.
530 Error El firmware de la controladora del expansor (EC) detectó un nivel de incompatibilidad con la
controladora del expansor (EC) asociada. Esta incompatibilidad podría ser causada por un firmware o
hardware no compatible.
Como medida preventiva, la controladora del expansor (EC) local mantiene la controladora del expansor
(EC) asociada en un loop de restablecimiento.
Acciones recomendadas:
● Quite el módulo de controladora asociado del gabinete. Inicie el módulo de controladora asociado en
modo de controladora única en un gabinete independiente (sin el módulo de controladora que
informó este evento). Cargue la versión de paquete compatible más reciente. Si la versión no carga,
reemplace el módulo de controladora asociado.
531 Error El módulo de controladora indicado no se pudo recuperar de una detención. El sistema se deberá
recuperar manualmente.
Acciones recomendadas:
● Descargue los registros de depuración del sistema de almacenamiento y comuníquese con el soporte
técnico. Un técnico de servicio puede usar los registros de depuración para determinar el problema.
Aviso El módulo de controladora indicado detectó una detención. El sistema realizará acciones correctivas.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
532 Aviso El módulo de la controladora asociada se apagó debido a un error de información de protección durante
una operación de escritura en el disco.
Si los reintentos se realizan correctamente después de la conmutación por error, la controladora se
considerará fallida. De lo contrario, es probable que el disco sea la causa de la falla.
Acciones recomendadas:
130 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Reemplace la controladora apagada si el reintento se realiza correctamente después de la
conmutación por error. De lo contrario (si se encuentran errores de disco), reemplace el disco y
vuelva a poner la controladora en funcionamiento.
533 Error Este evento proporciona detalles sobre el resultado de la prueba de MC del componente indicado.
Si la prueba se realizó correctamente, el mensaje indica que el componente está presente y funciona. Si
la prueba falló, el mensaje dice que el componente no está disponible.
Acciones recomendadas:
● Si el evento indica que falló la prueba, reemplace el módulo de controladora que registró este evento.
Información Este evento proporciona detalles sobre el resultado de la prueba de MC del componente indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
534 Información El sistema determinó que el disco indicado está degradado porque experimentó una cantidad de errores
de disco superior al umbral configurado.
El disco indicado experimentó un número de errores de disco que superó el umbral configurado. Debido
a que el disco es parte de un grupo de discos que no tiene tolerancia a errores, el sistema ha establecido
el estado del disco como degradado en lugar de fallido.
Acciones recomendadas:
● Supervise el disco.
Aviso El sistema determinó que el disco indicado está degradado porque experimentó una cantidad de errores
de disco superior al umbral configurado.
El disco indicado experimentó un número de errores de disco que superó el umbral configurado. Debido
a que el disco es parte de un grupo de discos que no tiene tolerancia a errores, el sistema ha establecido
el estado del disco como degradado en lugar de fallido.
Acciones recomendadas:
● Supervise el disco.
535 Aviso Un disco se puso en estado FALLIDO después de que la controladora detectó un error de información de
protección.
Acciones recomendadas:
● Reemplace el disco fallido y ponga la otra controladora en funcionamiento nuevamente.
536 Información La controladora detectó un error de información de protección de disco, pero los reintentos se realizaron
correctamente. No era necesaria ninguna otra acción de recuperación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
537 Aviso Un disco se puso en estado FALLIDO después de que el disco informó un error de información de
protección.
Acciones recomendadas:
● Reemplace el disco fallido.
538 Información El disco informó un error de información de protección, pero los reintentos se realizaron correctamente.
No era necesaria ninguna otra acción de recuperación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
539 Información Para el grupo de discos indicado, que se dañó, el paso "recrear" de la recuperación del grupo no se
completó correctamente o el paso "recrear" de la recuperación del grupo de discos se realizó
correctamente.
Acciones recomendadas:
Eventos y mensajes de evento 131

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Verifique que los volúmenes esperados se hayan recuperado.
● Si los volúmenes esperados no se recuperaron, se puede usar el comando "recover volume".
● Después de verificar la recuperación del volumen, complete la recuperación del grupo de discos
mediante el comando 'recover disk-group complete'.
540 Información El volumen indicado, que se dañó, se ha recuperado.
Acciones recomendadas:
● Después de verificar la recuperación del volumen, complete la recuperación del grupo de discos
mediante el comando 'recover disk-group complete'.
541 Información Para el grupo de discos indicado, que se dañó, el paso 'completar' de la recuperación del grupo de discos
se realizó correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
542 Crítico La controladora cercó un bloque de datos debido a los datos perdidos.
El evento 543 también se registrará para describir la información de volumen para el bloque de datos
cercado.
Acciones recomendadas:
● Realice procedimientos de recuperación, que pueden incluir la restauración a partir de respaldos.
543 Crítico La controladora cercó un bloque de datos en un volumen debido a la pérdida de datos.
Este evento describe información de volumen para un bloque de datos cercado. Se registra junto al
evento 542, que describe información de disco y grupo de discos para el bloque de datos.
Acciones recomendadas:
● Realice procedimientos de recuperación, que pueden incluir la restauración a partir de respaldos.
544 Información Una operación de limpieza del grupo de discos superó su objetivo de duración en un 20 %.
El sistema intentará ajustar los recursos del sistema para cumplir con los objetivos de la duración de
limpieza, pero factores como la cantidad de datos o la actividad anormalmente alta del host pueden
hacer que las operaciones de limpieza superen la duración solicitada.
Acciones recomendadas:
● Si este evento se produce reiteradamente, se debe aumentar el objetivo de duración de limpieza
para aumentar la probabilidad de alcanzar el objetivo.
545 Aviso Hay un módulo de controladora conectado a un midplane de gabinete heredado, lo que resulta en un
rendimiento degradado.
Acciones recomendadas:
● Para lograr un mejor rendimiento, reemplace la FRU del chasis heredado del gabinete con la última
versión de la FRU.
546 Error La controladora que registró este evento desactivó la controladora asociada, que tiene una
configuración de puerto de host incompatible.
Acciones recomendadas:
● Reemplace el módulo de controladora desactivado con un módulo de controladora que tenga la
misma configuración de puerto de host que el módulo de controladora que se mantuvo activado.
547 Aviso El sistema determinó que el disco indicado está degradado porque experimentó una cantidad de errores
de disco superior al umbral configurado. El sistema causó que el disco falle, según lo especificado por la
política configurada.
Acciones recomendadas:
● Reemplace el disco fallido.
548 Aviso Falló la reconstrucción del grupo de discos.
132 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Cuando un disco falla, se realiza la reconstrucción mediante un disco de repuesto. En este caso, la
operación de reconstrucción falló porque hay datos que no se pueden leer (errores de medios
incorregibles) en al menos otro disco del grupo de discos. A causa de ello, no se puede reconstruir una
porción de los datos.
Acciones recomendadas:
● Si no tiene una copia de respaldo de los datos en el grupo de discos, realice una copia de respaldo.
● Tenga en cuenta la configuración del grupo de discos, como su tamaño y las asignaciones de host.
● Busque otro evento registrado aproximadamente al mismo tiempo que indique una falla de disco,
como el evento 8 , 55, 58 o 412. Siga las acciones recomendadas para ese evento.
● Quite el grupo de discos.
● Vuelva a agregar el grupo de discos.
● Restaure los datos a partir del respaldo a un nuevo grupo de discos.
549 Crítico El módulo de controladora indicado detectó una recuperación de una falla de procesador interno.
Acciones recomendadas:
● Reemplace el módulo de controladora.
550 Crítico Se detectó que la ruta de datos de lectura entre la controladora de almacenamiento y las unidades de
disco no es confiable. La controladora de almacenamiento tomó medidas para corregir esto.
Acciones recomendadas:
● Reemplace la controladora.
551 Error Un EMP notificó una de las siguientes opciones para una fuente de alimentación (PSU):
● La PSU no se puede comunicar con el EMP.
● La PSU de un gabinete no tiene alimentación o tiene una falla de hardware.
● La PSU está funcionando con firmware corrupto.
Acciones recomendadas:
● El EMP no se puede comunicar con la PSU indicada:
○ Espere al menos 10 minutos y verifique si se soluciona el error.
○ Si el error persiste, verifique que todos los módulos del gabinete estén completamente asentados
en sus ranuras y que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, anote la PSU. Asegúrese de que la PSU asociada no esté
degradada. Si lo está, comuníquese con el soporte técnico.
○ Si la PSU asociada no está degradada, quite la PSU indicada y vuelva a insertarla.
○ Si esto no resuelve el problema, la FRU indicada probablemente falló y deberá reemplazarla.
● Si una de las PSU en un gabinete no tiene alimentación o tiene una falla de hardware:
○ Verifique que la PSU indicada esté completamente asentada en su ranura y que los pestillos de la
PSU, si los hay, estén bloqueados.
○ Verifique que todas las PSU tengan el interruptor encendido (si tienen un interruptor).
○ Verifique que cada cable de alimentación esté firmemente enchufado a la PSU y a una toma de
corriente que funcione.
○ Si ninguna de las acciones recomendadas soluciona el problema, la PSU indicada probablemente
falló y deberá reemplazarla.
●
Si una PSU funciona con firmware corrupto:
○ La PSU indicada falló y deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso
Un EMP informó que se desinstaló la fuente de alimentación (PSU).
Acciones recomendadas:
● Verifique que la PSU indicada esté en el gabinete indicado.
● Si la PSU no está en el gabinete, instale una PSU de inmediato.
● Si la PSU está en el gabinete, asegúrese de que la fuente de alimentación esté completamente
asentada en la ranura y de que el pestillo esté bloqueado.
Eventos y mensajes de evento 133

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Si ninguna de las acciones recomendadas soluciona el problema, la FRU indicada falló y deberá
reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Una alerta de SES para una fuente de alimentación en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
552 Error Un EMP informó una condición de alerta.
● Se detectó una falla de hardware y fallaron todos los ventiladores de la FRU indicada.
● El ventilador no se puede comunicar con el EMP.
Acciones recomendadas:
● Si se detectó una falla de hardware y fallaron todos los ventiladores de la FRU indicada;
○ Inspeccione la información de estado del sistema para determinar qué FRU contiene los
ventiladores afectados. El evento 551 o el 558 deberían proporcionar más información sobre las
FRU contenedoras.
○ Reemplace las FRU contenedoras.
● Si el ventilador no se puede comunicar con el EMP;
○ Espere al menos 10 minutos y verifique si se soluciona el error.
○ Si el error persiste, verifique que todos los módulos del gabinete estén completamente asentados
en sus ranuras y que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, anote la FRU. Asegúrese de que la FRU asociada no esté
degradada. Si lo está, comuníquese con el soporte técnico.
○ Si la FRU asociada no está degradada, quite la FRU indicada y vuelva a insertarla.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Un EMP informó una de las siguientes opciones:
● Se desinstaló un ventilador en la FRU indicada.
● Falló un ventilador en la FRU indicada y se perdió la redundancia de ventiladores para la FRU.
Acciones recomendadas:
● Si se desinstaló un ventilador en la FRU indicada:
○ Verifique que la FRU indicada esté en el gabinete indicado.
○ Si la FRU no está en el gabinete, instale una FRU adecuada de inmediato.
○ Si la FRU está en el gabinete, asegúrese de que la FRU esté completamente asentada en la
ranura y de que el pestillo esté bloqueado.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada falló y deberá
reemplazarla.
● Si falló un ventilador en la FRU indicada y se perdió la redundancia de ventiladores para la FRU:
○ La FRU indicada falló y deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Una alerta de SES para un ventilador en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
553 Error Un sensor de temperatura informó una condición de alerta.
● Un sensor de temperatura está fuera del umbral de temperatura crítica en la FRU indicada.
● El sensor de temperatura no se puede comunicar con el EMP.
Acciones recomendadas:
● Si la temperatura del sensor está fuera del umbral de temperatura crítico en la FRU indicada;
○ Verifique que la temperatura ambiente no sea demasiado alta. Para el rango de funcionamiento
normal, consulte la Guía de mantenimiento e instalación de hardware del producto.
134 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
○ Verifique que no haya obstrucciones en el flujo de aire.
○ Verifique que todos los módulos del gabinete estén completamente asentados en sus ranuras y
que sus pestillos, si los hay, estén bloqueados.
○ Verifique que funcionen todos los ventiladores del gabinete.
○ Verifique que haya una placa de relleno o módulo en cada ranura de módulo del gabinete.
○ Si ninguna de las acciones recomendadas soluciona el problema, la FRU indicada probablemente
falló y deberá reemplazarla.
● El sensor de temperatura no se puede comunicar con el EMP.
○ Espere al menos 10 minutos y verifique si se soluciona el error.
○ Si el error persiste, verifique que todos los módulos del gabinete estén completamente asentados
en sus ranuras y que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, anote la FRU. Asegúrese de que la FRU asociada no esté
degradada. Si lo está, comuníquese con el soporte técnico.
○ Para todos los tipos de FRU, excepto el gabinete, si la FRU asociada no está degradada, quite y
vuelva a insertar la FRU indicada.
○ Si la FRU indicada está en el gabinete, configure una ventana de mantenimiento preventiva y
realice un ciclo de apagado y encendido en el gabinete en ese momento.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Un sensor de temperatura no se encuentra dentro de los umbrales de temperatura de funcionamiento
normal pero está dentro de los límites de funcionamiento seguros; o se desinstaló un sensor de
temperatura.
Acciones recomendadas:
● Si un sensor de temperatura superó el rango de funcionamiento normal pero está dentro de los
límites de funcionamiento seguros;
○ Verifique que la temperatura ambiente no sea demasiado alta. Para el rango de funcionamiento
normal, consulte la Guía de mantenimiento e instalación de hardware del producto.
○ Verifique que no haya obstrucciones en el flujo de aire.
● Si se desinstaló un sensor de temperatura:
○ Verifique que la FRU indicada esté en el gabinete indicado.
● Si la FRU no está en el gabinete, instale la FRU inmediatamente.
● Si la FRU está en el gabinete, asegúrese de que la FRU esté completamente asentada en la ranura y
de que los pestillos, si los hay, estén bloqueados.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Se resolvió una alerta de SES de un sensor de temperatura en el gabinete indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
554 Error Un sensor de voltaje informó una condición de alerta.
● Un sensor de voltaje está fuera del umbral de voltaje crítico en la FRU indicada.
● Un sensor de voltaje no se puede comunicar con el EMP.
Acciones recomendadas:
● Si un sensor de voltaje está fuera del umbral de voltaje crítico en la FRU indicada:
○ Verifique que todos los módulos del gabinete estén completamente asentados en sus ranuras y
que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, la FRU indicada probablemente falló y deberá reemplazarla.
● Si el sensor de voltaje no se puede comunicar con el EMP:
○ Espere al menos 10 minutos y verifique si se soluciona el error.
○ Si el error persiste, verifique que todos los módulos del gabinete estén completamente asentados
en sus ranuras y que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, asegúrese de que la FRU asociada no esté degradada. Si lo está,
comuníquese con el soporte técnico.
Eventos y mensajes de evento 135

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
○ Para todos los tipos de FRU, excepto el gabinete, si la FRU asociada no está degradada, quite y
vuelva a insertar la FRU indicada.
○ Si la FRU indicada está en el gabinete, configure una ventana de mantenimiento preventiva y
realice un ciclo de apagado y encendido en el gabinete en ese momento.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Un sensor de voltaje no se encuentra dentro del rango de funcionamiento normal pero está dentro de los
límites de funcionamiento seguros o se quitó un sensor de voltaje.
Acciones recomendadas:
● Si un sensor de voltaje superó el rango de funcionamiento normal pero está dentro de los límites de
funcionamiento seguros:
○ Verifique que todos los módulos del gabinete estén completamente asentados en sus ranuras y
de que sus pestillos estén bloqueados.
○ Si esto no resuelve el problema, la FRU indicada probablemente falló y deberá reemplazarla.
● Si se quitó un sensor de voltaje:
○ Verifique que la FRU indicada esté en el gabinete indicado.
○ Si la FRU no está en el gabinete, instale la FRU inmediatamente.
○ Si la FRU está en el gabinete, asegúrese de que la FRU esté completamente asentada en la
ranura y de que los pestillos estén bloqueados.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Se resolvió una alerta de SES de un sensor de voltaje en el gabinete indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
555 Error El firmware de la controladora del expansor local detectó un nivel de una incompatibilidad con el
firmware o hardware de la controladora del expansor asociada. Como medida preventiva, la controladora
del expansor local puede deshabilitar todas las PHY.
Acciones recomendadas:
● Verifique que ambas controladoras del expansor tengan la revisión de firmware correcta.
● Si ambas controladoras del expansor tienen versiones de firmware diferentes, actualice el módulo de
controladora asociado al firmware adecuado compatible con el gabinete.
● Si estas acciones recomendadas no resuelven el problema, reemplace el módulo de controladora
asociado.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Un expansor en un módulo de controladora, módulo de expansión o cajón está emparejado pero no
responde; o se quitó un expansor en un módulo de expansión.
Acciones recomendadas:
● Verifique que la FRU indicada esté en el gabinete indicado.
● Si la FRU no está en el gabinete, instale una FRU adecuada de inmediato.
● Si la FRU está en el gabinete, asegúrese de que la FRU esté completamente asentada en la ranura y
de que los pestillos, si los hay, estén bloqueados.
● Si estas acciones recomendadas no resuelven el problema, la FRU indicada falló y deberá
reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Una alerta de SES para un expansor en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
136 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
556 Error Se detectó una condición de alerta en un elemento expansor de cajón o expansor de raíz.
Acciones recomendadas:
● Reemplace el módulo que contiene el expansor indicado. Esto puede ser un IOM, un sideplane o un
cajón. Comuníquese con el soporte técnico para reemplazar el módulo que contiene el expansor de
cajón.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en
caliente y no los puede reparar el cliente.
● Si estas acciones recomendadas no resuelven el problema, comuníquese con el soporte técnico.
Deberá reemplazar el gabinete.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Se detectó una condición de alerta en un elemento expansor de cajón o expansor de raíz.
Acciones recomendadas:
● Si se desinstaló, deberá instalar el expansor asociado con el sideplane o cajón. Comuníquese con el
soporte técnico. De lo contrario, reemplace el módulo que contiene el expansor indicado. Puede ser
un sideplane o un cajón. Comuníquese con el soporte técnico para reemplazar el módulo que
contiene el expansor de cajón.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en
caliente y no los puede reparar el cliente.
● Si estas acciones recomendadas no resuelven el problema, comuníquese con el soporte técnico.
Deberá reemplazar el gabinete.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Una alerta de SES para un expansor en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
557 Error Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
corriente.
● El EMP no se puede comunicar con el sensor de corriente indicado.
● El sensor de corriente está fuera de los valores del umbral crítico.
Acciones recomendadas:
● Si el EMP no se puede comunicar con el sensor de corriente indicado:
○ Espere al menos 10 minutos y verifique si se soluciona el error.
○ Si el error persiste, verifique que todos los módulos del gabinete estén completamente asentados
en sus ranuras y que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, asegúrese de que la FRU asociada no esté degradada. Si lo está,
comuníquese con el soporte técnico.
○ Para todos los tipos de FRU, excepto el gabinete, si la FRU asociada no está degradada, quite y
vuelva a insertar la FRU indicada.
○ Si la FRU indicada está en el gabinete, configure una ventana de mantenimiento preventiva y
realice un ciclo de apagado y encendido en el gabinete en ese momento.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
● Si el sensor de corriente está fuera de los valores del umbral crítico:
○ Verifique que todos los módulos del gabinete estén completamente asentados en sus ranuras y
que sus pestillos, si los hay, estén bloqueados.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso
Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
corriente.
● Un sensor de corriente está fuera de los valores del umbral de advertencia definido.
● Se desinstaló un sensor de corriente.
Eventos y mensajes de evento 137

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● Si un sensor de corriente superó los valores del umbral de advertencia definido:
○ Verifique que todos los módulos del gabinete estén completamente asentados en sus ranuras y
que sus pestillos, si los hay, estén bloqueados.
○ Si esto no resuelve el problema, la FRU indicada probablemente falló y deberá reemplazarla.
● Si se desinstaló un sensor de corriente:
○ Verifique que la FRU indicada esté en el gabinete indicado.
○ Si la FRU no está en el gabinete, instale la FRU inmediatamente.
○ Si la FRU está en el gabinete, asegúrese de que la FRU esté completamente asentada en la
ranura y de que los pestillos, si los hay, estén bloqueados.
○ Si estas acciones recomendadas no resuelven el problema, la FRU indicada probablemente falló y
deberá reemplazarla.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Se resolvió una alerta de SES para un sensor de corriente en el gabinete indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
558 Error Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un módulo de
control del ventilador.
Un módulo de ventilador en el gabinete ha fallado.
Acciones recomendadas:
● Reemplace el módulo del ventilador.
Aviso Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un módulo de
control del ventilador.
El circuito de intercambio en caliente en el módulo del ventilador indicado ha fallado. El ventilador seguirá
funcionando. Sin embargo, no es seguro quitar esta FRU mientras el gabinete está encendido.
Acciones recomendadas:
● -Verifique que el módulo de control del ventilador indicado esté en el gabinete indicado.
● Si el módulo de control del ventilador no está en el gabinete, instale una FRU de módulo de control
del ventilador de inmediato.
● Si el módulo de control del ventilador está en el gabinete, asegúrese de que el módulo de control del
ventilador esté completamente asentado en su ranura y que su pestillo esté bloqueado. Si el módulo
de control del ventilador está completamente asentado y los LED necesarios de servicio/falla para el
módulo de control del ventilador y para el gabinete están encendidos, reemplace la FRU del módulo
de control del ventilador inmediatamente. Si eso no resuelve el problema, reemplace la FRU del
chasis de inmediato.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un módulo de
control del ventilador.
Una alerta de SES para un módulo del ventilador en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
559 Error Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
Un sensor de movimiento del cajón ha detectado un nivel excesivo de aceleración o desaceleración.
Acciones recomendadas:
● Para evitar daños físicos en las unidades y componentes de cajón, evite el uso de fuerza excesiva al
quitar o insertar cajones.
138 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Aviso Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
Un sensor de movimiento del cajón ha detectado un nivel excesivo de aceleración o desaceleración.
Acciones recomendadas:
● Para evitar daños físicos en las unidades y componentes de cajón, evite el uso de fuerza excesiva al
quitar o insertar cajones.
Resuelta Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
Se resolvió una alerta de SES de un sensor de movimiento en el gabinete indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
560 Crítico Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
El procesador de administración de gabinetes no se puede comunicar con el dispositivo de
administración del ventilador en el midplane del gabinete. Es probable que se trate de un problema con el
midplane.
Acciones recomendadas:
● Para el gabinete indicado, inspeccione el estado de los módulos de control del ventilador en el estado
del sistema. Si se produce una falla debido al dispositivo de administración de ventiladores, ambos
módulos de control del ventilador también deben informar una falla de comunicación (evento 558
con gravedad de Error). Si las temperaturas del sistema aumentan continuamente, si es posible,
apague el sistema para evitar que se produzcan daños. Reemplace la FRU del chasis
inmediatamente. Si un sensor de temperatura alcanza un valor de apagado, el módulo de la
controladora se apagará automáticamente. Para obtener los valores de apagado, consulte la
información acerca de los sensores de temperatura en la guía de instalación del producto.
● Si puede acceder a la ubicación física del gabinete en un plazo de 10 minutos después de que se
registre este evento, compruebe si los ventiladores están funcionando en el gabinete.
● Si los ventiladores están en funcionamiento, no debe producirse una condición de exceso de
temperatura. Los ventiladores deberían funcionar a su máxima tasa de RPM. Reemplace la FRU del
chasis en un intervalo de servicio especificado.
● Si los ventiladores no funcionan, es probable que se produzca una condición de exceso de
temperatura. Si es posible, apague el sistema ahora para evitar el riesgo de daños. Reemplace la FRU
del chasis inmediatamente.
● Si no puede acceder a la ubicación del gabinete físico en un plazo de 10 minutos después de que se
registre este evento, realice lo siguiente:
○ Monitoree las temperaturas del sistema (sensores de temperatura y discos) de cerca para
garantizar que no se produzca una condición de exceso de temperatura.
● Si las temperaturas del sistema aumentan continuamente, si es posible, apague el sistema para evitar
que se produzcan daños. Reemplace la FRU del chasis inmediatamente. Si un sensor de temperatura
alcanza un valor de apagado, el módulo de la controladora se apagará automáticamente. Para
obtener los valores de apagado, consulte la información acerca de los sensores de temperatura en la
guía de instalación del producto.
Aviso
Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
El dispositivo de administración del ventilador en el gabinete informa un voltaje erróneo en uno o ambos
módulos de control del ventilador.
Acciones recomendadas:
● Inspeccione el estado del dispositivo de administración del ventilador en el estado del sistema. Si
alguno de los módulos de ventilador también informa una falla, reemplácelo.
Resuelta Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un sensor de
movimiento.
Eventos y mensajes de evento 139

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Una alerta de SES para un dispositivo de administración del ventilador en el gabinete indicado se
resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
561 Error Un procesador de administración de gabinetes (EMP) informó una condición de alerta en el LED de la
orejeta del panel frontal.
El EMP no se puede comunicar con el LED de la orejeta del panel frontal.
Acciones recomendadas:
● Reemplace la FRU del midplane y el chasis para el gabinete indicado.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Información Un procesador de administración de gabinetes (EMP) informó una condición de alerta en el LED de la
orejeta del panel frontal.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Resuelta Un procesador de administración de gabinetes (EMP) informó una condición de alerta en el LED de la
orejeta del panel frontal.
Una alerta de SES para un LED de la orejeta del panel frontal en el gabinete indicado se resolvió.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
562 Información Se restablecieron las estadísticas del pool virtual.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
563 Información Se reinició un disco.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
564 Error Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un cajón del
gabinete.
El EMP informó una condición de alerta en un cajón del gabinete:
● La alimentación del cajón es defectuosa.
● Ambos segmentos del cajón están en restablecimiento o no responden.
Acciones recomendadas:
● Póngase en contacto con el el soporte técnico.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Aviso Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un cajón del
gabinete.
El EMP informó una condición de alerta en un cajón del gabinete. Uno de los segmentos del cajón está
en restablecimiento o no responde.
Acciones recomendadas:
● Póngase en contacto con el el soporte técnico.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Un procesador de administración de gabinetes (EMP) informó una condición de alerta en un cajón del
gabinete.
Una alerta de SES para un cajón en el gabinete indicado se resolvió.
140 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Acciones recomendadas:
● No es necesario realizar ninguna acción.
565 Aviso Uno de los buses de PCIe está funcionando a una velocidad menor a la óptima.
Este evento es resultado de un problema de hardware que causó que la controladora funcione más
lentamente de lo esperado. El sistema funciona, pero se degrada el rendimiento de I/O.
Acciones recomendadas:
● Reinicie la controladora que registró el evento. Si el problema persiste, reemplace el módulo de
controladora.
566 Información Uno de los puertos de DDR ha estado ocupado durante al menos 5 minutos.
Este evento es resultado de una compensación de velocidad durante el manejo de bloques de datos
cortos. El sistema funciona, pero se degrada el rendimiento de I/O.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
568 Información Un grupo de discos tiene discos de tamaño de sector físico combinados (por ejemplo, 512n y 512e en el
mismo grupo de discos).
Este evento es resultado de la selección del usuario de discos con formatos de sector que no coinciden
o de un reemplazo de repuesto global con un formato de sector diferente al del grupo de discos. Esto
puede provocar un rendimiento degradado para algunas cargas de trabajo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
569 Aviso Se detectó una incompatibilidad de cable de host de SAS para el puerto. Las PHY alternativas indicadas
se deshabilitaron.
Por ejemplo, un cable de distribución ramificada está conectado a un puerto de host del módulo de
controladora, pero el puerto está configurado para utilizar cables de SAS estándar, o viceversa.
Acciones recomendadas:
● Para utilizar el cable conectado, utilice el comando 'set host-parameters' de la CLI para configurar
los puertos a fin de utilizar el tipo de cable adecuado.
● De lo contrario, reemplace el cable con el tipo de cable que el puerto está configurado para utilizar.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Una discordancia del cable de host de SAS detectado anteriormente se resolvió para el puerto.
Se conectó el tipo de cable adecuado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
571 Error El espacio de instantánea asignada superó el límite de porcentaje configurado del pool virtual.
Si la política de límite de espacio de instantáneas se establece para eliminar instantáneas, el sistema
comenzará a eliminarlas según el ajuste de prioridad de retención de instantánea hasta que el uso de
espacio sea inferior al límite configurado. De lo contrario, el sistema comenzará a utilizar espacio de pool
general para instantáneas hasta que estas se eliminen manualmente. Si el uso de almacenamiento se
reduce a un nivel inferior al de un umbral, se registra el evento 572.
Acciones recomendadas:
● Si la política de límite de espacio de instantáneas está establecida en solo notificar, deberá tomar
medidas inmediatamente para reducir el uso de espacio de instantáneas o agregar capacidad de
almacenamiento.
● Si la política de límite de espacio de instantáneas está establecida en eliminar, el sistema reducirá el
espacio de instantáneas automáticamente o registrará el evento 573 si no se pueden borrar
instantáneas.
Eventos y mensajes de evento 141

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Aviso El espacio de instantánea asignado superó el umbral de espacio de instantáneas superior.
La configuración de umbral superior indica que el pool ya casi no tiene espacio de instantáneas. La
configuración del umbral indica que el pool usa una porción significativa de espacio de instantánea
configurado y se debe supervisar. Si el uso de almacenamiento se reduce a un nivel inferior al de
cualquier umbral, se registra el evento 572.
Acciones recomendadas:
● Elimine instantáneas que ya no sean necesarias para reducir el uso de espacio de instantáneas.
Información El espacio de instantánea asignado superó el umbral de espacio de instantáneas intermedio o inferior.
La configuración del umbral indica que el pool usa una porción significativa de espacio de instantánea
configurado y se debe supervisar. Si el uso de almacenamiento se reduce a un nivel inferior al de
cualquier umbral, se registra el evento 572.
Acciones recomendadas:
● Elimine instantáneas que ya no sean necesarias para reducir el uso de espacio de instantáneas.
572 Información El pool virtual indicado se redujo a un nivel inferior al de uno de los umbrales de espacio de instantáneas.
Este evento indica que ya no corresponde una condición informada por el evento 571.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
573 Aviso El espacio de instantáneas asignado para un pool virtual no se puede reducir, ya que no se puede eliminar
ninguna instantánea.
Las instantáneas asignadas no se pueden eliminar automáticamente si su prioridad de conservación está
establecida en nunca eliminar. Las instantáneas también deben estar en el extremo de hoja de un árbol
de instantáneas para ser eliminables. Este evento se registra cuando ninguna instantánea del pool supera
estas restricciones.
Acciones recomendadas:
● Elimine instantáneas manualmente para reducir el espacio de instantáneas asignado.
574 Información Se creó una conexión entre pares.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
575 Información Se eliminó una conexión entre pares.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
576 Información Se creó un conjunto de replicación o falló la creación de un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
577 Error No se pudo eliminar un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Información Se eliminó un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
578 Error No se pudo iniciar una replicación.
La replicación falló debido a la condición especificada dentro del evento. Las razones para la falla
incluyen, entre otras, el apagado del sistema secundario, una pérdida de comunicación en la conexión
142 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
entre pares (que puede suceder debido a cambios en la configuración de CHAP) o una condición de pool
sin espacio restante.
Acciones recomendadas:
● Resuelva el problema especificado por el mensaje de error incluido en este evento.
Información Se inició una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
579 Aviso Se completó una replicación con fallas.
La replicación falló debido a la condición especificada dentro del evento. Las razones para la falla
incluyen, entre otras, el apagado del sistema secundario, una pérdida de comunicación en la conexión
entre pares (que puede suceder debido a cambios en la configuración de CHAP) o una condición de pool
sin espacio restante.
Acciones recomendadas:
● Resuelva el problema especificado por el mensaje de error incluido en este evento.
Información Se completó una replicación correctamente.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
580 Información Se canceló una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
581 Aviso El sistema suspendió una replicación internamente.
El sistema suspenderá la replicación internamente si detecta una condición de error en el conjunto y las
replicaciones no pueden continuar por alguna razón. Estas incluyen, entre otras, el apagado del sistema
secundario, una pérdida de comunicación en la conexión entre pares (que puede suceder debido a
cambios en la configuración de CHAP) o una condición de pool sin espacio restante.
Acciones recomendadas:
● La replicación se reanudará automáticamente una vez que se resuelva la condición descrita en este
evento.
Información El usuario suspendió una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
582 Información Se puso una replicación en cola detrás de la replicación activa.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
583 Error El conjunto de replicación no se revirtió debido a una falla.
Durante la operación de restauración de conmutación por recuperación, no se invirtió la dirección de
replicación para un conjunto de replicación debido a una falla.
Acciones recomendadas:
● Si se informó un problema con la conexión entre pares, compruebe que los cables de interfaz
adecuados estén conectados a los puertos de host definidos en la conexión entre pares.
● Si los cables correspondientes están conectados, compruebe los cables y los switches de red en
busca de problemas.
● De lo contrario, compruebe la conexión entre pares para una configuración no válida.
Eventos y mensajes de evento 143

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Información Se invirtió la dirección de replicación para un conjunto de replicación. El secundario es ahora el principal.
El principal ahora es el secundario.
Durante la operación de restauración de conmutación por recuperación, se invirtió la dirección de
replicación para un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
584 Información Se modificó una conexión entre pares.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
585 Información Se modificó un conjunto de replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
586 Error La replicación no se pudo reanudar debido a la condición especificada dentro del evento. Las razones
para la falla incluyen, entre otras, el apagado del sistema secundario, una pérdida de comunicación en la
conexión entre pares (que puede suceder debido a cambios en la configuración de CHAP) o una
condición de pool sin espacio restante.
Acciones recomendadas:
● Resuelva el problema especificado por el mensaje de error incluido en este evento.
Información Se reanudó una replicación.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
587 Información Se quitó una replicación pendiente de la cola.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
588 Información Se realizó una conmutación por error de un conjunto de replicación.
Durante la operación de restauración de conmutación por recuperación, se realizó una conmutación por
error de un conjunto de replicación
Acciones recomendadas:
● No es necesario realizar ninguna acción.
589 Información Un conjunto de replicación completó la operación de Conmutación por recuperación sin
restauración o no pudo completar la operación de Conmutación por recuperación sin
restauración .
Acciones recomendadas:
● No es necesario realizar ninguna acción.
590 Error Se puso un grupo de discos en cuarentena.
Esta condición ocurre como resultado de una falla en la restauración/el vaciado de una controladora.
Acciones recomendadas:
● Para restaurar el grupo de discos, use el comando de la CLI dequarantine para quitar el grupo de
discos de cuarentena. Si hay más de un grupo en cuarentena, deberá quitar cada uno por separado,
sean tolerantes a fallas o no. Cuando esto termina, el grupo de discos volverá al estado previo a la
cuarentena. Por ejemplo, si el grupo de discos se estaba reconstruyendo antes de la cuarentena,
reanudará la reconstrucción donde se detuvo.
● Para un grupo de discos lineal, si desea encontrar la paridad incorrecta, use el comando de la CLI
scrub vdisk con el parámetro fix deshabilitado. Este paso es opcional y no es necesario para
reparar problemas de integridad de datos.
144 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Para un grupo de discos tolerante a fallas, ejecute scrub disk-groups para un grupo de discos
virtuales o scrub vdisk con el parámetro fix habilitado para un grupo de discos lineal. Este paso
hará que la paridad sea consistente con los datos de usuario existentes, y es necesario para reparar
problemas de integridad de datos.
● Para un grupo de discos en reconstrucción, permita que termine la reconstrucción y ejecute scrub
disk-groups para un grupo de disco virtual o scrub vdisk con el parámetro fix habilitado
para un grupo de discos lineal. Este paso hará que la paridad sea consistente con los datos de
usuario existentes, y es necesario para reparar problemas de integridad de datos.
● Restaure los datos al grupo de discos desde una copia de respaldo.
591 Error Un módulo de controladora se cercó debido a una falla o un módulo de controladora ya no está cercado.
El módulo de controladora indicada no funciona correctamente y se aisló del sistema. Cuando el
problema se resuelve, un evento con el mismo código se registra con gravedad Informativa.
Acciones recomendadas:
● Reemplace el módulo de controladora que registró este evento.
Resuelta Un módulo de controladora se cercó debido a una falla o un módulo de controladora ya no está cercado.
Se resolvió una falla que causaba que el módulo de controladora indicado se cercara. El módulo de la
controladora volvió al servicio.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
593 Información Un bus de PCIe cambió de velocidad.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
594 Información No se encuentra el disco indicado en el grupo de discos indicado, y el grupo está en cuarentena.
Mientras el grupo de discos se encuentra en cuarentena, en almacenamiento lineal, fallará cualquier
intento de acceder a sus volúmenes desde un host. En almacenamiento virtual, todos los volúmenes del
pool pasarán a ser de solo lectura de manera forzada. Si se puede acceder a todos los discos, el grupo
de discos se quitará de cuarentena automáticamente con un estado resultante de FTOL. Si no se puede
acceder a todos los discos, pero hay suficientes discos accesibles para permitir la lectura y la escritura al
grupo de discos, se quitará de cuarentena automáticamente con un estado resultante de FTDN o CRIT.
Si hay un disco de repuesto disponible, la reconstrucción comenzará automáticamente. Cuando el grupo
de discos se quite de cuarentena, se registra el evento 173. Para una discusión más detallada sobre la
quita de discos de cuarentena, consulte la documentación del PowerVault Manager o de la CLI.
PRECAUCIÓN:
● Evite usar la operación de quita de cuarentena manual como método de recuperación
cuando registra el evento 172, ya que esto provoca que la recuperación de datos sea
más difícil o imposible.
● Si borra los datos de caché no escritos mientras un grupo de discos se encuentra en
cuarentena u offline, los datos se perderán permanentemente.
Acciones recomendadas:
● Si el evento 173 se registró subsecuentemente para el grupo de discos indicado, no es necesario
realizar ninguna acción. Ya se quitó el grupo de discos de cuarentena.
● De lo contrario, realice las siguientes acciones:
○ Verifique que todos los gabinetes estén encendidos.
○ Verifique que todos los discos y módulos de I/O en cada gabinete estén completamente
asentados en sus ranuras y que sus pestillos estén bloqueados.
○ Vuelva a colocar cualquier disco en el disco de cuarentena que se informe como perdido o fallido
en la interfaz de usuario (NO quite y vuelva a colocar discos que no sean miembros del grupo de
discos en cuarentena).
○ Verifique que los cables de expansión de SAS están conectados entre cada gabinete del sistema
de almacenamiento y que estén completamente asentados (NO quite y vuelva a insertar los
cables, ya que esto puede causar problemas con grupos de discos adicionales).
Eventos y mensajes de evento
145

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
○ Verifique que no se hayan quitado discos del sistema sin intención.
○ Verifique si hay otros eventos que indiquen fallas en el sistema y siga las acciones recomendadas
para esos eventos. Pero si el evento indica un disco fallido y la acción recomendada es
reemplazar el disco, NO reemplace el disco en este momento, ya que podría ser necesario más
adelante para la recuperación de datos.
○ Si el grupo de discos sigue en cuarentena después de realizar los pasos anteriores, apague ambas
controladoras y, a continuación, apague todo el sistema de almacenamiento. Vuelva a
encenderlo, comenzando con cualquier gabinete de disco (gabinete de expansión) y, luego, el
gabinete de controladora.
○ Si el grupo de discos sigue en cuarentena después de realizar los pasos anteriores, comuníquese
con el soporte técnico.
595 Información Este evento informa el número de serie de cada módulo de controladora en el sistema.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
596 Aviso La protección contra fallas del gabinete se ha visto afectada para el grupo de discos indicado.
Para reemplazar el disco fallido, el sistema no pudo encontrar un repuesto que cumpliera con los
requisitos para minimizar el riesgo de pérdida de datos en caso de una falla en el gabinete. Por lo tanto,
el sistema debió seleccionar un repuesto que no cumplía con los requisitos. Para un grupo de discos
RAID-6, esto significa que hay más de dos discos miembros en el mismo gabinete. Para otros niveles de
RAID, esto significa que hay más de un disco miembro en el mismo gabinete.
Acciones recomendadas:
● Reemplace el disco fallido indicado en el gabinete indicado para restaurar la protección contra fallas
del gabinete.
597 Aviso La protección contra fallas del cajón se ha visto afectada para el grupo de discos indicado.
Para reemplazar el disco fallido, el sistema no pudo encontrar un repuesto que cumpliera con los
requisitos para minimizar el riesgo de pérdida de datos en caso de una falla en el cajón. Por lo tanto, el
sistema debió seleccionar un repuesto que no cumplía los requisitos. Para un grupo de discos RAID-6,
esto significa que hay más de dos discos miembros en el mismo cajón. Para otros niveles de RAID, esto
significa que hay más de un disco miembro en el mismo cajón.
Acciones recomendadas:
● Reemplace el disco fallido indicado en el gabinete indicado para restaurar la protección contra fallas
del cajón.
598 Advertencia,
Informativa
Falló una medida de rendimiento de la unidad.
Acciones recomendadas:
● Supervise el disco.
599 Error El firmware todavía no recuperó el estado de control de alimentación del gabinete.
El elemento de alimentación del gabinete proporciona un control de alimentación a nivel de gabinete.
Esto puede suceder poco después de un reinicio o la inserción de un módulo. Solo debe tomarse como
un error si dura más de 30 segundos después de un restablecimiento.
Acciones recomendadas:
● Póngase en contacto con el el soporte técnico.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Advertencia,
Resuelta
El firmware todavía no recuperó el estado de control de alimentación del gabinete.
El elemento de alimentación del gabinete proporciona un control de alimentación a nivel de gabinete.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
602 Error,
Advertencia
Se detectó una condición de alerta en un elemento de interconexión de midplane.
146 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
El elemento de interconexión de midplane informa un estado asociado con la interfaz entre el módulo de
I/O de SBB y el midplane. Esto suele ser un tipo de problema de comunicación en la interconexión de
midplane.
Acciones recomendadas:
● Comuníquese con el soporte técnico. Proporcione los registros al personal para que realice el análisis.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Resuelta Se resolvió una condición de Advertencia o Error anterior para el elemento de interconexión de midplane.
El elemento de interconexión de midplane informa un estado asociado con la interfaz entre el módulo de
I/O de SBB y el midplane.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
603 Error,
Advertencia
Se detectó una condición de alerta para un elemento conector de SAS.
El elemento conector de SAS informa sobre el estado de los conectores de puerto SAS interno y
externo.
Acciones recomendadas:
● Póngase en contacto con el el soporte técnico.
● Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Informativa,
Resuelta
Se detectó una condición de alerta para un elemento conector de SAS.
El elemento conector de SAS informa sobre el estado de los conectores de puerto SAS interno y
externo.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
604 Aviso Falló el intento de realizar una instantánea de replicación.
Se configuró un conjunto de replicación para retener instantáneas del volumen. Es posible que haya un
error si la instantánea falla.
Acciones recomendadas:
● Supervise el estado del sistema local, el conjunto de replicación, el volumen y la conexión entre
pares. La causa puede ser un pool de almacenamiento lleno.
○ Verifique el estado y la condición del sistema de conexión entre pares.
○ Asegúrese de no haber superado el límite máximo de instantáneas a las que se puede agregar
licencia (que se muestra en el comando show license de la CLI).
605 Aviso Núcleo de procesamiento inactivo.
El módulo de controladora tiene varios núcleos de procesamiento. El sistema tiene suficientes núcleos
activos para funcionar, pero se degrada el rendimiento.
Acciones recomendadas:
● Intente reiniciar todos los núcleos de procesamiento como se indica a continuación:
○ Apague el módulo de controladora que registró este evento.
○ Quite el módulo de controladora, espere 30 segundos y vuelva a insertarlo.
● Si este evento se vuelve a registrar, comuníquese con el soporte técnico.
606 Error Una controladora contiene datos de caché no escritos para un volumen, y la carga del supercapacitor
falló.
Debido a la falla del supercapacitor, si la controladora pierde alimentación, no tendrá alimentación de
respaldo para vaciar los datos no escritos de la caché a CompactFlash.
Acciones recomendadas:
● Verifique que la política de escritura en caché sea de escritura simultánea para todos los volúmenes.
Eventos y mensajes de evento 147

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● Comuníquese con el soporte técnico para obtener información sobre cómo reemplazar el módulo de
controladora.
607 Aviso La controladora local está reiniciando la otra controladora.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
608 Error Se detectó un error de cableado de back-end.
Acciones recomendadas:
● Si el mensaje dice que ambas controladoras están conectadas con un tipo de error indefinido, uno de
los cables está conectado de manera incorrecta a otro puerto de egreso de la controladora,
formando un loop en la topología de SAS. Verifique el cableado de back-end de cada puerto de
egreso de la controladora para determinar la conexión incorrecta.
● Si el mensaje dice que los puertos de egreso de la controladora están conectados entre sí, hay uno
de los cables conectado incorrectamente a un puerto de egreso de la controladora, formando un
loop en la topología de SAS. Verifique el cableado de back-end y asegúrese de que los cables de SAS
estén conectados a los puertos correctos para el puerto especificado.
●
Si el mensaje dice que se creó un loop de EBOD, uno de los cables está conectado incorrectamente
a un puerto de egreso de gabinete de expansión, formando un loop en la topología de SAS. Verifique
el cableado de back-end y asegúrese de que los cables de SAS estén conectados a los puertos
adecuados para el puerto especificado.
● Si el mensaje dice que hay un cable conectado al puerto intermedio pero ese puerto no es
compatible, verifique el cableado de back-end y asegúrese de que los cables de SAS estén
conectados a los puertos adecuados para el puerto especificado. Mueva el cable desde el puerto
intermedio del IOM al puerto izquierdo o derecho, según corresponda.
609 Error Se detectó una condición de alerta en un elemento de cerradura de puerta. El elemento informa un
estado asociado con el cajón del gabinete. Se informa que el cajón ha estado abierto durante un largo
período de tiempo. Esto puede reducir el enfriamiento y causar que se sobrecaliente el gabinete.
Acciones recomendadas:
● Verifique que el cajón esté completamente cerrado y tenga los pestillos ajustados.
Cuando se resuelva el problema, se registrará un evento con el mismo código y gravedad Resuelta.
Información Se detectó una condición de alerta en un elemento de cerradura de puerta. El elemento informa un
estado asociado con el cajón del gabinete. Se informa que el sensor del cajón no está instalado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Resuelta Se resolvió una condición Informativa o de Error anterior para el elemento de cerradura de puerta.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
610 Error Se detectó una condición de alerta en un elemento de sideplane.
Acciones recomendadas:
● Verifique que el sideplane indicado del cajón esté completamente cerrado y tenga los pestillos
ajustados.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en
caliente y no los puede reparar el cliente.
● Si esto no resuelve el problema, comuníquese con el soporte técnico. Deberá reemplazar el gabinete.
Aviso Se detectó una condición de alerta en un elemento de sideplane.
Acciones recomendadas:
● El sideplane asociado con el cajón debe estar instalado. Comuníquese con el soporte técnico.
PRECAUCIÓN: Los sideplanes de los cajones del gabinete no son intercambiables en
caliente y no los puede reparar el cliente.
148 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
Resuelta Se resolvió una condición de Advertencia o Error anterior para el elemento de sideplane.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
611 Error La notificación por correo electrónico falló debido a una de las siguientes opciones:
● Un servidor de SMTP inalcanzable o una diferencia entre los dominios de servidor de SMTP y del
remitente.
● Configuración incorrecta.
Acciones recomendadas:
● Verifique los parámetros configurados y solicite a los recipientes que confirmen la recepción del
mensaje.
Información La notificación por correo electrónico se envió correctamente. Solicite a los recipientes que confirmen la
recepción del mensaje.
Acciones recomendadas:
● Verifique los parámetros configurados y solicite a los recipientes que confirmen la recepción del
mensaje.
612 Información Se detectó una condición de alerta en un conector de SAS del chasis interno.
El mensaje de evento especifica la ubicación del conector de SAS interno en el chasis.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
613 Error Se detectó una condición de alerta en un IOM.
Acciones recomendadas:
● Instale el IOM indicado o intente volver a colocarlo.
● Si el problema persiste, reemplace el IOM.
Aviso Se detectó una condición de alerta en un IOM.
Acciones recomendadas:
● Si está desinstalado, instale el IOM indicado; de lo contrario, intente volver a colocarlo.
● Si el problema persiste, reemplace el IOM.
Información Se desinstaló un IOM.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Resuelta Se resolvió una condición de Advertencia o Error anterior para el IOM.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
615 Información Se inició una operación para reequilibrar un grupo de discos ADAPT.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
616 Aviso Se completó parcialmente una operación para reequilibrar un grupo de discos ADAPT.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Información Se completó una operación para reequilibrar un grupo de discos ADAPT.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
Eventos y mensajes de evento 149

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
617 Aviso No se alcanzó el objetivo de capacidad de repuesto.
Este evento indica que el espacio disponible del sistema no es suficiente para proporcionar el nivel de
tolerancia a fallas total especificado por la capacidad de repuesto de destino. La disponibilidad de
capacidad de destino puede verse afectada por operaciones que requieren espacio disponible en el
sistema, como la reconstrucción de datos a partir de un disco fallido.
Acciones recomendadas:
● Agregue discos al grupo o reemplace cualquier disco que pueda haber fallado. El sistema aumentará
la capacidad de repuesto automáticamente para alcanzar los requisitos definidos en el sistema por la
capacidad de repuesto de destino.
618 Resuelta Se alcanzó el objetivo de capacidad de repuesto.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
619 Información Se inyectó una falla en la controladora para introducir un error de vínculo de receptor de transmisión
(BR).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
620 Error La agrupación por zonas del dispositivo expansor está habilitada, lo que podría limitar el acceso al disco.
El acceso al disco cambiará según el puerto usado para conectarse al expansor.
Acciones recomendadas:
● Cargue un paquete de firmware válido para deshabilitar la agrupación por zonas.
Resuelta Se deshabilitó la agrupación por zonas del expansor para el gabinete indicado.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
621 Información Se inició la operación de rebalanceo de ADAPT degradados. Esta operación toma zonas de franjas
tolerantes a fallas y las convierte en zonas degradadas, de modo que las zonas de franjas críticas se
pueden degradar.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
622 Información Se completó la operación de rebalanceo de ADAPT degradados. Esta operación toma zonas de franjas
tolerantes a fallas y las convierte en zonas degradadas, de modo que las zonas de franjas críticas se
pueden degradar.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
623 Información Se establecieron los parámetros de configuración de la controladora de administración.
Se cambiaron uno o más parámetros de configuración asociados con la controladora de administración
(MC), como la configuración para SNMP, SMI-S (no compatible con ME4084), la notificación por
correo electrónico y las cadenas del sistema (nombre del sistema, ubicación del sistema, etc.).
Acciones recomendadas:
● No es necesario realizar ninguna acción.
624 Aviso Se modificaron los datos del ensamblaje de nivel superior.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
625 Aviso Se cambió la marca del sistema.
Acciones recomendadas:
150 Eventos y mensajes de evento

Tabla 27. Descripciones de eventos y acciones recomendadas (continuación)
Número Gravedad Descripción/acciones recomendadas
● No es necesario realizar ninguna acción.
626 Información Se detectó un TPID (ID de tipo midplane) no compatible.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
627 Información Se detectó un TPID (ID de tipo midplane) desconocido.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
628 Error Se identificó una discordancia de firmware para el gabinete de expansión.
Podría provocarse una incompatibilidad de firmware al conectar un gabinete configurado como un JBOD
(en lugar de un EBOD) o al instalar una nueva FRU del IOM con firmware incompatible.
Acciones recomendadas:
● Actualice el firmware al nivel correspondiente para conectar sus gabinetes de expansión al gabinete
de la controladora.
● Si recibe este evento cuando no se agregaron gabinetes ni IOM nuevos, póngase en contacto con el
servicio de soporte.
646 Información Indica cualquiera de los siguientes cambios en SupportAssist:
● Estado modificado
● Información de contacto modificada
● Configuración de proxy modificada o borrada
● Modo de funcionamiento modificado
● Configuración modificada
Acciones recomendadas:
● No es necesario realizar ninguna acción.
647 Error Esta controladora de almacenamiento se reinicia debido a un error interno.
Esta controladora de almacenamiento experimentó un bloqueo en la interfaz de administración y se
reiniciará para la recuperación.
Acciones recomendadas:
● Recopile los registros y póngase en contacto con el soporte técnico para continuar.
648 Error No se pudo cargar registros de SupportAssist, configuración de CloudIQ o datos de rendimiento.
Acciones recomendadas:
● No es necesario realizar ninguna acción.
649 Aviso Hay una actualización de firmware de la controladora disponible para el sistema.
Acciones recomendadas:
● Acceda a https://www.dell.com/support, ingrese la etiqueta de servicio y descargue la
actualización. A continuación, puede usar la función Actualizar firmware en el PowerVault Manager
para realizar la actualización.
650 Aviso Hay una actualización de firmware de disco disponible para el sistema.
Acciones recomendadas:
● Acceda a https://www.dell.com/support, ingrese la etiqueta de servicio y descargue la
actualización. A continuación, puede usar la función Actualizar firmware en el PowerVault Manager
para realizar la actualización.
Eventos y mensajes de evento 151

Eventos eliminados
En la siguiente tabla, se enumeran los eventos eliminados y se especifican los eventos que el sistema informa en su lugar:
NOTA: Si tiene scripts que hagan referencia a los eventos eliminados, actualice los scripts con los eventos de reemplazo.
Tabla 28. Eventos eliminados
Evento eliminado Evento de reemplazo
154 237
155 237
Eventos enviados como indicaciones a clientes de SMI-
S
Si la interfaz de SMI-S del sistema de almacenamiento está habilitada, el sistema enviará eventos como indicaciones a los clientes de SMI-
S, para que estos puedan monitorear el rendimiento del sistema.
Las siguientes categorías de eventos corresponden a ensamblajes de FRU y ciertos componentes de FRU:
Tabla 29. Categorías de eventos de FRU
Categoría de
evento/FRU
Clase de SMI-S correspondiente Valores de estado de funcionamiento que desencadenarían
condiciones de alerta
Controladora
DHS_Controller Down, Not Installed, OK
Unidad de disco duro
DHS_DiskDrive Unknown, Missing, Error, Degraded, OK
Ventilador
DHS_PSUFan Error, Stopped, OK
Fuente de
alimentación
DHS_PSU Unknown, Error, Other, Stressed, Degraded, OK
Sensor de
temperatura
DHS_OverallTempSensor Unknown, Error, Other, Non-Recoverable Error,
Degraded, OK
Batería/SuperCap
DHS_SuperCap Unknown, Error, OK
Puerto de FC
DHS_FCPort Stopped, OK
Puerto de SAS
DHS_SASTargetPort Stopped, OK
Puerto de iSCSI
DHS_ISCSIEthernetPort Stopped, OK
Uso del comando de confianza
Utilice el comando de la CLI trust solo como último paso en una situación de recuperación ante desastres.
No utilice el comando trust si un grupo de discos con un solo disco se encuentra en condición sobrante o fallida. El comando trust
puede causar una pérdida de datos permanente y un funcionamiento inestable del grupo de discos. Utilice el comando trust únicamente
si el grupo de discos está en estado offline.
Un disco fallado o en estado sobrante debido a varios errores se debe reemplazar por un disco nuevo. Vuelva a asignar el nuevo disco al
grupo de discos como repuesto. Luego, permita que se complete la reconstrucción para que el grupo de discos regrese completamente a
un estado de tolerancia a errores.
El comando trust intenta resincronizar los discos sobrantes para hacer que cualquier disco sobrante sea un miembro activo del grupo de
discos. El comando trust puede ser necesario cuando un grupo de discos está offline debido a que no hay un respaldo de datos. El
comando trust también puede ser necesario como último intento de recuperar los datos en un grupo de discos. En este caso, el
comando trust puede funcionar, pero solo si el disco sobrante continúa funcionando. Cuando el grupo de discos "confiable" vuelve a
estar en línea, respalde todos los datos en el grupo de discos y verifique todos los datos para asegurarse de que sean válidos. A
152
Eventos y mensajes de evento

continuación, elimine el grupo de discos de confianza, agregue un nuevo grupo de discos y restaure los datos del respaldo al nuevo grupo
de discos.
PRECAUCIÓN: Usar trust en un grupo de discos es solo una medida de recuperación ante desastres. El grupo de discos
no tiene tolerancia para otra falla y nunca se debe volver a colocar en un entorno de producción. Antes de confiar en un
grupo de discos, lea atentamente las precauciones y los procedimientos para usar el comando de confianza en la
Guía de
referencia de la CLI del sistema de almacenamiento de Dell EMC PowerVault ME4 Series
y la ayuda en línea. Si no está
seguro de si desea usar este comando, comuníquese con el soporte técnico para obtener asistencia.
Una vez que se emite el comando trust en un grupo de discos, los demás pasos de solución de problemas pueden estar limitados hacia la
recuperación ante desastres. Si no está seguro de la acción adecuada, comuníquese con el soporte técnico para obtener asistencia
adicional.
Eventos y mensajes de evento 153

Conexión del puerto de la CLI mediante un
cable en serie
Puede acceder a la CLI mediante el conector estéreo de 3,5 mm o el puerto USB de la CLI y el software de emulación de terminales.
1. Conecte el cable en serie de 3,5 mm/DB9 desde una computadora con un puerto serial al puerto de la CLI del conector estéreo de
3,5 mm en la controladora A. De manera alternativa, conecte un cable genérico miniUSB (no incluido) desde una computadora al
puerto USB de la CLI en la controladora A.
El conector miniUSB se conecta en el puerto USB de la CLI, como se muestra en la siguiente ilustración:
Ilustración 64. Conexión de un cable USB al puerto USB de la CLI
2. Si está utilizando un cable miniUSB, habilite el puerto USB de la CLI para la comunicación:
NOTA: Omita este paso si utiliza el cable serie de 3,5 mm/DB9.
● A menos que utilice Windows 10 o Windows Server 2016 y versiones posteriores, descargue e instale el controlador USB del
dispositivo para el puerto de la CLI, como se describe en Controladores de Microsoft Windows en la página 156.
● En una computadora con Linux, ingrese la sintaxis del comando que se proporciona en Controladores de Linux en la página 156.
3. Inicie un emulador de terminal y configure los ajustes de visualización que se muestran en Configuración de la pantalla del emulador de
terminal en la página 154, y la configuración de conexión que se muestra en Configuración de la conexión del emulador de terminal en
la página 154.
Tabla 30. Configuración de la pantalla del emulador de terminal
Parámetro Valor
Modo de emulación de terminales VT-100 o ANSI (para compatibilidad de color)
Fuente Terminal
Traducciones Ninguno
Columnas 80
Tabla 31. Configuración de la conexión del emulador de terminal
Parámetro Valor
Conector COM3 (por ejemplo)
1, 2
A
154 Conexión del puerto de la CLI mediante un cable en serie

Tabla 31. Configuración de la conexión del emulador de terminal (continuación)
Parámetro Valor
Velocidad en baudios 115 200
Bits de datos 8
Paridad Ninguno
Bits de parada 1
Control de flujo Ninguno
1
La configuración de la computadora determina qué puerto de COM se utiliza para el puerto USB de arreglo de discos.
2
Verifique el puerto de COM adecuado para usar con la CLI.
4. Si es necesario, presione Entrar para mostrar la petición de inicio de sesión.
a. Escriba el nombre de un usuario con función de administrador en la petición de inicio de sesión y presione Entrar.
b. Escriba la contraseña del usuario en la petición de Contraseña y presione Entrar.
Temas:
• Conexión del minidispositivo USB
Conexión del minidispositivo USB
En las siguientes secciones, se describe la conexión al puerto miniUSB:
Puerto serial emulado
Cuando una computadora se conecta a un módulo de controladora mediante un cable en serie miniUSB, la controladora presenta un
puerto serial emulado a la computadora. El nombre del puerto serial emulado se muestra mediante una ID de proveedor de cliente y una ID
de producto. No es necesario configurar el puerto serial.
NOTA:
Ciertos sistemas operativos requieren un controlador de dispositivo o un modo especial de funcionamiento para habilitar el
funcionamiento adecuado del puerto USB de la CLI. Consulte también Controlador de dispositivo/modo especial de funcionamiento en
la página 156.
Aplicaciones de host compatibles
Las siguientes aplicaciones del emulador de terminal se pueden utilizar para comunicarse con un módulo de controladora de ME4 Series:
Tabla 32. Aplicaciones de emulador de terminal compatibles
Aplicación Sistema operativo
PuTTY Microsoft Windows (todas las versiones)
Minicom Linux (todas las versiones)
Interfaz de línea de comandos
Cuando la computadora detecta una conexión al puerto serial emulado, la controladora espera la entrada de caracteres de la computadora
mediante la interfaz de línea de comandos. Para ver la petición de la CLI, debe presionar Entrar.
NOTA:
El cableado directo al puerto miniUSB se considera una conexión fuera de banda. La conexión al puerto miniUSB se encuentra
fuera de las rutas de datos normales al gabinete de la controladora.
Conexión del puerto de la CLI mediante un cable en serie 155

Controlador de dispositivo/modo especial de funcionamiento
Determinados sistemas operativos requieren un controlador de dispositivo o un modo especial de funcionamiento. En la siguiente tabla, se
muestra la información de identificación del producto y del proveedor necesaria para determinados sistemas operativos:
Tabla 33. Código de identificación USB
Tipo de código de identificación de USB Código
ID del proveedor de USB 0x210c
ID del producto de USB 0xa4a7
Controladores de Microsoft Windows
Dell EMC proporciona un controlador USB de ME4 Series para su uso en ambientes Windows.
Obtención del controlador USB
NOTA: Si está utilizando Windows 10 o Windows Server 2016, el sistema operativo proporciona un controlador en serie USB nativo
compatible con el puerto miniUSB. Sin embargo, si está utilizando una versión anterior de Windows, debe descargar e instalar el
controlador USB.
1. Acceda a Dell.com/support y busque ME4 Series USB driver.
2. Descargue el archivo ME4 Series Storage Array USB Utility desde el sitio de soporte de Dell EMC .
3. Siga las instrucciones en la página de descarga para instalar el controlador USB de ME4 Series.
Problemas conocidos con el cable miniUSB y el puerto de la CLI en Microsoft
Windows
Cuando utilice el puerto de la CLI y el cable para configurar direcciones IP de puertos de red, tenga en cuenta los siguientes problemas
comunes en Windows:
Problema
Es posible que la computadora encuentre problemas que impiden que el software del emulador de terminal se vuelva a conectar después
de reiniciar el módulo de controladora o de desconectar y volver a conectar el cable USB.
Solución alternativa
Para restaurar una conexión que dejó de responder cuando se reinició el módulo de controladora, realice lo siguiente:
1. Si la conexión con el puerto miniUSB deja de responder, desconecte y salga del programa de emulación de terminal.
a. Mediante el administrador de dispositivos, busque el puerto de COMn asignado al puerto miniUSB.
b. Haga clic con el botón secundario en el puerto Puerto USB del arreglo de discos (COM
n
) y seleccione Deshabilitar
dispositivo.
2. Haga clic con el botón secundario en el puerto Puerto USB del arreglo de discos (COM
n
) y seleccione Habilitar dispositivo.
3. Inicie el software del emulador de terminal y conéctese al puerto de COM.
NOTA:
En Windows 10 o Windows Server 2016, la configuración de XON/XOFF en el software de emulador de terminal debe estar
deshabilitada para utilizar el puerto de COM.
Controladores de Linux
Los sistemas operativos de Linux no requieren la instalación de un controlador de USB de ME4 Series. Sin embargo, se deben proporcionar
determinados parámetros durante la carga del controlador para permitir el reconocimiento del puerto miniUSB en un módulo de
controladora de ME4 Series.
156
Conexión del puerto de la CLI mediante un cable en serie

● Escriba el siguiente comando para cargar el controlador de dispositivo de Linux con los parámetros necesarios para reconocer el puerto
miniUSB:
# modprobe usbserial vendor=0x210c product=0xa4a7 use_acm=1
NOTA: De manera opcional, esta información se puede incorporar en el archivo /etc/modules.conf.
Conexión del puerto de la CLI mediante un cable en serie 157

Especificaciones técnicas
Dimensiones del gabinete
Tabla 34. Dimensiones del gabinete de 2U
Especificación mm pulgadas
Altura general del gabinete (2U) 87,9 mm 3,46 in
Ancho hasta la brida de montaje (que se encuentran
en la parte frontal del chasis)
483 mm 19,01 in
Ancho hasta el cuerpo del gabinete 443 mm 17,44 in
2U12: profundidad desde la parte frontal de la brida de
montaje hasta la parte posterior del cuerpo del
gabinete
576,8 mm 22,71 in
2U24: profundidad desde la parte frontal de la brida de
montaje hasta la parte posterior del cuerpo del
gabinete
526 mm 20,71 pulgadas
2U12: profundidad desde la parte frontal de la brida de
montaje hasta la extremidad más cercana a la parte
posterior del gabinete
602,9 mm 23,74 in
2U24: profundidad desde la parte frontal de la brida de
montaje hasta la extremidad más cercana a la parte
posterior del gabinete
552,2 mm 21,74 pulgadas
2U12: profundidad desde la parte frontal del panel del
operador hasta la extremidad más cercana a la parte
posterior del gabinete
629,6 mm 24,79 in
2U24: profundidad desde la parte frontal del panel del
operador hasta la extremidad más cercana a la parte
posterior del gabinete
578,9 mm 22,79 pulgadas
NOTA:
● El gabinete 2U24 utiliza discos SFF de 2,5 pulgadas.
● El gabinete 2U12 utiliza discos LFF de 3,5 pulgadas.
Tabla 35. Dimensiones del gabinete 5U84
Especificación mm pulgadas
Altura general del gabinete (2U) 222,3 mm 3,46 in
Ancho hasta la brida de montaje (que se encuentran en
la parte frontal del chasis)
483 mm 19,01 in
Ancho hasta el cuerpo del gabinete 443 mm 17,44 in
Profundidad desde la parte frontal de la brida de
montaje hasta la parte posterior del cuerpo del
gabinete
892,2 mm 35,12 in
B
158 Especificaciones técnicas

Tabla 35. Dimensiones del gabinete 5U84 (continuación)
Especificación mm pulgadas
Profundidad desde la parte frontal de la brida de
montaje hasta la mayor extremidad posterior del
gabinete
974,7 mm 38,31 in
Profundidad desde la parte frontal del panel de
operaciones hasta la mayor extremidad posterior del
gabinete
981 mm 38,62 in
NOTA: El 5U84 utiliza discos LFF de 3,5 pulgadas en el portaunidades de DDIC. También puede utilizar discos SFF de 2,5 pulgadas
con un adaptador de 3,5 pulgadas en la DDIC.
Pesos del gabinete
Tabla 36. pesos de los gabinetes 2U12, 2U24 y 5U84
CRU/componente 2U12 (kg/lb) 2U24 (kg/lb) 5U84 (kg/lb)
Gabinete de almacenamiento (vacío) 4,8/10,56 4,8/10,56 64/141
Portaunidades de disco 0,9/1,98 0,3/0,66 0,8/1,8
Portaunidades de disco vacío (soporte de
control del aire)
0,05/0,11 0,05/0,11 —
Módulo de enfriamiento de alimentación
(PCM)
3,5/7,7 3,5/7,7 —
Fuente de alimentación (PSU) — — 2,7/6
Módulo de enfriamiento con ventilador
(FCM)
— — 1,4/3
Módulo de la controladora SBB (peso
máximo)
2,6/5,8 2,6/5,8 2,6/5,8
Módulo de expansión SBB 1,5/3,3 1,5/3,3 1,5/3,3
Gabinete RBOD (totalmente ocupado con
módulos: peso máximo)
32/71 30/66 135/298
Gabinete EBOD (totalmente ocupado con
módulos: peso máximo)
28/62 25/55 130/287
NOTA:
● Los pesos que se muestran son nominales y están sujetos a las variaciones.
● Los kits de rieles 2U agregan entre 2.8 kg (6.2 lb) y 3.4 kg (7.4 lb) al peso del gabinete agregado. Los kits de rieles 5U84 agregan
aún más peso.
● El peso puede variar debido a diferentes módulos de controladora, IOM y fuentes de alimentación, y las diferentes calibraciones
entre las escalas.
El peso también puede variar debido a la cantidad real y el tipo de unidades de disco (SAS o SSD) y los módulos de administración
de aire instalados.
Especificaciones técnicas 159

Requisitos del entorno
Tabla 37. Temperatura ambiente y humedad
Especificación Intervalo de temperatura Humedad relativa Bombilla húmeda máx.
En funcionamiento
● RBOD: de 5 °C a 35 °C
(de 41 °F a 95 °F)
● EBOD: de 5 °C a 40 °C
(de 41 °F a 104 °F)
Entre 20% y 80% sin
condensación
28 °C
Sin funcionamiento (envío) De -40 °C a +70 °C (de -40
°F a +158 °F)
5% a 100% sin precipitación 29 °C
Tabla 38. Requisitos ambientales adicionales
Especificación Medición/descripción
Flujo de aire
● El sistema debe utilizarse con la instalación de escape posterior de baja presión.
● Presión posterior creada por las puertas y los obstáculos del rack que no debe superar
los 5 Pa (0,5 mm H2O)
Altitud, en funcionamiento
● Gabinetes de 2U: de 0 a 3 000 metros (de 0 a 10 000 pies)
● La temperatura máxima de funcionamiento se reduce 5 °C por encima de los 2 133
metros (7 000 pies)
● Gabinetes 5U84: de -100 metros a 3 000 metros (de -330 pies a 10 000 pies)
● La temperatura máxima de funcionamiento se reduce 1 °C por encima de los
900 metros (3 000 pies)
Altitud, sin funcionamiento De -100 metros a 12 192 metros (de -330 pies a 40 000 pies)
Descargas eléctricas, en funcionamiento 5,0 g, 10 ms, ½ pulsos sinusoidales, eje Y
Descargas eléctricas, sin funcionamiento Gabinetes de 2U: 30,0 g, 10 ms, ½ pulsos sinusoidales
Gabinetes 5U84: 30,0 g, 10 ms, ½ pulsos sinusoidales (eje Z); 20,0 g, 10 ms, ½ pulsos
sinusoidales
Vibración, en funcionamiento 0,21 Grms, de 5 Hz a 500 Hz aleatorio
Vibración, sin funcionamiento 1,04 Grms, de 2 Hz a 200 Hz aleatorio
Vibración, reubicación 0,3 Grms, de 2 Hz a 200 Hz 0,4 décadas por minuto
Acústica Potencia acústica en funcionamiento
● Gabinetes de 2U: ≤ LWAd de 6,6 belios (re 1 pW) a 23 ºC
● Gabinetes de 5U84: ≤ LWAd de 8 belios (re 1 pW) a 23 ºC
Orientación y montaje: Montaje en rack 19 pulgadas (2 unidades EIA; 5 unidades EIA)
Rieles del rack Para adaptar los racks de 800 mm de profundidad que cumplan con la especificación de
rack de servidor SSI
Características del rack Presión posterior que no supere los 5Pa ( ~0,5 mm H20)
Módulo de enfriamiento de alimentación
Las especificaciones del PCM se proporcionan en la tabla siguiente.
Tabla 39. Especificaciones del módulo de enfriamiento de alimentación de 2U
Especificación Medición/descripción
Dimensiones (medida) 84,3 mm de alto x 104,5 mm de ancho x 340,8 mm de largo:
● Longitud del eje X: 104,5 mm (4,11 pulgadas)
160 Especificaciones técnicas

Tabla 39. Especificaciones del módulo de enfriamiento de alimentación de 2U (continuación)
Especificación Medición/descripción
● Longitud del eje Y: 84,3 mm (3,32 pulgadas)
● Longitud del eje Z: 340,8 mm (37,03 pulgadas)
Potencia máxima de salida 580 W
Rango de voltaje De 100 V a 200 V de CA nominales
Frecuencia 50–60 HZ
Selección del rango de voltaje Automedición: de 90 V a 264 V de CA, de 47 Hz a 63 Hz
Corriente de irrupción máxima 20 A
Corrección del factor de energía ≥ 95 % a voltaje de entrada nominal
Eficiencia 115 V de CA/60 Hz 230 V de CA/50 Hz
> 80% al 10% de la carga > 80% al 10% de la carga
> 87% al 20% de la carga > 88% al 20% de la carga
> 90% al 50% de la carga > 92% al 50% de la carga
> 87% al 100% de la carga > 88% al 100% de la carga
> 85% de sobretensión > 85% de sobretensión
Vibraciones armónicas Cumple la norma EN61000-3-2
Salida +5 V a 42 A, +12 V a 38 A, +5 V de voltaje en espera a 2,7 A
Temperatura en funcionamiento De 0 °C a 57 °C (de 32 °F a +135 °F)
Conectable en caliente Sí
Conmutadores y LED Interruptor de red de CA y cuatro indicadores LED de estado
Enfriamiento del gabinete Ventiladores axiales dobles de enfriamiento con control de velocidad variable
Fuente de alimentación
Tabla 40. Especificaciones de la fuente de alimentación de 5U84
Especificación Medición/descripción
Potencia máxima de salida Potencia máxima de salida continua de 2 214 en alto voltaje
Voltaje
● +12 V en 183 A (2 196 W)
● +5 V voltaje en espera en 2,7 A
Rango de voltaje De 200 V a 240 V de CA
Frecuencia 50–60 HZ
Corrección del factor de energía ≥ 95 % al 100 % de carga
Eficiencia
● 82% al 10% de la carga
● 90% al 20% de la carga
● 94% al 50% de la carga
● 91% al 100% de la carga
Tiempo de retención 5 ms desde ACOKn alto hasta los rieles fuera de reglamentación (consulte la
especificación SBB v2)
Conector de entrada principal IEC60320 C20 con retención de cables
Peso 3 kg (6,6 lb)
Especificaciones técnicas 161

Tabla 40. Especificaciones de la fuente de alimentación de 5U84 (continuación)
Especificación Medición/descripción
Ventiladores de enfriamiento Dos ventiladores apilados: 80 m x 80 m x 38 mm (3,1 pulgadas. x 3,15 pulgadas. x
1,45 pulgadas)
162 Especificaciones técnicas

Estándares y normativas
Posibilidad de interferencia de radiofrecuencia.
Comisión Federal de Comunicaciones (FCC) de EE. UU.
NOTA: Este equipo ha sido probado y cumple con los límites establecidos para los dispositivos digitales de Clase A, de conformidad
con lo dispuesto en el Apartado 15 de la normativa de la FCC. Estos límites están diseñados para proporcionar una protección
razonable contra interferencias perjudiciales cuando se utiliza el equipo en un entorno comercial. Este equipo genera, utiliza y puede
emitir energía por radiofrecuencia y, si no se instala y utiliza de acuerdo con el manual de instrucciones del fabricante, puede provocar
interferencias perjudiciales en las radiocomunicaciones. El funcionamiento de este equipo en un área residencial puede llegar a
provocar interferencias perjudiciales, en cuyo caso se le pedirá que las corrija y que se haga cargo del gasto generado.
Deben usarse cables y conectores protegidos y conectados a tierra de manera adecuada a fin de cumplir con los límites de emisión de la
FCC. El proveedor no es responsable de las interferencias de radio o televisión ocasionadas por el uso de otros cables y conectores que no
sean los recomendados o por cambios o modificaciones no autorizados que se hayan realizado en este equipo. Los cambios o las
modificaciones no autorizados podrían anular la autoridad del usuario de usar el equipo.
Este equipo cumple con el apartado 15 de la normativa de la FCC. El funcionamiento se encuentra sujeto a las dos condiciones siguientes:
(1) este dispositivo no puede causar interferencias perjudiciales, y (2) este dispositivo debe aceptar cualquier interferencia recibida,
incluidas las interferencias que pudieran causar un funcionamiento no deseado.
Normativas europeas
Este equipo cumple con las normativas europeas EN 55022 Clase A: Límites y métodos de medición de características de interferencias de
radio de los equipos de tecnología de la información y EN50082-1: Inmunidad genérica.
Cumplimiento de normas de seguridad
Tabla 41. Estándares de cumplimiento de normas de seguridad
Aprobación del tipo de
producto del sistema
Estándar
Cumplimiento de normas de
seguridad
UL 60950-1
UL 62368-1
IEC 60950-1
IEC 62368-1
EN 60950-1
EN 62368-1
C
Estándares y normativas 163

Cumplimiento de compatibilidad electromagnética (EMC)
Tabla 42. Estándares de cumplimiento de normas de EMC
Aprobación del tipo de
producto del sistema
Estándares
Niveles límite de emisiones
conducidas
CFR47 Apartado 15B Clase A
EN 55032
Clase A de la CISPR
Niveles límite de emisión
irradiada
CFR47 Apartado 15B Clase A
EN 55032
Clase A de la CISPR
Vibraciones armónicas y
parpadeo
EN 61000-3-2/3
Niveles de límite de inmunidad EN 55024
Especificaciones del cable de alimentación de CA
Tabla 43. Estados Unidos de América: debe estar listado por un NRTL (laboratorio de pruebas reconocido
nacionalmente, por ejemplo, UL):
Factor de forma del chasis 2U12/2U24 5U84
Tipo de cable SV o SVT, 18 AWG como mínimo,
3 conductores, 2,0 m de longitud máxima
SJT o SVT, 12 AWG mínimo, 3 conductores
Enchufe (fuente de CA)
● NEMA 5: conector de tipo conexión a tierra
15P, con clasificación de 120 V, 10 A
● IEC 320, C14, 250 V, 10 A
● IEC 320, C20, 250 V, 20 A
● Un enchufe adecuado con valor nominal de
250 V, 20 A
Conector IEC 320, C13, 250 V, 10 A IEC 320, C19, 250 V, 20 A
Tabla 44. Europa y otros: requisitos generales;
Factor de forma del chasis 2U12/2U24 5U84
Tipo de cable HAR, H05VV-F-3G1.0 HAR, H05VV-F-3G2.5
Enchufe (fuente de CA)
● IEC 320, C14, 250 V, 10 A
● Un enchufe adecuado con valor nominal de
250 V, 16A
● IEC 320, C20, 250 V, 16 A
● Un enchufe adecuado con valor nominal de
250 V, 16A
Conector IEC 320, C13, 250 V, 10 A IEC 320, C19, 250 V, 16 A
NOTA: El enchufe y el ensamblaje completo del cable de alimentación deben cumplir con los estándares apropiados para el país, y
deben tener aprobaciones de seguridad aceptables en ese país.
Reciclaje de residuos eléctricos y equipos electrónicos
(WEEE)
Una vez que finalice la vida útil del producto, todos los equipos eléctricos y electrónicos de desecho o en desuso deben reciclarse de
conformidad con las normativas nacionales vigentes con respecto a la manipulación de materiales de residuos eléctricos y electrónicos
peligrosos o tóxicos.
Comuníquese con su proveedor para obtener una copia de los procedimientos de reciclaje vigentes en su país.
164
Estándares y normativas

NOTA: Tenga en cuenta todas las precauciones de seguridad vigentes que se detallan en los capítulos anteriores (las restricciones de
peso, manejo de baterías y láser, etc.) cuando desarme y deseche este equipo.
Estándares y normativas 165
-
 1
1
-
 2
2
-
 3
3
-
 4
4
-
 5
5
-
 6
6
-
 7
7
-
 8
8
-
 9
9
-
 10
10
-
 11
11
-
 12
12
-
 13
13
-
 14
14
-
 15
15
-
 16
16
-
 17
17
-
 18
18
-
 19
19
-
 20
20
-
 21
21
-
 22
22
-
 23
23
-
 24
24
-
 25
25
-
 26
26
-
 27
27
-
 28
28
-
 29
29
-
 30
30
-
 31
31
-
 32
32
-
 33
33
-
 34
34
-
 35
35
-
 36
36
-
 37
37
-
 38
38
-
 39
39
-
 40
40
-
 41
41
-
 42
42
-
 43
43
-
 44
44
-
 45
45
-
 46
46
-
 47
47
-
 48
48
-
 49
49
-
 50
50
-
 51
51
-
 52
52
-
 53
53
-
 54
54
-
 55
55
-
 56
56
-
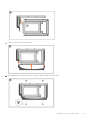 57
57
-
 58
58
-
 59
59
-
 60
60
-
 61
61
-
 62
62
-
 63
63
-
 64
64
-
 65
65
-
 66
66
-
 67
67
-
 68
68
-
 69
69
-
 70
70
-
 71
71
-
 72
72
-
 73
73
-
 74
74
-
 75
75
-
 76
76
-
 77
77
-
 78
78
-
 79
79
-
 80
80
-
 81
81
-
 82
82
-
 83
83
-
 84
84
-
 85
85
-
 86
86
-
 87
87
-
 88
88
-
 89
89
-
 90
90
-
 91
91
-
 92
92
-
 93
93
-
 94
94
-
 95
95
-
 96
96
-
 97
97
-
 98
98
-
 99
99
-
 100
100
-
 101
101
-
 102
102
-
 103
103
-
 104
104
-
 105
105
-
 106
106
-
 107
107
-
 108
108
-
 109
109
-
 110
110
-
 111
111
-
 112
112
-
 113
113
-
 114
114
-
 115
115
-
 116
116
-
 117
117
-
 118
118
-
 119
119
-
 120
120
-
 121
121
-
 122
122
-
 123
123
-
 124
124
-
 125
125
-
 126
126
-
 127
127
-
 128
128
-
 129
129
-
 130
130
-
 131
131
-
 132
132
-
 133
133
-
 134
134
-
 135
135
-
 136
136
-
 137
137
-
 138
138
-
 139
139
-
 140
140
-
 141
141
-
 142
142
-
 143
143
-
 144
144
-
 145
145
-
 146
146
-
 147
147
-
 148
148
-
 149
149
-
 150
150
-
 151
151
-
 152
152
-
 153
153
-
 154
154
-
 155
155
-
 156
156
-
 157
157
-
 158
158
-
 159
159
-
 160
160
-
 161
161
-
 162
162
-
 163
163
-
 164
164
-
 165
165





































































































































































Dell EMC PowerVault ME412 Expansion El manual del propietario
- Tipo
- El manual del propietario
- Este manual también es adecuado para
Artículos relacionados
-
Dell EMC PowerVault ME4024 El manual del propietario
-
Dell EMC PowerVault ME412 Expansion Guía del usuario
-
-
Dell PowerVault MD3800f El manual del propietario
-
Dell Storage MD1280 El manual del propietario
-
-
-
Dell Storage SCv2080 Guía de inicio rápido
-
-
Dell EMC PowerVault ME484 El manual del propietario